Spark入门实战系列--5.Hive(下)--Hive实战
【注】该系列文章以及使用到安装包/测试数据 可以在《 倾情大奉送--Spark入门实战系列 》获取
1、 Hive 操作演示
1.1 内部表
1.1.1 创建表并加载数据
第一步 启动 HDFS 、 YARN 和 Hive ,启动完毕后创建 Hive 数据库
hive>create database hive;
hive>show databases;
hive>use hive;

第二步 创建内部表
由于 Hive 使用了类似 SQL 的语法,所以创建内部表的语句相对 SQL 只增加了行和字段分隔符。
hive>CREATE TABLE SOGOUQ2(DT STRING,WEBSESSION STRING,WORD STRING,S_SEQ INT,C_SEQ INT,WEBSITE STRING) ROW FORMAT DELIMITED FIELDS TERMINATED BY '/t' LINES TERMINATED BY '/n' ;

第三步 加载数据
数据文件可以从 HDFS 或者本地操作系统加载到表中,如果加载 HDFS 文件使用 LOAD DATA INPATH ,而加载本地操作系统文件使用 LOAD DATA LOCAL INPATH 命令。 HIVE 表保存的默认路径在 ${HIVE_HOME}/conf/hive-site.xml 配置文件的 hive.metastore.warehouse.dir 属性指定,当创建表时会在 hive.metastore.warehouse.dir 指向的目录下以表名创建一个文件夹,在本演示中表默认指向的是 /user/hive/warehouse 。
数据文件在本地操作系统将复制到表对应的目录中,而数据文件在 HDFS 中,数据文件将移动到表对应的目录中,原来的路径将不存在该文件。在这里使用《 Spark 编程模型(上) -- 概念及 Shell 试验》中在本地操作系统中的搜狗日志数据文件:
hive>LOAD DATA LOCAL INPATH '/home/hadoop/upload/sogou/SogouQ2.txt' INTO TABLE SOGOUQ2;

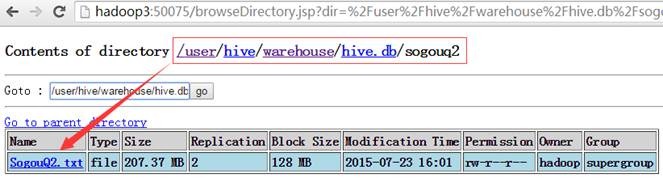
在 /user/hive/warehouse/hive.db/sogouq2 目录下,可以看到 SougouQ2.txt 数据文件:
1.1.2 查询行数
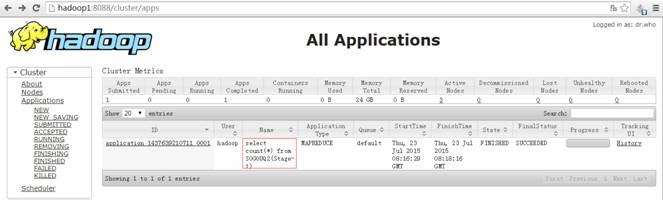
可以用 count 关键字查询 SogouQ2.txt 数据行数,查询时会启动 MapReduce 进行计算, Map 的个数一般和数据分片个数对应,在本查询中有 2 个 Map 任务(数据文件有 2 个 Block ), 1 个 Reduce 任务。
hive>select count(*) from SOGOUQ2;

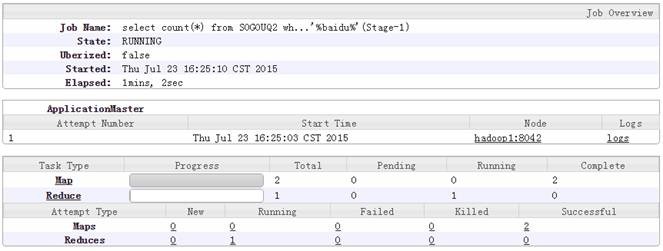
1.1.3 包含 baidu 的数据
可以用 like 关键字进行模糊查询, Map 的个数一般和数据分片个数对应。
hive>select count(*) from SOGOUQ2 where WEBSITE like '%baidu%';

1.1.4 查询结果排名第 1 ,点击次序排第 2 ,其中 URL 包含 baidu 的数据
hive>select count(*) from SOGOUQ2 where S_SEQ=1 and C_SEQ=2 and WEBSITE like '%baidu%';

