SQL Server里ORDER BY的歧义性
在今天的文章里,我想谈下SQL Server里非常有争议和复杂的话题:ORDER BY子句的歧义性。
视图与ORDER BY
我们用一个非常简单的SELECT语句开始。
1 -- A very simple SELECT statement 2 SELECT * FROM Person.Person 3 ORDER BY LastName 4 GO
从刚才列出的代码你可以看到,我们只想从Person.Person表以LastName列排序返回记录。因为我们想能尽可能简单的重用那个SQL语句,最后我们把它放到视图里,如下:
1 -- This doesn't work 2 CREATE VIEW v_Persons 3 AS 4 SELECT * FROM Person.Person 5 ORDER BY LastName 6 GO
但是你会看到,SQL Server不能创建那个视图,只返回一个错误信息:
 这个错误信息告诉你,的那个你不使用TOP,OFFSET或FOR XML表达式时,在视图里你不允许使用ORDER BY子句。基于那个错误信息,我们可以通过增加TOP 100 PERCENT子句到视图里在轻松修正问题。
这个错误信息告诉你,的那个你不使用TOP,OFFSET或FOR XML表达式时,在视图里你不允许使用ORDER BY子句。基于那个错误信息,我们可以通过增加TOP 100 PERCENT子句到视图里在轻松修正问题。
1 -- Let's make it work! 2 CREATE VIEW v_Persons 3 AS 4 SELECT TOP 100 PERCENT * FROM Person.Person 5 ORDER BY LastName 6 GO
现在视图创建没有任何问题!我们对视图执行一个SELECT语句。
1 SELECT * FROM v_Persons 2 GO
SELECT语句本身可以执行,但当你看返回的数据时,疯狂的事情发生了:返回的数据没有按LastName列排序——SQL Server按BusinessEntityID——表上的聚集键列排序!
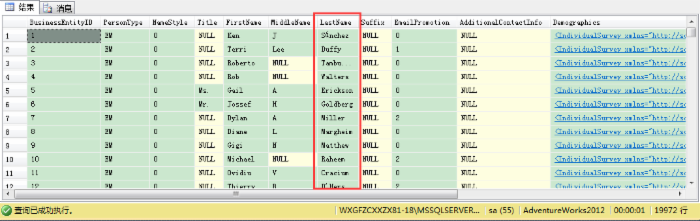
这是SQL Server里的BUG么?不,并不是——它是“故意的”!我们来解释下为什么。首先你要知道ORDER BY子句在SQL(编程语言本身)里用2个不同的上下文:
- 使用 ORDER BY 子句你可以定义返回给你客户端程序的排序
- 另外 ORDER BY 子句用来定义从TOP表达式哪些行返回
你必须知道的最重要的事情是,你用视图定义了所谓的 集合(Set) ,行内函数,派生表,子查询和通用表表达式(common table expressions(CTE))。集合是数学上的概念,关系数据库(例如SQL Server)上 集合论(Set Theory) 的组成。集合本身是没有排序的。因此用视图定义与 ORDER BY 组合是不允许的——如你刚才所见。如果你尝试这样做,SQL Server不允许你这样做并给你一个错误信息。
当然你可以在与 TOP 表达式里组合使用 ORDER BY 。但基本上你在愚弄SQL Server和你自己,因为 ORDER BY 没有告诉SQL Server要以怎样的排序返回数据给客户端程序。假设你使用 TOP 10 PERCENT 。表的前10%是什么?你需要确定性的方式里定义排序。
而且因为我们必须使用TOP 100 PERCENT与ORDER BY组合,查询优化器实际上在执行计划里不会引入排序运算符。TOP 100 PERCENT意味着一切,因此如你在下图所看到的,在执行计划里TOP运算符不需要排序输入。
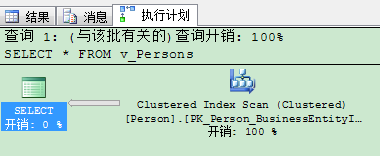
在这个例子里,我们的返回行以从内在数据结构读取的排序。这由SQL Server的存储引擎来决定返回行的排序。这里我们从聚集索引里读取行。因此我们拿到的数据按BusinessEntityID排序,这是索引列里聚集键值。
现在我们修改下视图定义,从Person.Person表值返回10%的行。我们还是指定了ORDER BY子句。
