阿里云分布式缓存OCS与DB之间的数据一致性
OCS 概要介绍
据AlertSite网络分析公司表示,Facebook的响应时间在2010年平均为1秒钟,到2011年中期已提高到了0.73秒。对比来看,响应时间占第二位的LinkedIn,网络下载内容时要花费将近2倍的时间。Twitter的响应时间则整整迟了2秒钟。响应时间优化的首要手段就是采用缓存技术,减少系统间交互请求和磁盘IO。
OCS是阿里巴巴集团的分布式缓存产品,支撑着淘宝、阿里巴巴、支付宝的日常运作,尤其在双11等大型活动上,承载了绝大多数的数据请求。与OCS相比,著名的Memcached具备了分布式集群管理的功能。2014年OCS经历了从分布式到云服务的进化,作为阿里云服务的缓存产品正式商业化。
OCS 技术讲解
OCS的核心存储是淘宝的开源产品TAIR(发音:太爱儿)
TAIR原理
角色上分为DataServer,ConfigServer:
- ConfigServer负责数据的路由表管理,决定着哪些数据应该去哪里访问。同时也管理着DataServer节点的存活状态,自动踢出宕机或者异常节点。
- DataServer是数据存储节点,负责数据的增删改查。通过Plugin机制支持多种存储引擎。常用的有基于内存的,所有的数据保存在内存之中,查询速度快,但不持久化,网络正常的情况下,客户端在0.2ms内得到请求响应。另外一种常用存储引擎基于SSD介质再依靠内存加速,特点是容量大,成本低,性能上接近内存引擎,客户端请求响应时间大概是1ms。
集群初始化时ConfigServer会根据DataServer的数量分配BucketID到DataServer上,这层映射关系就是数据路由索引,BucketID属于[0-1023]的范围内。客户端第一次启动时会从ConfigServer上拉取映射关系,之后的读写请求,根据全局约定的Hash算法(例如MurmurHash(key)24)计算出BucketID,根据映射关系描述向指定的DataServer上发送请求。
ConfigServer上的路由信息会根据DataServer存活状况动态修改更新;新结果再告知给DataServer;当DataServer处理客户端响应时,将变更通知给客户端。

图1 路由路径
从TAIR到OCS
云服务化的过程中,首要问题是满足用户的兼容性需求,用户访问接口上支持广泛流行的Memcached接口,原生于Memcached的应用,可以无缝迁移到OCS上来。
其次是稳定性,集群升级时,由于进程重启会造成应用请求OCS瞬间报错,OCS实现了一套热升级方案,在保持TCP链接不中断的情况下重启进程。
云服务还有一个重要特性就是多租户,多租户的情况下,为了防止某一两个用户的高并发访问造成集群负载上升,从而影响了其他租户的稳定性。OCS内部对不同的租户进行了资源隔离,针对请求量、带宽、内存使用量做了严格的限制。不同规格的用户可以购买不同规格的OCS实例,之间不会互相干扰。
与OCS相比,自建的Memcached解决了单机容量上线问题,实现扩容自动化且不需要修改客户端配置,同时输出了性能监控指标,网页版Console命令等。
缓存失效一致性问题
一般缓存的使用方式是:先读取缓存,若不存在则从DB中读取,并将结果写入到缓存中;下次数据读取时便可以直接从缓存中获取数据。
数据的修改是直接失效缓存数据,再修改DB内容,避免DB修改成功,但由于网络或者其他问题导致缓存数据没有清理,造成了脏数据。
但这样仍然无法避免脏数据的产生,一种并发的场景下:假设业务对数据Key:Hello Value:World有大量的读取和修改请求。线程A向OCS读取Key:Hello,得到Not Found结果,开始向DB请求数据,得到数据Key:Hello Value:World;接下来准备向OCS写入此条数据,但在写入OCS前(网络,CPU都等可能导致A线程处理速度降低)另一B线程请求修改数据Key:Hello Value:OCS,首先执行失效缓存动作(因为B线程并不知道是否有此条数据,因此直接执行失效操作),OCS成功处理了失效请求。转回到A线程继续执行写入OCS,将Key:Hello Value:World写入到缓存中,A线程任务结束;B线程也成功修改了DB数据内容为Key:Hello Value:OCS。