1.2 外部表
1.2.1 创建表关联数据
第一步 在 HDFS 创建外部表存放数据目录
$hadoop fs -mkdir -p /class5/sogouq1
$hadoop fs -ls /class5

第二步 在 Hive 创建外部表,指定表存放目录
hive>CREATE EXTERNAL TABLE SOGOUQ1(DT STRING,WEBSESSION STRING,WORD STRING,S_SEQ INT,C_SEQ INT,WEBSITE STRING) ROW FORMAT DELIMITED FIELDS TERMINATED BY '/t' LINES TERMINATED BY '/n' STORED AS TEXTFILE LOCATION '/class5/sogouq1';
hive>show tables;
观察一下创建表和外部表的区别,会发现创建外部表多了 EXTERNAL 关键字以及指定了表对应存放文件夹 LOCATION ‘ /class5/sogouq1 ’
【注】在删除表的时候,内部表将删除表的元数据和数据文件;而删除外部表的时候,仅仅删除外部表的元数据,不删除数据文件

第三步 加载数据文件到外部表对应的目录中
创建 Hive 外部表关联数据文件有两种方式,一种是把外部表数据位置直接关联到数据文件所在目录上,这种方式适合数据文件已经在 HDFS 存在,另外一种方式是创建表时指定外部表数据目录,随后把数据加载到该目录下。以下将以第二种方式进行演示:
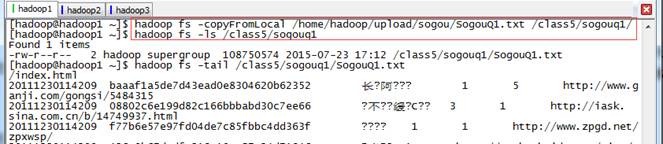
$hadoop fs -copyFromLocal /home/hadoop/upload/sogou/SogouQ1.txt /class5/sogouq1/
$hadoop fs -ls /class5/sogouq1
$hadoop fs -tail /class5/sogouq1/SogouQ1.txt

1.2.2 查询行数
hive>select count(*) from SOGOUQ1;
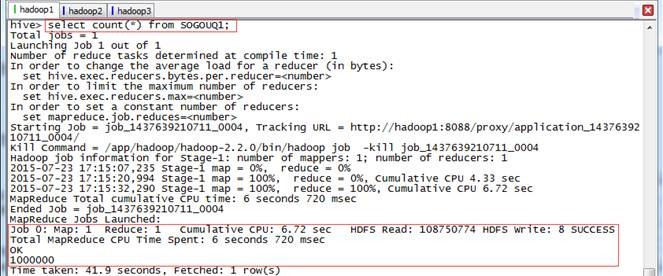

1.2.3 显示前 10 行
hive>select * from SOGOUQ1 limit 10;
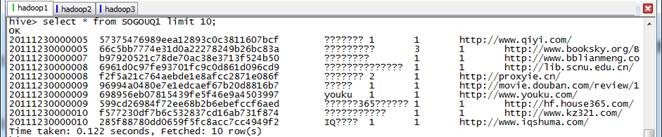
可以看出 Hive 会根据查询不同任务决定是否生成 Job ,获取前 10 条并没有生成 Job ,而是得到数据后直接进行显示。
1.2.4 查询结果排名第 1 ,点击次序排第 2 的数据
hive>select count(*) from SOGOUQ1 where S_SEQ=1 and C_SEQ=2;
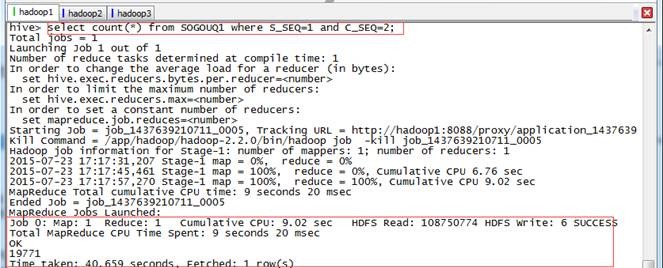
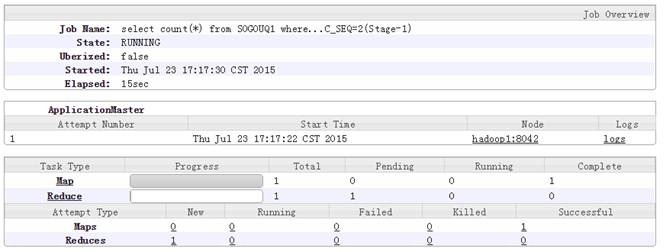
1.2.5 查询次数排行榜
按照 session 号进行归组,并按照查询次数进行排序,最终显示查询次数最多的前 10 条。
hive>select WEBSESSION,count(WEBSESSION) as cw from SOGOUQ1 group by WEBSESSION order by cw desc limit 10;

