Raid1源代码分析--写流程
正确写流程的总体步骤是,raid1接收上层的写bio,申请一个r1_bio结构,将其中的所有bios[]指向该bio。假设盘阵中有N块盘。然后克隆N份上层的bio结构,并分别将每个bios[]指向克隆出来一个bio结构,然后进行相应设置。
对于没有Write Behind模式而言,之后将所有这些bios[](共用页结构)放入队列pending_list中,对内存bitmap置位。接着由守护进程摘取pending_list链中的bio,然后将内存bitmap同步下刷到磁盘,紧接着立即一次性下发bio,写成功返回,同时更新bitmap状态,然后异步刷磁盘。如图4所示。
对于设置了Write Behind模式而言,还需要将接收到的上层bio的页结构拷贝到WriteMostly盘对应的bios[]中(每个WriteMostly盘对应一份拷贝),之后将所有这些bios[]放入队列pending_list中,对内存bitmap置位。接着由守护进程摘取pending_list链中的bio,然后将内存bitmap同步下刷到磁盘,紧接着立即一次性下发bio。当只剩下WriteMostly盘未完全写成功后(即非WriteMostly盘都写成功了),则认为已经写成功,返回。等到所有WriteMostly盘真正全部写完之后才释放拷贝的页结构和r1_bio。同时更新bitmap状态,然后异步刷磁盘。如图1、2所示。
整体的函数调用关系、进程切换关系和大体流程,如图3所示。

图1 无Write Behind模式的写流程

图2 有Write Behind模式的写流程
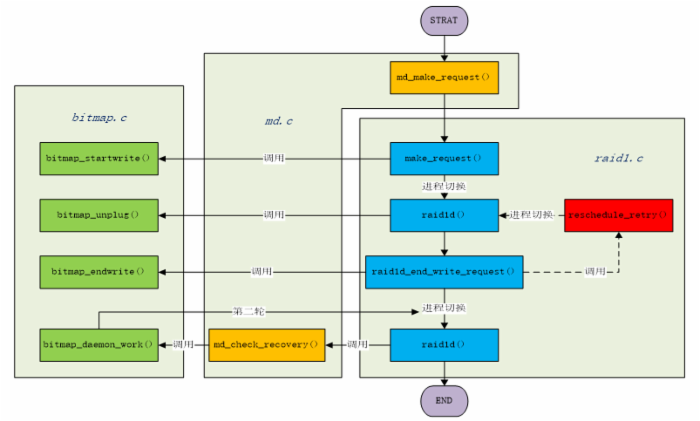
图3 raid1读流程整体框架图
写流程主要涉及以下函数:
请求函数make_request
写请求下raid1d
回调函数raid1_end_write_request
写出错处理raid1d
下面具体分析写流程。
1)请求函数make_request
写请求封装成bio后,由md设备的md_make_request下发请求,md又发给具体的设备raid1,对应raid1的make_request函数,下面将从raid1的make_request开始理解该部分的流程。总体流程如图4所示。

图4 make request函数写流程整体框架图
代码的具体分析如下:
1. 调用md_write_start,等待盘阵的超级快更新完成之后继续下面的步骤。
1.1 如果不为写则直接返回。
1.2 如果阵列为临时只读状态,则设置为读写状态,设置阵列mddev的MD_RECOVERY_NEEDED位,并唤醒守护进程和同步守护线程。
注:
-
- set_bit(MD_RECOVERY_NEEDED, &mddev->recovery);表示可能需要resync或recovery;
- resync使各子设备上的数据同步,recovery就是恢复数据的过程。
1.3 如果阵列为安全模式,则设置为不安全模式。
1.4 如果阵列mddev的in_sync=1,则设置in_sync=0,表示阵列要开始进行写操作了。唤醒守护进程。
set_bit(MD_CHANGE_CLEAN, &mddev->flags);也就是将superblock中的MD_SB_CLEAN标志清掉。
1.5 同步in_sync标志到磁盘中阵列超级块上。
2. 如果访问要求设置barrier,而MD设备(这里是指raid1)不支持设置barrier,则结束bio,立即返回,将-EOPNOTSUPP信息反馈给上层。
注:这里的barrier指的是bio带有的barrier属性。
3. 等待设备上的barrier消除。
注:这里是指raid1自己为同步做的一套barrier。
4. 申请一个r1_bio结构(该结构主要用于管理raid1的bio),该结构中有一个数组bios数组指向对应各磁盘的bio。
5. 遍历盘阵中所有盘。
5.1 如果盘存在,但是阻塞了(Blocked),那么跳出循环等待阻塞消除,重新进入循环开头。(通常由用户发ioctl设置和清除)
5 .2 如果盘存在,并且盘没有坏(!Faulty [fp6] ),增加该盘的下发IO计数。
