Autodesk 是如何在 Mesos 上实现可扩展事件的
【编者的话】这是一篇 Olivier Paugam 写的客座文章。我非常喜欢这篇文章,因为它说明了如何将 Mesos、Kafka、RabbitMQ、Akka、Splunk、Librato、EC2 这些基础组件结合起来去解决实际问题。一个小团队现在就能完成这么多的工作确实了不起。
几个月前我被分配去提出一个可以让不同后端彼此互相通信的中心事件系统。这些后端包括活动流后端,渲染,数据转换,BIM,身份,日志报表,分析等等,也包括一些通用的可变负载,使用模式和扩展配置文件,而且我们工程团队能够轻松连接。当然这个系统的每一个部分都应该能够自行扩展。
我当然没有时间去写大量的代码就选择了 Kafka 作为我们的核心存储,因为它稳定,使用广泛,运行正常(注意我并没有说一定要使用它,可以使用其它的)。现在我当然不能直接使用它,必须在前端封装一些 API。因为它在处理失败的实例上有太多的局限性,所以我也拒绝了让后端管理偏移量的想法。
那我最终是怎么做的呢?用两个独立的层:首先一个API层处理传入流量,然后一个后端层维持一个持久的与 Kafka 通信的状态流进程(例如实现生产者和消费者的进程)。这两个层可以独立扩展,只是要求它们之间保持同一路由以保证客户端和相同的后端流进程保持通信。
这些层完全是用 Scala 实现的而且使用了 Play! framework ,同时它们依赖 Akka actor system (通常每个节点运行几百个 actor)。后端层实现了一组自定义的 Kafka 生产者和消费者,同时利用一组专用的 actor 去管理预读取与写缓冲区。一切都被实现为嵌套的有限状态机(我爱这个概念)。分析的话去用 Splunk ,统计度量用 Librato (用来收集正在运行的容器的参数)。

那么我是如何让这两层之间通信呢?简单地可以用持久,弹性的 RabbitMQ 。而 AMQP 队列是一个实现这个简单的“phone-switch”模式的好方法。同时通过使用某种 logical sharding 来扩展这个模式,而这种logical sharding 可以将一个 RabbitMQ 代理关联到一组固定的后端节点,这个花费的代价是微不足道的。
为什么不将 RabbitMQ 代理放在一起呢?主要是因为我懒而且没有必要。在我看来,Sharding traffic 在个别代理中是有效且易于控制的。相比好处,做额外的工作不值一提。
总之,请求会根据什么节点承载什么样的流会话来选择特定的路径,如下面所给的容器拓扑图。扩展整个系统和单独扩展你需要的每一层是同样微不足道的。唯一的实际局限来自于你的虚拟网络适配器和带宽。
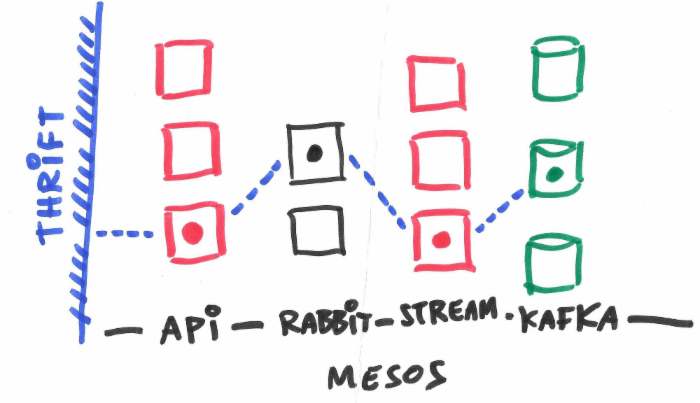
虚线表示来自会话的请求要走的路径
现在到了有趣的部分:我们如何保证可靠通信和避免拜占庭式的失败?要我说很简单,只要去用一个简单地两个阶段的提交式协议,把客户端和后端的两个模型作为镜像状态机就可以了(例如,它们总是同步的)。这可以由具有显式确认请求的读写操作来完成。当你试图去读,如果失败了你只需重新请求,直到你得到一个确认。所以客户端和后端的通信非常像这样:“allocate session”,“read”,“ack”,“read”,“ack” ... “dispose”。
这个系统最大的好处在于你可以有效地提交你的幂等操作,同时你可以对所有的状态机里的逻辑进行编码而不需要任何恼人的声明。当然出现任何网络故障都要重新请求。你也可以通过这种方式得到免费控制流和背压(back-pressure)。
这整个系统都作为 Apache Thrift API 公开了。我有 Python、Scala、.NET 与 Ruby 的客户端 SDK 和一些我们在 Autodesk 里用到的各种不同的技术。请注意 Kafka 的偏移量由客户端管理,这使得后端更加容易管理。
你们是如何处理后端节点宕掉的情况呢?多亏两阶段(2-phase)协议,我们在读取数据时不需要考虑:当客户端得到重复的失败时会用现在的偏移量重新分配一个流会话。当写数据到 Kafka时问题来了,因为这是异步的,并可能受到下游背压。我给后端节点配置了一个优雅的关闭系统,当等待去检查任何挂起的写操作时,它可以快速地屏蔽传入的请求。在最后一个阶段,我们甚至可以将任何待处理的数据写到磁盘中。
如果部分基础设施坏掉了怎么办呢?当然任何客户端和处理流会话的后端节点之间的通信中断都会减慢速度,但是不会产生糟糕的影响因为有两阶段(2-phase)协议。
哦,我忘了补充静态数据在进入 Kafka 日志前是自动加密的(用 AES 256)。在安全问题上,我补充一点,我们的流会话是通过 OAUTH2 验证的,使用 MD5-HMAC 处理过请求,后端集群通信用TLS。
那么我们是如何部署这个流行的系统的呢?我们将它完全运行在一个简单的 Mesos/Marathon 集群中。现在这个集群托管在 AWS EC2 上,而且基本上在少数 c3.2xlarge 实例上复用这个系统(对于小规模部署,10到20个实例足够了)。请注意我们可以在 Kubernetes 上做同样的事情。

结构栈
所有的部署使用我们的 Ochopod 技术,它同样是开源的。部署操作被减少到最少。例如 API 层只是做了分配新的容器,等待它们运行起来,然后逐步淘汰旧的容器这些事情。所有这些是通过一个运行在集群上的专用的 Jenkins 从节点完成的。
我确实开发了 Ochothon mini-PaaS 仅仅是为了能够快速 dev/ops 那些容器。

其中一个生产环境的 Ochothon 命令行
给你说了这么多 Ocho-* 平台多么有用,而我只是想说一个人(像我这样)也可以在 2 个区域包括所有复制基础设施,管理 5 个系统的部署,而且仍然可以用时间写博客,写代码!
总的来说,设计和编码整个系统非常有趣,更何况它作为我们云基础架构的关键的一部分目前正运行在生产环境。如果你想了解更多关于这个带有异国情调的流系统那就请让我们知道。
原文链接: How Autodesk Implemented Scalable Eventing Over Mesos (翻译:叶振安)
正文到此结束
热门推荐










相关文章

近期评论
-
你这基本没有更新呀,最近文章显示还是2019年的文章。不符合要求哈
-
关键词:慕云博客 链接:https://www.lilun.me 描述:分享原创文字的个人博客
-
-
-
可以提供一下源码吗
-
不是商业站,鸡娃学习笔记
-
-
-
-
听他们说很厉害的样子
Loading...
![[HBLOG]公众号](http://www.liuhaihua.cn/img/qrcode_gzh.jpg)