2 、 交易数据 演示
2.1 准备数据
2.1.1 上传数据
交易数据存放在该系列配套资源的 /class5/saledata 目录下,在 /home/hadoop/upload 创建 class5 目录用于存放本周测试数据
$cd /home/hadoop/upload
$mkdir class5
创建新文件夹后使用,使用 SSH Secure File Transfer 工具上传到 /home/hadoop/upload/class5 目录下,如下图所示:

2.1.2 在 Hive 创建数据库和表
启动 Hadoop 集群,进入 Hive 命令行操作界面,使用如下命令创建三张数据表 :
l tbDate 定义了日期的分类,将每天分别赋予所属的月份、星期、季度等属性,字段分别为日期、年月、年、月、日、周几、第几周、季度、旬、半月 ;
l tbStock 定义了订单表头,字段分别为订单号、交易位置、交易日期 ;
l tbStockDetail 文件定义了订单明细 ,该表和 tbStock 以交易号进行关联,字段分别为 订单号、行号、货品、数量、金额 :
hive>use hive;
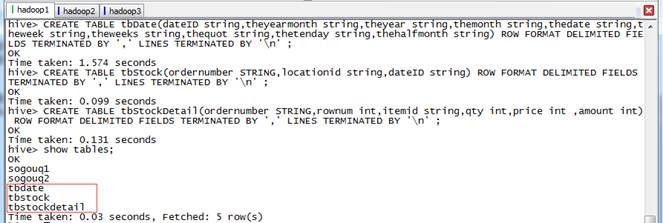
hive>CREATE TABLE tbDate (dateID string,theyearmonth string,theyear string,themonth string,thedate string,theweek string,theweeks string,thequot string,thetenday string,thehalfmonth string) ROW FORMAT DELIMITED FIELDS TERMINATED BY ',' LINES TERMINATED BY '/n' ;
hive>CREATE TABLE tbStock (ordernumber STRING,locationid string,dateID string) ROW FORMAT DELIMITED FIELDS TERMINATED BY ',' LINES TERMINATED BY '/n' ;
hive>CREATE TABLE tbStockDetail (ordernumber STRING,rownum int,itemid string,qty int,price int ,amount int) ROW FORMAT DELIMITED FIELDS TERMINATED BY ',' LINES TERMINATED BY '/n' ;
2.1.3 导入数据
从本地操作系统分别加载日期、交易信息和交易详细信息表数据
hive>use hive;
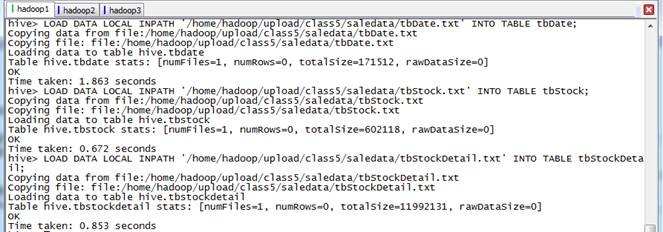
hive>LOAD DATA LOCAL INPATH '/home/hadoop/upload/class5/saledata/tbDate.txt' INTO TABLE tbDate;
hive>LOAD DATA LOCAL INPATH '/home/hadoop/upload/class5/saledata/tbStock.txt' INTO TABLE tbStock;
hive>LOAD DATA LOCAL INPATH '/home/hadoop/upload/class5/saledata/tbStockDetail.txt' INTO TABLE tbStockDetail;
查看 HDFS 中相关 SALEDATA 数据库中增加了三个文件夹,分别对应三个表:

