【微信分享】李滔:搜狐基于Spark的新闻和广告推荐实战
继“ YARN or Mesos?Spark痛点探讨 ”、“ Mesos资源调度与管理的深入分享与交流 ”、“ 主流SQL on Hadoop框架选择 ”与“ 七牛是如何搞定每天500亿条日志的 ”之后,7月30日,搜狐大数据中心技术经理李滔在CSDN Spark微信用户群,与近千名Spark技术开发人员,结合搜狐内部的新闻与广告推荐系统,深入分享了团队基于Spark的机器学习实战。
李滔 , 中国科技大学博士毕业,现供职于搜狐大数据中心用户推荐部,从事推荐和广告算法研发工作。主要关注技术方向包括广告技术、并行计算、大数据分析等。 李滔曾就职于理光北京研究所以及Teradata公司。在理光期间设计了理光相机的第一代人脸检测/对焦系统。之后在Teradata公司从事大规模数据挖掘的算法设计开发,基于Teradata Aster的Map/Reduce和图计算平台设计实现了多种机器学习/数据挖掘算法并成功应用于商业实践。
以下为演讲实录
我今天的分享主要偏应用层面的,介绍一下我们团队在新闻推荐和广告方面的一些心得。从业务层面来讲,我们主要接触了广告和新闻推荐。它们相似点是都可以看做一个点击率估计的任务。根据用户的属性,估计一下哪个广告,哪个新闻用户可能点击,把这个可能点击的推荐给用户。
为了完成这个点击率预估,我们一般会收集特征,一般是从三个层面,一个是用户层面,一般包括用户的人口属性以及兴趣属性。第二就是item层面,例如新闻的分类,关键字,topic。广告也有一些属性,广告的类型,广告的文字描述。第三个层面是上下文,这个用户访问的时间是什么,广告位所在的内容页属性。所以整个特征的描述,会从这三个维度去匹配,匹配到一个最佳点,找到用户最可能点击的广告或者是新闻。

广告系统架构图
上面是各个来源的广告请求。下面包括三个部分:左边这块主要是下面左边这块主要是数据准备,包括ctr模型,用户定向标签,内容页属性等。右边是主要是广告索引,根据广告主定向条件和用户定向标签以及广告位信息检索出可以参与竞价的广告。这一部分可能的侯选的广告会进入到中间黄色的Ranking部分,综合考虑到广告的估计点击率和广告主的出价对广告做排序。Ranking下面的模块主要是做广告投放策略的控制,比如现在是出竞价广告还是出展示广告。推荐系统架构也非常类似,大体上也可以分为用户/页面属性,索引和排序三大模块。
用户兴趣标签的建立
对一个媒体网站来讲,一个比较重要的任务就是获取用户对于不同类型文章的兴趣分布。用户的兴趣分布会被作为用户属性标签,和其他类型的标签(例如人口属性等)一起用作推荐的模型特征。这里的问题在于用户阅读新闻的分布会集中在几个热点类别上。
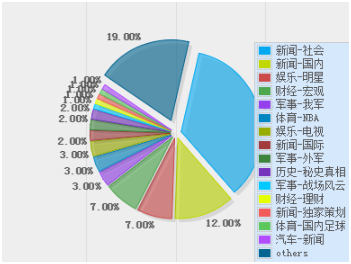
上面是我们统计了手机搜狐网一个月的阅读新闻分布。发现社会新闻,国内新闻,娱乐新闻这三大类加在一起就超过了50%的流量。具体原因首先是一些热点新闻,基本上是属于社会的热点事件,这些是有巨大的点击量的。另外新闻的曝光也是有偏的曝光,得到了大量的曝光就会得到大的点击量。而一些相对反应个性的新闻曝光量比较少。
所以我们对用户兴趣的建模不能建立在用户阅读新闻的绝对分布上,而应该是用个体的分布相对于所有用户平均分布的偏移度来建模。我们把一个月的用户阅读新闻做了聚类,挑出两个有特点的类别,统计用户访问新闻的分布,以及把它和所有用户的平均分布做比较,下图是其中两个例子:

这两个图当中,蓝色的线都是用户的平均分布。左边这个图,红色线我们称之为是财经爱好者的群体。这个群体财经的点击量明显高于平均曲线,而对新闻类(社会和国内新闻)差异并不太大。但如果按点击量绝对值的话财经、新闻两类的点击量相似。右边这个图是军事爱好者的阅读者,同时对财经新闻的阅读量也是比平均分布高一些,低于平均分布的也是娱乐和社会新闻。也就是说这类用户和左边有点像,相对财经和军事阅读量高,同时对娱乐和社会新闻感兴趣的低一些。
用户兴趣评估
第二个问题是我们用来收集用户兴趣的话,我们必须考虑到用户的长期兴趣和短期兴趣。比如用户是体育迷或者是军事迷,这是他的长期兴趣。还有是受到一些突发事件的影响,例如奥运会,用户短期的兴趣会发生变化。所以我们要从短期和长期两个角度评价他的兴趣。下面这个图示意了我们做用户标签计算的流程:
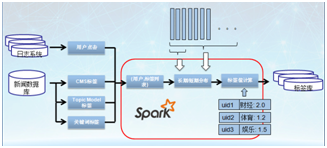
用户的点击数据会放在日志系统(HDFS)里,新闻的分类标签数据(CMS标签)存放在新闻数据库(MySQL)。这些标签首先会和用户日志做一个join,得到一个(用户,标签)列表。计算出分布之后,会和平均点击分布在每个新闻类型的维度上计算一个偏离度,这个偏离度会被量化之后得到一个标签权重值。这样就得到了每个用户的兴趣标签,然后存到redis库里。
标签的计算基于Spark实现。由于Spark提供了非常丰富的数据处理操作,像Map、reduce,filter,join,cogroup,以及scala语言的简洁性,使得代码量大为减少。另外由于Spark是内存计算,整个流程的处理时间相对Hadoop减少5~10倍。
ctr预测
常用的ctr预测的算法包括LR(Logistic Regression), FM(Factorization Machines), GBDT等等。像LR和GBDT, Spark Mllib都提供了相应的实现,另外台湾大学的Liblinear也有一个Spark版本的LR算法的实现。Mllib的LR是基于LBFGS的实现,而Liblinear是基于TRON的实现。实际当中我们测试过这两个算法,发现优化的性能非常接近。
FM目前在Spark上有一个JIRA (SPARK-7008),但是目前还没有正式release。LR是最常用的算法,好处是简单明了,效果分析也相对容易,问题在于想要达到好的效果需要尝试大量的特征组合,特征工程比较费劲。FM和GBDT都是非线性的分类器(FM可以看做二次的),省去了复杂的特征组合的过程,性能也往往较好,但是出了问题不太好分析原因。实际当中可以先尝试LR,当性能不满足要求时再试FM或GBDT。
FaceBook的一篇文章(Practical Lessons from Predicting Clicks on Ads at Facebook)提出先使用GBDT得到一个分类器,其中每棵树的叶子节点作为特征再送入LR训练分类器。解决了繁琐的特征组合问题。使用LR还有一个原因是比较好处理探索和利用问题(Exploartion & Exploitation)。
由于每天都会有新的新闻产生,而对这些新闻一开始点击率估计可能不准确,因此需要通过适当的投放从而收集信息以提升点击率的估计。这属于牺牲短期利益以获取长期利益的最大化。对于线性模型实现探索和利用有Yahoo的LinUCB以及微软的OBPR。另外对FM,也可以通过Bayes化实现E&E (Bayesian factorization machines, 2011),但是实现要相对复杂一些。目前我们的建模主要依赖spark平台。整个集群规模目前约为500台机器,以Spark on yarn方式部署。除了广告和推荐建模外,还支撑用户定向,广告系统BI的任务。
时间关系今天的分享就到这里。谢谢大家!
QA(部分)
【问题】不知道搜狐数据分析在R的使用上如何?
李滔: 我们现在R使用较少。BI类需求基本依赖Hive,SparkSql这样的工具。算法类主要是Spark。R会有一些临时的任务,例如分布的统计等。
【问题 】谢谢老师分享,能否再介绍下新闻个性推荐?
李滔: 其实新闻个性推荐和上面思路基本一致。包括用户兴趣建模(离线和在线标签),新闻点击率估计两个主要任务。基本都是上面的方法。
【问题】模型拟定和训练上,过拟合问题是否可以谈谈?
李滔: 过拟合一般通过仔细的参数选择和交叉验证这样的实验手段可以克服。首先根据结构风险理论,简单模型例如线性相对非线性模型较容易避免过拟合。而适当增大模型的正则化项的系数也会有帮助。但是对大数据来说,交叉验证时间代价太大。
【问题】Bi类需求在hive和sparkSQL实现,那前台显示有没有好工具?如果有比较明细的数据呢?
李滔: 展示工具,商用的比如Tableau,开源的比如Saiku等。
群内朋友补充: hue也可以。
【问题】在使用spark mllib的过程中有没有什么踩坑的经验可以分享,我最近在使用随机森林算法的时候有一个job hang住了,在日志里面没有发现任何错误,怀疑是死锁,类似的情况你们有遇到吗?
李滔: mllib比较常见的如内存不足,GC,参数设置(例如frameSize等),具体仔细阅读Spark的性能调优的tutorial可以了解一大部分。关于你说的job hang住的问题,建议先分析是不是内存的原因。
【问题】李涛老师,问一下你们计算新闻相似度是用什么算法
李滔: 新闻相似度简单方法包括余弦距离,复杂一点可以用pLSA,LDA这样的话题模型。更复杂一点就是Deep Learning了。
参与方式
1. 微信群2已超过100人,请扫下方二维码,工作人员会邀请进入。 (注:CSDN Spark用户微信群1已满500,正在清理并邀请2群用户进入,分享和讨论将在群1中进行,QQ群和微信群同步直播)

2. 加入CSDN Spark技术交流QQ群,群号:213683328。
3. CSDN高端专家微信群,采取受邀加入方式,不惧高门槛的请加微信号“zhongyineng”,PS:带上你的BIO。
正文到此结束
热门推荐










相关文章

近期评论
-
你这基本没有更新呀,最近文章显示还是2019年的文章。不符合要求哈
-
关键词:慕云博客 链接:https://www.lilun.me 描述:分享原创文字的个人博客
-
-
-
可以提供一下源码吗
-
不是商业站,鸡娃学习笔记
-
-
-
-
听他们说很厉害的样子
Loading...
![[HBLOG]公众号](http://www.liuhaihua.cn/img/qrcode_gzh.jpg)

