借助亚马逊S3和RapidMiner将机器学习应用到文本挖掘
本挖掘典型地运用了机器学习技术,例如聚类,分类,关联规则,和预测建模。这些技术揭示潜在内容中的意义和关系。文本发掘应用于诸如竞争情报,生命科学,客户呼声,媒体和出版,法律和税收,法律实施,情感分析和趋势识别。
在本篇博客帖中,你将会学习到如何将机器学习技术应用到文本挖掘中。我将会向你展示如何使用RapidMiner(一款流行的预测分析开源工具)和亚马逊S3业务来创建一个文件挖掘应用。亚马逊S3业务是一项易用的存储服务,可使组织在网页上的任何地方存储和检索任意数量的数据。
掘模型产生的结果可以得到持续的推导并应用于解决特定问题
为什么使用文本挖掘技术?
文本挖掘技术帮助你在大量的肉眼不可见的文本内容中隐藏的文本模式和关系,带来了新的商机和进程的改进。使用文本挖掘技术可以节省你的时间和资源,因为文本挖掘进程可以实现自动化,文本挖掘模型产生的结果可以得到持续的推导并应用于解决特定问题。
这些技术可以帮助你:
- 从大量的文本内容中提取关键概念,文本模式和关系。
- 以主题(例如旅行和娱乐)为依据,在文本内容中识别各种趋势,以便理解用户情感。
- 从文档中概括内容,从语义上理解潜在内容。
- 索引和搜索文本以便在预测分析中使用。
正如你所看到的,除了事务性内容外,如果你不分析文本内容,你可能错失重大的机遇.
以前文本挖掘所面临的障碍
在过去,从大量的文本中提取有价值的透彻分析通常很难。提取有价值的透彻分析需要技艺精湛的IT人才来执行复杂的编程和建模任务。另外,在维持性能和创新周期所要求的速度和灵敏度的条件下,所具有的基础设施简直无法满足处理大量非结构化文本的要求。工具与潜在基础设施的集成则是面临的另一个挑战。这通常导致数据和工具从一个环境迁移到另一个环境。此外,商业用户发现很难解读这些结果。易于挖掘和分析的结构化数据变成大多数数据分析任务的主要数据源。结果是大量的文本内容实际上未被使用。
文本分析的新近发展
数据和云基础设施已经取得了巨大的进步。这包括机器学习和文本挖掘领域可用的各种工具和技术。伴随着这些发展,速度,创新和可扩展性现在变成了可能。在组织使用分析学方面也已经出现了根本性的转变:不是应对过去的趋势,组织通过根据当前事件预测未来趋势而变得主动。多亏了AWS提供的各种云基础设施服务和诸如 RapidMiner ,组织不再需要先进的编程技术就可以在可扩展和持久的环境中快速地分析文本内容了。RapidMiner工具综合了机器学习,文本挖掘和可视化能力。
文本挖掘流程
大多数文本挖掘遵循以下的典型流程:
1.识别和提取待分析的文档。应用结构化的,统计的和语言技术(通常是共同应用)来识别,标识和提取各种成分,例如实体,概念和关系。
2.应用统计学的模式匹配和相似性技术来将文档分类并根据特定的分组或分类组织提取出的特征。潜在的非结构化数据转化为易于分析的结构化数据。分类过程帮助识别含义和各种关系。
3.评估模型的性能。
4.向最终用户呈现分析结果。
下面的流程图说明了这一流程。
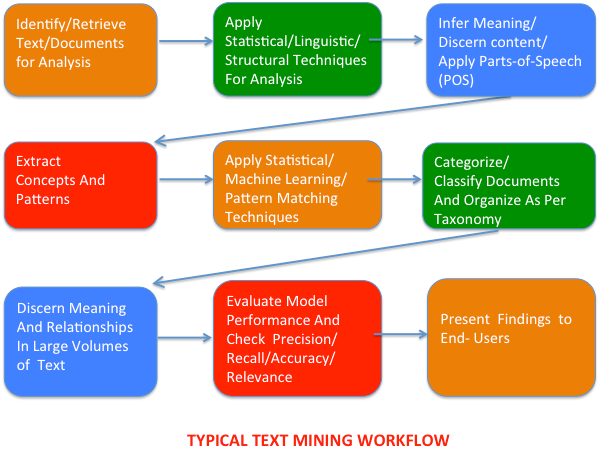
典型的文本挖掘流程图
第一行:识别/提取待分析的文本/文档 应用统计的/语言的/结构化技术来分析 推断含义/识别内容/应用词类分析法
第二行:提取概念和模式 应用统计的/机器学习/模式匹配技术 将文档分类,根据分类学组织文档
第三行:识别文本含义和大量文本中各种关系 评估模型性能,检查查准率/查全率/准确性/相关性
向最终用户呈现分析结果
机器学习在文本挖掘中的作用
