MEAN实践——LAMP的新时代替代方案
【编者按】在九十年代,Linux+Apache+Mysql+PHP架构曾风靡一时,直到现在仍然是众多Web应用程序的基本架构。然而随着需求的变迁和数据流量的激增,LAMP已不可避免的走下神坛。近日,在MongoDB Blog中,Dana Groce介绍了一个基于新时代架构的实践——MEAN,MongoDB/Mongoose.js、Express.js、Angular.js和Node.js。
以下为译文
本系列博客的两篇文章主要关注MEAN技术堆栈的使用——MongoDB/Mongoose.js、Express.js、Angular.js和Node.js。这些技术都使用了JavaScript以获取更高的软件性能和开发者生产效率。
第一篇博文主要描述应用程序的基本结构和进行数据建模过程,而第二篇则会创建测试来验证应用程序行为,然后介绍如何设置并运行应用程序。
本系列博文阅读并不需求拥有这些技术的实践经验,所有技能等级的开发人员都可以从中获益。如果在这之前你没有使用过MongoDB、JavaScript或建立一个REST API的经验,不用担心,这里将用足够的细节介绍这些主题,包括身份验证、在多文件中构建代码、编写测试用例等。首先,从MEAN stack的定义开始。
什么是MEAN Stack
MEAN stack可概括为:
- M = MongoDB/Mongoose.js。流行的数据库,对 node . js来说是一个优雅的ODM。
- E = Express.js:一个轻量级Web应用程序框架。
- A = Angular.js:一个健壮的框架用于创建HTML5和JavaScript-rich Web应用程序。
- N = Node.js服务器端JavaScript interpreter。
MEAN stack是LAMP (Linux、Apache、MySQL,PHP / Python) stack的一个现代替代者,在九十年代末,LAMP曾是Web应用程序的主流构建方式。
在这个应用程序中并不会使用Angular.js,因为这里并不是要构建一个HTML用户界面。相反,这里创建的是一个没有用户界面的REST API,但它却可以作为任何界面的基础,如一个网站、一个Android应用程序,或者一个iOS应用程序。也可以说我们正在 ME(a)N stack上构建REST API,但这不是重点!
REST API是什么?
REST代表Representational State Transfer,是SOAP和WSDL XML-based API协议的一个更轻量级替代方案。
REST使用客户端-服务器模型,服务器是一个HTTP服务器,而客户端发送HTTP行为(GET、POST、PUT、DELETE),以及URL编码的变量参数和一个URL。URL指定了对象的作用范围,而服务器则会通过结果代码和有效的JavaScript Object Notation (JSON)进行响应。
因为服务器用JSON回复,MongoDB与JSON又可以很好地交互,同时所有组件都使用了JavaScript,因此MEAN stack非常适合本用例中的应用程序。在进入开始定义数据模型后,你会看到一些JSON的例子。
CRUD缩略词常被用来描述数据库操作。CRUD代表创建、读取、更新和删除。这些数据库操作能很好地映射到HTTP动作:
- POST:客户想要插入或创建一个对象。
- GET:客户端想要读取一个对象。
- PUT:客户想要更新一个对象。
- DELETE:客户想要删除一个对象。
在定义API后,这些操作将变得更加直观。REST APIs中通常会使用的一些常见HTTP结果代码如下:
- 200 ——“OK”。
- 201 ——“Created”(和POST一起使用)。
- 400 ——“Bad Request”(可能丢失所需参数)。
- 401 ——“Unauthorized”(身份验证参数丢失)。
- 403 ——“Forbidden”(已验证,但是权限不够)。
- 404 ——“Not Found”。
RFC文档中可以找到一个完整的描述,这个在本博客末尾的参考资料中列出。上面这些结果代码都会在本应用程序中使用,随后就会展示一些例子。
为什么从REST API开始?