图2 并发时序
此时OCS中的数据为Key:Hello Value:World;DB中的数据为Key:Hello Value:OCS,出现缓存脏数据!
为了解决这个问题,OCS扩充了Memcached协议(公有云即将支持),增加了deleteAndIncVersion接口。此接口并不会真的删除数据,而是给数据打了标签,表明已失效状态,并且增加数据版本号;如果数据不存在则写入NULL,同时也生成随机数据版本号。OCS写入支持原子对比版本号:假设传入的版本号与OCS保存的数据版本号一致或者原数据不存在,则准许写入,否则拒绝修改。
回到刚才的场景上:线程A向OCS读取Key:Hello,得到Not Found结果,开始向DB请求数据,得到数据Key:Hello Value:World;接下来准备向OCS写入此条数据,版本号信息默认为1;在A写入OCS前另一个B线程发起了动作修改数据Key:Hello Value:OCS,首先执行删除缓存动作,OCS顺利处理了deleteAndIncVersion请求,生成了随机版本号12345(约定大于1000)。转回到A线程继续执行写入OCS,请求将Key:Hello Value:World写入,此时缓存系统发现传入的版本号信息不匹配(1 != 12345),写入失败,A线程任务结束;B线程也成功修改了DB数据内容为Key:Hello Value:OCS。
此时OCS中的数据为Key:Hello Value:NULL Version:12345;DB中的数据为Key:Hello Value:OCS,后续读任务时会再次尝试将DB中的数据写入到OCS中。
类似的并发场景还有很多,读者可以自行推演,同时也可以思考下为何约定随机生成的版本要大于1000?
缓存数据的同步的一致性问题
随着网站规模增长和可靠性的提升,会面临多IDC的部署,每个IDC都有一套独立的DB和缓存系统,这时缓存一致性又成了突出的问题。
首先缓存系统为了保证高效率,会杜绝磁盘IO,哪怕是写BINLOG;当然缓存系统为了性能可以只同步删除,不同步写入,那么缓存的同步一般会优先于DB同步到达(毕竟缓存系统的效率要高得多),那么就会出现缓存中无数据,DB中是旧数据的场景。此时,有业务请求数据,读取缓存Not Found,从DB读取并加载到缓存中的仍然是旧数据,DB数据同步到达时也只更新了DB,缓存脏数据无法被清除。
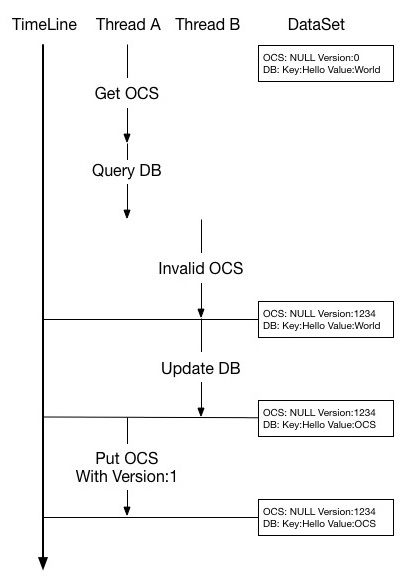
图3 并发时序
从上面的情况可以看出,不一致的根本原因是异构系统之间无法协同同步,不能保证DB数据先同步,缓存数据后同步。所以就要考虑缓存系统如何等待DB同步,或者能否做到两者共用一套同步机制?缓存同步也依赖DB BINLOG是一个可行的方案。
IDC1中的DB,通过BINLOG同步给IDC2中的DB,此事IDC2-DB数据修改也会产生自身的BINLOG,缓存的数据同步就可以通过IDC2-DB BINLOG进行。缓存同步模块分析BINLOG后,失效相应的缓存Key,同步从并行改为串行,保证了先后顺序。
这样,IDC间的数据同步架构更加简单清晰,系统服用率高,做好BINLOG同步和抓取即可。
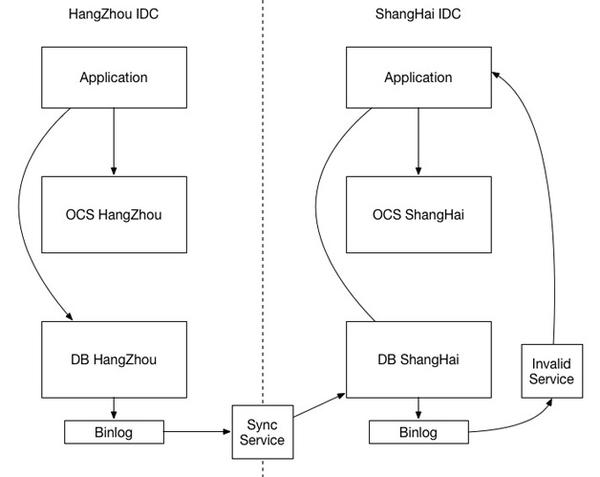
图4 异地同步
总结
不同系统之间的数据同步一直是一个世界性的问题,目前仍然没有方法解除CAP魔咒,只能根据实际的情况在三者之间寻找理想的平衡点。本文介绍的解决方案,其一是利用了缓存系统的原子操作,其二是利用了外部系统同步机制保证先后,都是在牺牲最小的性能代价时获取最大的一致性保证,但仍然无法覆盖全部场景下的一致性问题。
 作者: 杨成虎
作者: 杨成虎
作者简介: 花名叶翔,阿里巴巴集团技术专家,擅长通过NoSQL存储系统、Cache系统去解决海量数据的互联网问题。2009年加入阿里巴巴,先后开发了阿里的小文件系统,KV存储系统,负责阿里Tair系统的开发与架构设计。2013年至今主导研发了阿里云分布式缓存服务OCS,目前仍致力于NoSQL产品的云服务化工作。
正文到此结束
热门推荐










相关文章

近期评论
-
你这基本没有更新呀,最近文章显示还是2019年的文章。不符合要求哈
-
关键词:慕云博客 链接:https://www.lilun.me 描述:分享原创文字的个人博客
-
-
-
可以提供一下源码吗
-
不是商业站,鸡娃学习笔记
-
-
-
-
听他们说很厉害的样子
Loading...
![[HBLOG]公众号](http://www.liuhaihua.cn/img/qrcode_gzh.jpg)