典型地,文本挖掘技术根据因子(例如术语频率和分布)的统计分析建立一组重要的单词和句子。根据重要性,得分最高的单词和句子典型地表明潜在的观点,感情或一般主题。
作为过程的一部分,现代工具典型地构建一个文档术语矩阵(DTM),使用加权方法,如词频-逆文档频率法(TF-IDF)。这些工具提取并将潜在信息,如标准特征,关键词频率,文档和文本列表特征,以表格的形式存储在数据库中。可以查询这些表格进行系数分析和处理。这些步骤是将机器学习技术应用到文本内容的前导。
文本分析学典型地运用机器学习技术,如聚类,分类,关联规则和预测建模来识别潜在内容中的含义和各种关系。然后使用各种方法处理非机构化数据源中包含的潜在文本。非结构化数据源包括自然语言处理(NLP),语法分析,标记化(明显成分的识别,如单词和N个字尾),词干提取(将单词变体缩减为词干),术语归约(使用同义词和相似度量的小组类术语)和词类标记。这些数据源帮助识别事实和关系。
文本分析另一个关键的方面涉及组织和构建潜在的文本内容。典型的技术包括聚类,编目,分类和归类。很多工具使用的典型的分类方法包括朴素贝叶斯,支持向量机和K最近邻分类算法。
下面的表格包含了常用的文本挖掘技术,包括机器学习和每一种技术的考虑因素。
| 文本挖掘技术 | 关键的考虑因素 |
| 组织和构建内容 |
|
| 文本处理 |
|
| 统计学分析 |
|
| 机器学习 |
|
| 分类方法 |
|
| 模型评估 |
|
一旦使用以上的技术对文本进行了处理,分组和分析,评价结果就变得很重要。评估的目的是确定你是否已经找到了最相关的材料或是否你丢失了一些重要术语。你将会使用查准率和查全率和评估结果。
使用AWS服务和RapidMiner进行情感分析
现在让我们看一下你如何使用AWS服务和RapidMiner进行情感分析,这是文本挖掘一个很普遍的应用案例。在情感分析中,你识别积极和消极的观点,情绪和评价,经常使用机器学习技术分析文本内容。使用AWS和RapidMiner,你不用将非结构化数据迁移到另一个环境中就可以使用情感分析这样的技术对存储在S3中的数据直接进行分析。
如下所示,你可以使用RapidMiner创建文本挖掘流程与S3进行集成。S3上的一个对象可能是任何一种文件,也可能是任何一种格式,如文本文件,招聘,或视频。这使得S3在存储文本挖掘和先进的分析学所需的非结构化数据方面变得非常有用。

亚马逊S3服务与其他的亚马逊大数据服务,如Amazon Redshift ,Amazon RDS ,Amazon DynamoDB , Amazon Kinesis 和Amazon EMR ,是集成的。这就产生了在AWS中使用RapidMiner开发文本挖掘模型的有趣场景。例如,你可以使用S3服务来存储从这些亚马逊业务中提取的数据,然后使用RapidMiner对这些数据快速构建一个文本挖掘模型。你可以将模型输出的结果存储到你选择的S3桶和区域中并将这些结果和更广泛的最终用户社区分享。
下面的举例使用加利福尼亚大学尔湾分校主办的SMS Spam collection(垃圾短信收集)数据组。SMS Spam collection是由一组为手机垃圾的研究而收集的标签消息组成的。这个数据组综合了垃圾和非垃圾短信(标记为ham)。这一数据组每行一条短信,使用UTF-8编码,以制表符为分隔,构成一个文本文件。
视频演示
下面的视频样本将会向你展示如何使用RapidMiner和S3进行文本挖掘。注意:视频样本没有声音。
开始前,请:
1.下载并安装RapidMiner软件和可从RapidMiner Marketplace获取的RapidMiner Text Processing Extension。你可以将RapidMiner安装在你的本地电脑上。如果你当前的电脑配置不能提供足够的容量,也可以将RapidMiner安装在亚马逊EC2实例上。
2.使用你的AWS证书在RapidMiner配置S3连接信息。要使用S3服务,你需要有一个AWS账户。
3.将文本挖掘案例研究所需输入数据组上传到S3桶中。
从S3中导入和读取数据到RapidMiner
下面的视频将会向你展示如何使用你上传到S3桶中的数据,S3服务和RapidMiner创建一个文本挖掘应用。记住:你必须导入使用UTF-8编码的文件,确定制表符为分隔符以便以正确的格式来处理文件。
视频:从S3中导入和读取数据到RapidMiner
使用RapidMiner’s Validation运算符
当对不可见的数据运行模型时,你看到的准确性可能低于预期。这是可能的,因为我们使用的方法可能已经学习了它所看到的数据,但是从未针对不可见的数据对该方法进行测试。为了解决这一问题,你可以使用下面的视频中所示的RapidMiner Validation运算符。
视频:使用RapidMiner’s Validation运算符
在RapidMiner中应用Store运算符
为了将已经学习到的模型应用到新数据,你必须将模型和单词表存储到RapidMiner仓库。你必须存储单词表是因为当你预测一个新消息是垃圾短信还是非垃圾短信的概率时,你不得不使用原来的过程中使用的相同的属性或单词。因此,你需要相同的单词表和模型,需要以你处理正在学习的数据时使用的方式来处理新数据。下面的视频展示了这是如何做到的。
视频:在RapidMiner中应用Store运算符
将不可见的数据应用到RapidMiner模型
下面的视频展示了如何应用你使用Retrieve运算符为新的不可见数据构建的模型来预测新消息是非垃圾短信还是垃圾短信。
视频:将不可见的数据应用到RapidMiner模型
使用Write S3运算符存储结果
下面的视频展示了如何在RapidMiner中使用Write S3运算符将输出结果存储到S3桶中,该桶已经在前面的概述中被设置为RapidMiner的一个连接。你可以从特定的S3桶中将输出结果下载到本地,使用文本编辑器查看这些结果。
视频:使用Write S3运算符存储结果
活动推荐:7月23日CSDN在线培训——新创公司用AWS搭建高扩展性架构
 订阅“AWS中文技术社区”微信公众号,实时掌握AWS技术及产品消息!
订阅“AWS中文技术社区”微信公众号,实时掌握AWS技术及产品消息!
AWS中文技术社区为广大开发者提供了一个Amazon Web Service技术交流平台 ,推送AWS最新资讯、技术视频、技术文档、精彩技术博文等相关精彩内容,更有AWS社区专家与您直接沟通交流!快加入AWS中文技术社区,更快更好的了解AWS云计算技术。
( 翻译/吕东梅 责编/王鑫贺 )
正文到此结束
热门推荐










相关文章

近期评论
-
你这基本没有更新呀,最近文章显示还是2019年的文章。不符合要求哈
-
关键词:慕云博客 链接:https://www.lilun.me 描述:分享原创文字的个人博客
-
-
-
可以提供一下源码吗
-
不是商业站,鸡娃学习笔记
-
-
-
-
听他们说很厉害的样子
Loading...
![[HBLOG]公众号](http://www.liuhaihua.cn/img/qrcode_gzh.jpg)