2.2 计算所有订单每年的总金额
2.2.1 算法分析
要计算所有订单每年的总金额,首先需要获取所有订单的订单号、订单日期和订单金信息,然后把这些信息和日期表进行关联,获取年份信息,最后根据这四个列按年份归组统计获取所有订单每年的总金额。
2.2.2 执行 HSQL 语句
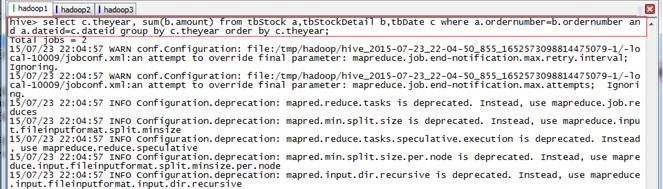
hive>use hive;
hive>select c.theyear, sum(b.amount) from tbStock a,tbStockDetail b,tbDate c where a.ordernumber=b.ordernumber and a.dateid=c.dateid group by c.theyear order by c.theyear;
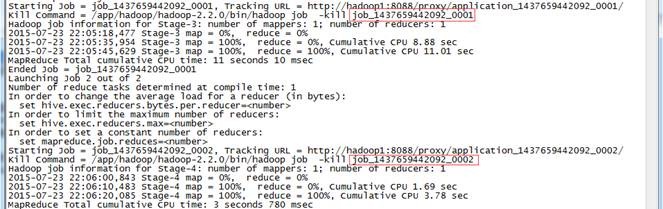
运行过程中创建两个 Job ,分别为 job_1437659442092_0001 和 job_1437659442092_0002 ,运行过程如下:
在 YARN 的资源管理器界面中可以看到如下界面:
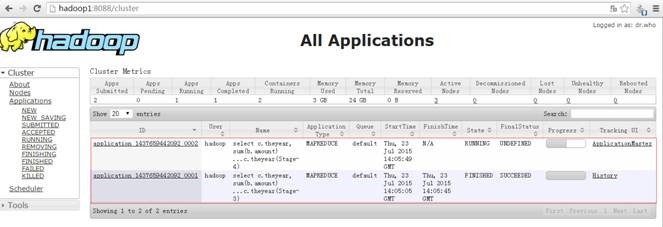
2.2.3 查看结果
整个计算过程使用了 91.51 秒,结果如下:

2.3 计算所有订单每年最大金额订单的销售额
2.3.1 算法分析
该算法分为两步:
1. 按照日期和订单号进行归组计算,获取所有订单每天的销售数据;
2. 把第一步获取的数据和日期表进行关联获取的年份信息,然后按照年份进行归组,使用 Max 函数,获取所有订单每年最大金额订单的销售额。
2.3.2 执行 HSQL 语句
// 所有订单每年最大金额订单的销售额
// 第一步:
hive>use hive;
hive>select a.dateid,a.ordernumber,sum(b.amount) as sumofamount from tbStock a,tbStockDetail b where a.ordernumber=b.ordernumber group by a.dateid,a.ordernumber;
// 第二步 :
hive>select c.theyear,max(d.sumofamount) from tbDate c,(select a.dateid,a.ordernumber,sum(b.amount) as sumofamount from tbStock a,tbStockDetail b where a.ordernumber=b.ordernumber group by a.dateid,a.ordernumber) d where c.dateid=d.dateid group by c.theyear sort by c.theyear;
运行过程中创建两个 Job ,分别为 job_1437659442092_0004 和 job_1437659442092_0005 ,运行过程如下:


在 YARN 的资源管理器界面中可以看到如下界面:
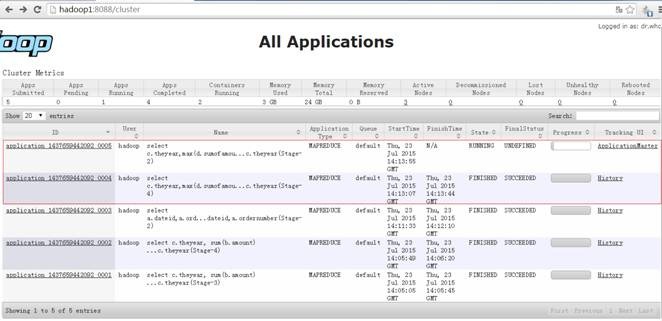
其中 job_1437659442092_0005 运行的具体情况如下:
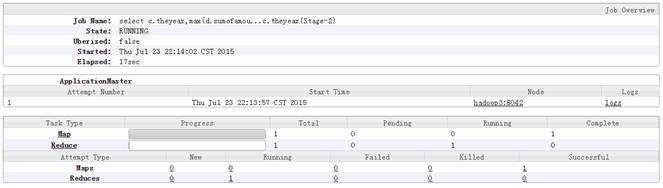
2.3.3 查看结果
整个计算过程使用了 285 秒,结果如下:
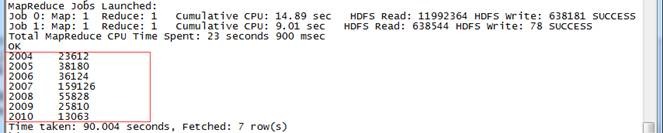
2.4 计算其他金额
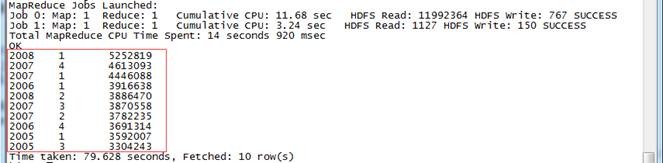
2.4.1 所有订单中季度销售额前 10 位
// 所有订单中季度销售额前 10 位
hive>use hive;
hive>select c.theyear,c.thequot,sum(b.amount) as sumofamount from tbStock a,tbStockDetail b,tbDate c where a.ordernumber=b.ordernumber and a.dateid=c.dateid group by c.theyear,c.thequot order by sumofamount desc limit 10;
2008 1 5252819
2007 4 4613093
2007 1 4446088
2006 1 3916638
2008 2 3886470
2007 3 3870558
2007 2 3782235
2006 4 3691314
2005 1 3592007
2005 3 3304243