部署一个REST API可以为建立任何类型应用程序打下基础。如前文所述,这些应用程序可能会基于网络或者专门针对某些平台设计,比如Android或者iOS。
时下,已经有许多公司在建立应用程序时不再使用HTTP或者Web接口,比如Uber、WhatsApp、Postmates和Wash.io。从一个简单的应用程序发展成一个强大的平台,REST API可以大幅度简化这个过程中其他接口和应用程序的实现。
建立REST API
这里会建立一个 RSS Aggregator,类似Google Reader,应用程序主要会包含两个组件:
- REST API
- Feed Grabber(类似Google Reader)
本系列博文都将聚焦这个REST API的打造,不会去关注RSS feeds的复杂性。现在,Feed Grabber的代码已经可以在github repository中发现,详情可以见博文列出的资源。下面将介绍打造这个API所需的步骤。首先会根据具体需求来定义数据模型:
- 在用户账户中储存用户信息
- 跟踪需要被监视的RSS feeds
- 将feed记录pull到数据库
- 跟踪用户feed订阅
- 跟踪用户会阅读哪个订阅的feed
用户则需要可以完成下列操作:
- 建立一个账户
- 到feed的订阅或者退订
- 阅读feed记录
- 标记feed/记录的阅读状态(已读/未读)
数据建模
这里不会深入讨论MongoDB中的数据建模,详细资料可以在博文后的列举的资料中发现。本用例需要4个collections来管理这个信息:
- Feed collection
- Feed entry collection
- User collection
- User-feed-entry mapping collection
Feed Collection
下面一起进入一段代码,Feed Collection的建模可以通过下述JSON文档完成:
{ "_id": ObjectId("523b1153a2aa6a3233a913f8"), "requiresAuthentication": false, "modifiedDate": ISODate("2014-08-29T17:40:22Z"), "permanentlyRemoved": false, "feedURL": "http://feeds.feedburner.com/eater/nyc", "title": "Eater NY", "bozoBitSet": false, "enabled": true, "etag": "4bL78iLSZud2iXd/vd10mYC32BE", "link": "http://ny.eater.com/", "permanentRedirectURL": null, "description": "The New York City Restaurant, Bar, and Nightlife Blog” } 如果你精通关系型数据库技术,那么你将了解数据库、表格、列和行。在MongoDB中,大部分的关系型概念都可以映射。从高等级看,MongoDB部署支持1个或者多个数据库。1个数据库可能包含多个collection,这个类似于传统关系型数据库中的表格。Collection中会有多个document,从高等级看,document相当于关系型数据库中的行。这里需要注意的是,MongoDB中的document并没有预设的格式,取而代之,每个document中都可以有1个或者多个的键值对,这里的值可能是简单的,比如日期,也可以是复杂的,比如1个地址对象数组。
上文的JSON文档是一个Eater Blog的RSS feed示例,它会跟踪纽约所有餐馆信息。因此,这里可能存在许多字段,而用例中主要关注的则是feed中的URL以及description。描述是非常重要的,因此在建立一个移动应用程序时,它会是feed一个很好的摘要。
JSON中的其他字段用于内部使用,其中非常重要的字段是_id。在MongoDB中,每个document都需要拥有一个_id字段。如果你建立一个没有——id的document,MongoDB将为你自动添加。在MongoDB中,这个字段就是主键的存在,因此MongoDB会保证这个字段值在collection范围唯一。
Feed Entry Collection
在feed之后,用例中还期望追踪feed记录。下面是一个Feed Entry Collection文档示例:
{ "_id": ObjectId("523b1153a2aa6a3233a91412"), "description": "Buzzfeed asked a bunch of people...”, "title": "Cronut Mania: Buzzfeed asked a bunch of people...", "summary": "Buzzfeed asked a bunch of people that were...”, "content": [{ "base": "http://ny.eater.com/", "type": "text/html", "value": ”LOTS OF HTML HERE ", "language": "en" }], "entryID": "tag:ny.eater.com,2013://4.560508", "publishedDate": ISODate("2013-09-17T20:45:20Z"), "link": "http://ny.eater.com/archives/2013/09/cronut_mania_41.php", "feedID": ObjectId("523b1153a2aa6a3233a913f8") } 再次提醒,这里同样必须拥有一个_id字段,同时也可以看到description、title和summary字段。对于content字段,这里使用的是数组,数据中同样储存了一个document。MongoDB允许通过这种方式嵌套使用document,同时这个用法在许多场景中也是非常必要的,因为用例往往需求将信息集中存储。