1 -- Alter the view 2 ALTER VIEW v_Persons 3 AS 4 SELECT TOP 10 PERCENT * FROM Person.Person 5 ORDER BY LastName 6 GO
当你现在看结果集时,你会看到返回的行按LastName列排序的。现在才对了,因为你在执行计划里看到了排序运算符(SQL Server 2014里没有出现),因为TOP运算符最后能返回提供输入行的前10%的数据。
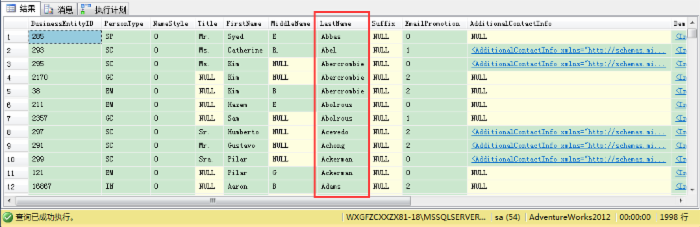

当然你可以通过ORDER BY子句在你引用的视图里按不同的排序返回10%的行给你的客户端程序。
1 SELECT * FROM v_Persons 2 ORDER BY FirstName 3 GO
现在当你看执行计划时,你会在计划里看到2个(SQL Server 2014里只有1个)。
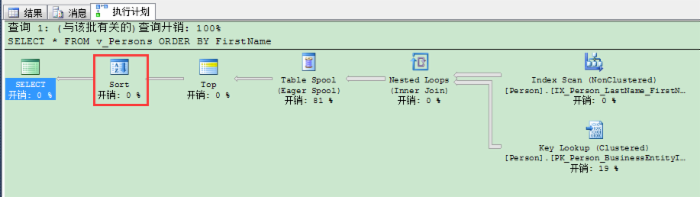
第1个(右边)排序运算符为TOP运算符预排序(返回前10%)。第2个(左边)排序运算符用来最后定义的排序,返回给客户端程序。当你通过添加TOP 100 PERCENT来定义的视图里强制ORDER BY——你基本上就在愚弄SQL Server……
没有ORDER BY的TOP
另一个问题是没有ORDER BY子句的TOP表达式不会提供你确定性的结果。我们可以用具体的例子演示下这个问题。假设有下列SELECT语句:
1 SELECT TOP 1 LastName FROM Person.Person 2 GO
这个SQL语句用 TOP 1 表达式返回Person.Person表的第一行——没有用ORDER BY子句定义排序。这个排序是基于执行计划里选择的索引。在这个例子里SQL Server返回你“Abbas”给你作为结果,因为这是执行计划里查询优化器选择非聚集索引里第1条可用记录。
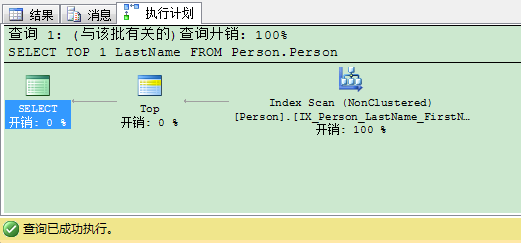
因此从这个查询返回的第1条记录取决于执行计划里选择的索引。如果现在我们把非聚集索引停用呢。
1 -- Let's deactivate this index 2 ALTER INDEX [IX_Person_LastName_FirstName_MiddleName] ON Person.Person 3 DISABLE 4 GO
然后当你再次执行刚才的SELECT语句,SQL Server返回你Sánchez值,意味只是在执行计划里现在选择的聚集索引的第1条记录。SQL Server从聚集索引里返回了用BusinessEntityID值为1的第1行。
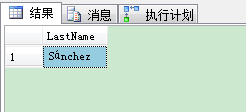
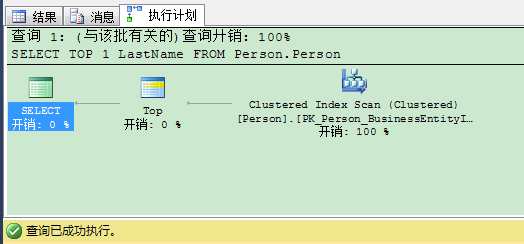
因此你与非确定性记录打交道时:你的结果取决与执行计划里选择的索引!你可以通过增加 ORDER BY 子句来轻松实现查询结果排序的明确性。在这个情况下 ORDER BY 子句为 TOP 表达式使记录确定——这样话在执行计划里你会有 Sort(Top N Sort) 的运算符。
1 SELECT TOP 1 LastName FROM Person.Person 2 ORDER BY LastName 3 GO
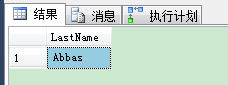
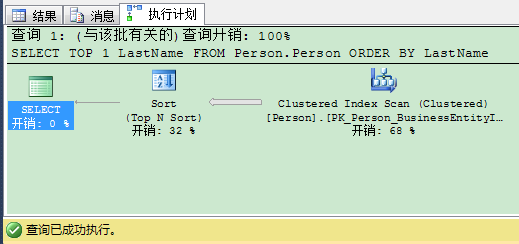
在执行计划里,SQL Server从哪个索引读取行并不重要—— Sort(Top N Sort) 的运算符在执行计划里会物理预排序行,并从它返回第N行——很简单,是不是?
小结
在SQL(编程语言本身)里 ORDER BY 子句并不是一个最简单的概念。如你在这篇文章里所学的, ORDER BY 使用2个不同的上下文,因此你总要考虑下你要使用哪个上下文。永远不要在视图定义里增加 TOP 100 PERCENT 来愚弄SQL Server和你自己——它不会在最终的记录集里体现排序。
感谢关注!
正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](http://www.liuhaihua.cn/img/qrcode_gzh.jpg)