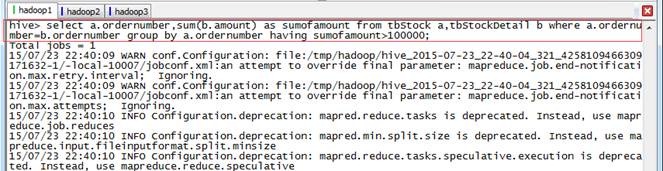
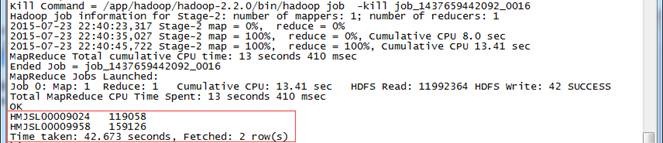
2.4.2 列出销售金额在 100000 以上的单据
// 列出销售金额在 100000 以上的单据
hive>use hive;
hive>select a.ordernumber,sum(b.amount) as sumofamount from tbStock a,tbStockDetail b where a.ordernumber=b.ordernumber group by a.ordernumber having sumofamount>100000;
2.4.3 所有订单中每年最畅销货品
// 所有订单中每年最畅销货品
第一步:
hive>use hive;
hive>select c.theyear,b.itemid,sum(b.amount) as sumofamount from tbStock a,tbStockDetail b,tbDate c where a.ordernumber=b.ordernumber and
a.dateid=c.dateid group by c.theyear,b.itemid;
第二步 :
hive>select d.theyear,max(d.sumofamount) as maxofamount from (select c.theyear,b.itemid,sum(b.amount) as sumofamount from tbStock a,tbStockDetail b,tbDate c where a.ordernumber=b.ordernumber and a.dateid=c.dateid group by c.theyear,b.itemid) d group by d.theyear ;
第三步:
hive>select distinct e.theyear,e.itemid,f.maxofamount from (select c.theyear,b.itemid,sum(b.amount) as sumofamount from tbStock a,tbStockDetail b,tbDate c where a.ordernumber=b.ordernumber and a.dateid=c.dateid group by c.theyear,b.itemid) e , (select d.theyear,max(d.sumofamount) as maxofamount from (select c.theyear,b.itemid,sum(b.amount) as sumofamount from tbStock a,tbStockDetail b,tbDate c where a.ordernumber=b.ordernumber and a.dateid=c.dateid group by c.theyear,b.itemid) d group by d.theyear) f where e.theyear=f.theyear and e.sumofamount=f.maxofamount order by e.theyear;
2004 JY424420810101 53374
2005 24124118880102 56569
2006 JY425468460101 113684
2007 JY425468460101 70226
2008 E2628204040101 97981
2009 YL327439080102 30029
2010 SQ429425090101 4494


正文到此结束
热门推荐










相关文章

近期评论
-
你这基本没有更新呀,最近文章显示还是2019年的文章。不符合要求哈
-
关键词:慕云博客 链接:https://www.lilun.me 描述:分享原创文字的个人博客
-
-
-
可以提供一下源码吗
-
不是商业站,鸡娃学习笔记
-
-
-
-
听他们说很厉害的样子
Loading...
![[HBLOG]公众号](http://www.liuhaihua.cn/img/qrcode_gzh.jpg)