entryID字段使用了tag格式来避免复制feed记录。这里需要注意的是feedID和ObjectId的用法——值则是Eater Blog document的_id。这提供了一个参考模型,类似关系型数据库中的外键。因此,如果期望查看这个 ObjectId关联的feed document,可以取值 523b1153a2aa6a3233a913f8,并在_id上查询feed collection,从而就会返回Eater Blog document。
User Collection
这里有一个用户需要使用的document:
{ "_id" : ObjectId("54ad6c3ae764de42070b27b1"), "active" : true, "email" : "testuser1@example.com", "firstName" : "Test", "lastName" : "User1", "sp_api_key_id" : "6YQB0A8VXM0X8RVDPPLRHBI7J", "sp_api_key_secret" : "veBw/YFx56Dl0bbiVEpvbjF”, "lastLogin" : ISODate("2015-01-07T17:26:18.996Z"), "created" : ISODate("2015-01-07T17:26:18.995Z"), "subs" : [ ObjectId("523b1153a2aa6a3233a913f8"), ObjectId("54b563c3a50a190b50f4d63b") ], } 用户应该有email地址、first name和last name。同样,这里还存在sp_api_key_id和sp_api_key_secret——在后续部分会结合Stormpath(一个用户管理API)使用这两个字段。最后一个字段subs,是1个订阅数组。subs字段会标明这个用户订阅了哪些feeds。
User-Feed-Entry Mapping Collection
{ "_id" : ObjectId("523b2fcc054b1b8c579bdb82"), "read" : true, "user_id" : ObjectId("54ad6c3ae764de42070b27b1"), "feed_entry_id" : ObjectId("523b1153a2aa6a3233a91412"), "feed_id" : ObjectId("523b1153a2aa6a3233a913f8") } 最后一个collection允许映射用户到feeds,并跟踪哪些feeds已经读取。在这里,使用一个布尔类型(true/false)来标记已读和未读。
REST API的一些功能需求
如上文所述,用户需要可以完成以下操作:
- 建立一个账户
- 到feed的订阅或者退订
- 阅读feed记录
- 标记feed/记录的阅读状态(已读/未读)
此外,用户还需求可以重置密码。下表表示了这些操作是如何映射到HTTP路由和动作。
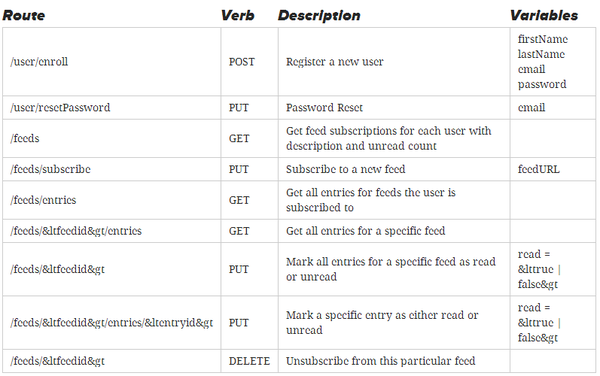
在生产环境中,HTTP(HTTPS)安全需求使用一个标准的途径来发送敏感信息,比如密码。
通过Stormpath实现现实世界中的身份验证
在一个鲁棒的现实世界应用程序中,提供用户身份验证不可避免。因此,这里需要一个安全的途径来管理用户、密码和密码重置。
在本用例中,可以使用多种方式进行身份验证。其中一个就是使用Node.js搭配Passport Plugin,这个方式通常被用于社交媒体账户验证中,比如Facebook或者Twitter。然而,Stormpath同样是一个非常不错的途径。Stormpath是一个用户管理即服务,支持身份验证和通过API keys授权。根本上,Stormpath维护了一个用户详情和密码数据库,从而客户端应用程序API可以调用Stormpath REST API来进行用户身份验证。
下图显示了使用Stormpath后的请求和响应流。
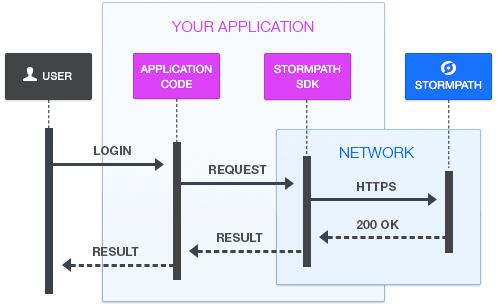
详细来说,Stormpath会为每个应用程序提供一个安全秘钥,通过它们的服务来定义。举个例子,这里可以定义一个应用程序作为“Reader Production”或者“Reader Test”。如果一直对应用程序进行开发和测试,定义这两个应用程序非常实用,因为增加和删除测试用户会非常频繁。在这里,Stormpath同样会提供一个API Key Properties文件。Stormpath同样允许基于应用程序的需求来定义密码属性,比如:
- 不低于8个字符
- 必须包含大小写
- 必须包含数字
- 必须包含1个非字母字符
Stormpath会跟踪所有用户,并分配他们的 API keys(用于REST API身份验证),这将大幅度简化应用程序建立过程,因为这里不再需要为验证用户编写代码。
Node.js
Node.js是服务器端和网络应用程序的运行时环境。Node.js使用JavaScript并适合多种不同的平台,比如Linux、Microsoft Windows和Apple OS X。
Node.js应用程序需要通过多个库模块建立,当下社区中已经有了非常多的资源,后续应用程序建立中也会使用到。
为了使用Node.js,开发者需要定义package.json文件来描述应用程序以及所有库的依赖性。
Node.js Package Manager会安装所有库的副本到应用程序目录的一个子目录,也就是node_modules/。这么做有一定的好处,因为这样做可以隔离不同应用程序的库版本,同时也避免了所有库都被统一安装到标准目录下造成的代码复杂性,比如/usr/lib。