5.2.1 如果该盘坏了(Faulty),减少该盘的下发IO计数,r1_bio的bio[]数组中的该盘的bio置NULL。
5.2.2 将r1_bio的数组中的该盘指向用户bio。targets用来表示可用的盘。
5.3 如果是其他情况(一定是出错情况),r1_bio的数组中的该盘的bio置NULL。
6. 如果盘阵中的可用的盘数量targets小于conf->raid_disks,则说明有的盘坏掉了。那么就将盘阵设置为降级(R1BIO_Degraded)状态。
7. 如果设置了延迟写,需要将用户bio的数据通过调用alloc_behind_pages函数拷贝一份保存在behind_pages中。并将盘阵设置为R1BIO_BehindIO状态。
8. 设置r1_bio的未完成请求数和延迟写的未完成请求数都置为0。
9. 根据用户bio中的BIO_RW_BARRIER标志,确定是否设置r1_bio中的barrier标志。也就是判断是否要set_bit(R1BIO_Barrier [fp7] , &r1_bio->state)。
注:根据用户bio中的标志,确定是否设置raid-bio中的barrie标志;
如果下挂的磁盘不支持barrier操作,则在raid1_end_write_request中加以处理,具体的处理就是在守护进程中重试。
10. 初始化一个bio_list链b1。
11. 遍历盘阵中所有盘。
11.1 对于每个磁盘,克隆一份用户bio到r1_bio数组对应元素bios中,并设置相关字段以及回调函数raid1_end_write_request。
11.2 如果设置了延迟写,则r1_bio中的数组bios每个元素的bio_vec指向保存的延迟写拷贝behind_pages。如果设置了WriteMostly模式,则对盘阵增加一个延迟写的未完成请求数。
11.3 r1_bio->remaining记录还未提交的请求数,这里每到一个盘都会+1。
11.4 将克隆的这份bio挂到bio_list 链b1中。
12. 调用bitmap_startwrite,通知bitmap进行写数据块对应的设置。
13. 将该克隆的得到的b1(多份相同的bio)加到raid1的pending_bio_list链中。
14. 如果用户IO为sync io,则唤醒守护进程raid1d,进程切换到raid1d,由守护进程通过操作pending_bio_list链,继续处理r1_bio请求。
2)写请求下发raid1d
pending_bio_list所有bio项是一起提交的,retry_list中的r1_bio则是逐个处理。
如果pending_bio_list队列不为空(有等待的访问请求),则将这些请求逐一提交。在提交写请求之前,需要将内存bitmap刷磁盘(为了避免掉电等情况下,内存中的数据丢失,出现错误),保证在数据写入前完成bitmap的写入。直到pending_bio_list链表的所有请求全部提交。
正常流程走下来,在这里就把写请求下发了。如图5所示。
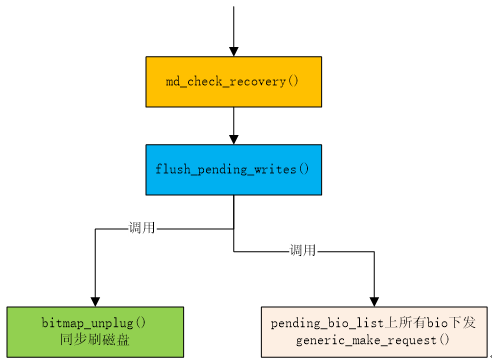
图5守护进程下发写请求
3)回调函数raid1_end_write_request
总体流程如图6所示。
首先我们不考虑出错流程。假设有5块盘,其中3块为WriteMostly盘。当设置了Write Behind时,behind remaining = 3,remaining = 5。
如果已经返回了1个WriteMostly盘,1个非WriteMostly盘。那么还剩下2个WriteMostly盘,1个非WriteMostly盘,此时behind remaining = 2,remaining = 3。如果接下来非WriteMostly盘返回,不需要减behind remaining即到了判断语句behind remaining >= remaining - 1,所以这时该条件成立。那么设置R1BIO_Returned,endio,通知上层写请求已经结束。此时只剩下WriteMostly盘,进而达到延迟写的效果。但是此时r1_bio等相关结构体和behind pages还未释放。等WriteMostly盘返回之后,save_put_page(), bitmap_endwrite(),释放behind pages和r1_bio结构。