命令npm会建立node_modules/目录,以及所有需要的库。
下面是package.json文件下的JavaScript:
{ "name": "reader-api", "main": "server.js", "dependencies": { "express" : "~4.10.0", "stormpath" : "~0.7.5", "express-stormpath" : "~0.5.9", "mongodb" : "~1.4.26”, "mongoose" : "~3.8.0", "body-parser" : "~1.10.0”, "method-override" : "~2.3.0", "morgan" : "~1.5.0”, "winston" : "~0.8.3”, "express-winston" : "~0.2.9", "validator" : "~3.27.0", "path" : "~0.4.9", "errorhandler" : "~1.3.0", "frisby" : "~0.8.3", "jasmine-node" : "~1.14.5", "async" : "~0.9.0" } } 应用程序被命名为reader-api,主文件被命名为server.js,随后会是一系列的依赖库和它们的版本。这些库其中的一些被设计用来解析HTTP查询。在这里,我们会使用frisby作为测试工具,而jasmine-node则被用来运行frisby脚本。
在这些库中,async尤为重要。如果你从未使用过node.js,那么请注意node.js使用的是异步机制。因此,任何阻塞input/output (I/O)的操作(比如从socket中读取或者1个数据库查询)都会采用一个回调函数作为最后的参数,然后继续控制流,只有在阻塞操作结束后才会继续这个回调函数。下面看一个简单的例子来理解这一点。
function foo() { someAsyncFunction(params, function(err, results) { console.log(“one”); }); console.log(“two”); } 在上面这个例子中,你想象中的输出可能是:
但实际情况的输出是:
造成这个结果的原因就是Node.js使用的异步机制,打印 “one” 的代码可能会在后续的回调函数中执行。之所以说可能,是因为这只在一定的情景下发生。这种异步编程带来的不确定性被称之为non-deterministic execution。对于许多编程任务来说,这么做可以获得很高的性能,但是在顺序性要求的场景则非常麻烦。而通过下面的用法则可以获得一个理想中的顺序:
actionArray = [ function one(cb) { someAsyncFunction(params, function(err, results) { if (err) { cb(new Error(“There was an error”)); } console.log(“one”); cb(null); }); }, function two(cb) { console.log(“two”); cb(null); } ] async.series(actionArray); 总结
通过本篇文章,相信大家对Node.js和异步函数设置都有了一定的理解,因此下篇博文将会描述更深入层次的一些知识。取代开始建立应用程序,这里会进入建立测试以及验证应用程序的行为。这种方式则被称为test-driven 开发,它会带来两大好处:
首先,它会帮助开发者弄清数据和函数的消费方式,同时也可以帮助弄清一些奇怪的需求,比如数组中会储存多个对象。
通过在建立应用程序之前编写测试,模型会从“assumed to be working until a test fails”转换成“broken / unimplemented until proven tested OK”。对于建立一个更健壮的应用程序来说,前者显然更安全些。
PS:点击 下一页 访问第2部分。
原文链接: Building your first application with MongoDB: Creating a REST API using the MEAN Stack - Part 1 (翻译/ OneAPM 工程师,责编/仲浩)
正文到此结束
- 本文标签: rmi 测试 js map SOA 需求 Document 参数 src 目录 翻译 https sql 管理 代码 parse REST lib mysql 协议 git 安全 Facebook HTML5 解析 软件 build linux 服务器 ip 网站 IDE GitHub MongoDB value example PHP mail cat 数据 Node.js Android key Uber web db 数据库 开发者 SDN HTML XML 总结 apache node description UI Google App Collections 开发 java windows 安装 API Apple json dependencies DDL
- 版权声明: 本文为互联网转载文章,出处已在文章中说明(部分除外)。如果侵权,请联系本站长删除,谢谢。
- 本文海报: 生成海报一 生成海报二
热门推荐










相关文章

近期评论
-
你这基本没有更新呀,最近文章显示还是2019年的文章。不符合要求哈
-
关键词:慕云博客 链接:https://www.lilun.me 描述:分享原创文字的个人博客
-
-
-
可以提供一下源码吗
-
不是商业站,鸡娃学习笔记
-
-
-
-
听他们说很厉害的样子
Loading...
![[HBLOG]公众号](http://www.liuhaihua.cn/img/qrcode_gzh.jpg)