如果所有WriteMostly盘都返回了,仍然有非WriteMostly盘未返回,那么一直有behind remaining < remaining,与没有设置Write Behind时效果一样。
没有设置Write Behind的情况比较简单,参照流程图和下面的代码走读分析即可理解。
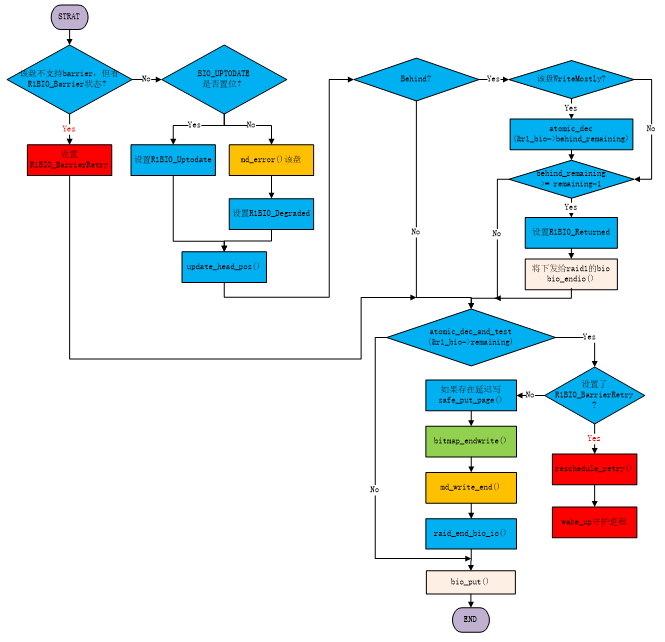
图6 raid1_end_write_request函数流程
下面对具体代码流程进行分析:
1. 选出要回调结束bio的盘号mirror。
2. 如果请求要求设置barrier,但是下挂的设备不支持barrier,则设置该盘阵为R1BIO_BarrierRetry状态。跳到步骤8。
注:这种情况是RAID1设备支持barrier bio,但是下层设备不支持;这里的barrier和make request中刚开始的时候的barrier的不同,这里的-EOPNOTSUPP值,是下发之后,下层回调传上来的值。而make_request中bio_endio传入的-EOPNOTSUPP,是将-EOPNOTSUPP回调给raid1的上层。一个是给接收到的下层设备的返回信息,一个是反馈给上层的返回信息。
3. r1_bio->bios[mirror]指针置为NULL。(所指原区域还未释放,用to_put指针来找)
4. 如果状态不是"有效"的(不是uptodate),就将该盘置为出错。并将盘阵降级处理。
5. 如果状态是”有效”的,将盘阵设置为R1BIO_Uptodate。
6. 记录这次操作结束的在磁盘上的位置。
7. 如果有延迟写。
7.1 如果该盘是WriteMostly,延迟写的未完成请求数-1。
7.2 如果只剩下WriteMostly盘的请求,并且r1_bio的状态是R1BIO_Uptodate,那么就认为写操作成功,endio返回。
7.3 减少该盘的io下发计数。
8. 减少一个remaining,并且检查是否全部请求都完成了(remaining为0)。如果r1_bio中所有请求都完成了,那么进入下面流程。表示该请求真的完全完成,可以释放了相关的结构了。
8.1 如果R1BIO_BarrierRetry状态(前面设置过),那么将这个r1_bio加入retry队列。跳到retry流程。
8.2 释放延迟写的页。
8.3 设置bitmap attr属性为CLEAN。
8.4 关于安全模式。
8.5 end io。
9. 如果计数为0,把to_put这个bio释放掉。
当下发磁盘的写请求完成后,需要将bitmap内存页中相应的bit清零,然后把bitmap文件下刷。这些通过守护进程来做,而这个过程不需要等待写bitmap磁盘文件完成,因此是异步的。(由bitmap_daemon_work完成)这里bitmap不需要同步来做,因为可以保证数据的正确性。即使写失败,最多带来额外的同步,不带来数据的危害。
4)写出错处理raid1d
如果接收到的上层bio是因为设置了barrier属性,而子设备又不支持barrier而失败的(这个情况只发生在写操作),则清除r1_bio的barrier属性,重新提交这个r1_bio。
守护进程处理这种写出错的具体流程如图7所示。
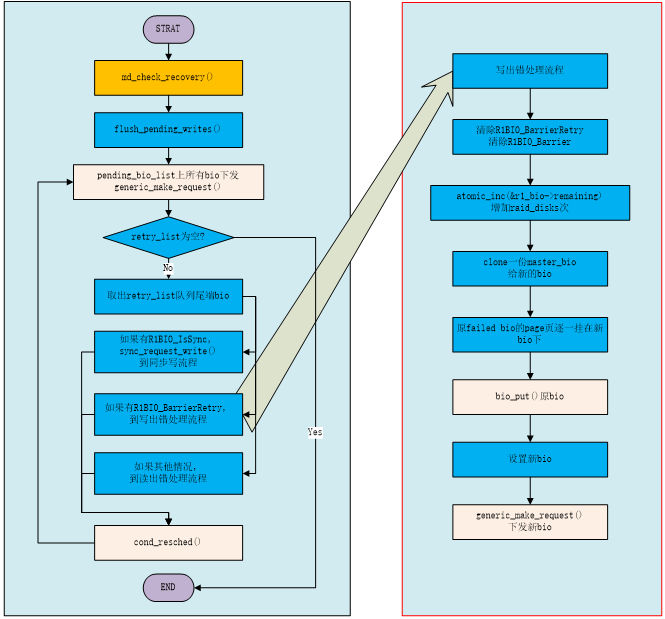
图7 守护进程处理barrier bio造成的写出错流程
具体代码流程如下:
1. 清除r1_bio的R1BIO_BarrierRetry和R1BIO_Barrier状态位。
2. 增加盘阵中r1_bio->remaining请求数,增加个数为盘阵中盘的个数。
3. 对于盘阵中的每一个磁盘,克隆master_bio给它,并进行初始化。(其中原failed bio的每个page要逐一复制给新的bio,因为可能存在write behind设备)。
4. 下发这个新的bio。
转载请注明出处:http://www.cnblogs.com/fangpei/
正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](http://www.liuhaihua.cn/img/qrcode_gzh.jpg)

