安全漏洞是如何造成的:缓冲区溢出
自1988年莫里斯蠕虫诞生以来,缓冲区溢出漏洞就威胁着从Linux到Windows的各类系统环境。
缓冲区溢出漏洞长久以来一直是计算机安全领域的一大特例。事实上,世界上首个能够自我传播的互联网蠕虫——诞生于1988年的莫里斯蠕虫——就是通过Unix系统中的守护进程利用缓冲区溢出实现传播的。而在二十七年后的今天,缓冲区溢出仍然在一系列安全隐患当中扮演着关键性角色。声威显赫的Windows家族就曾在2000年初遭遇过两次基于缓冲区溢出的成规模安全侵袭。而就在今年5月,某款Linux驱动程序中遗留的潜在缓冲区溢出漏洞更是让数百万台家庭及小型办公区路由设备身陷风险之中。

但颇为讽刺的是,作为一种肆虐多年的安全隐患,缓冲区溢出漏洞的核心却只是由一种实践性结果衍生出的简单bug。计算机程序会频繁使用多组读取自某个文件、网络甚至是源自键盘输入的数据。程序为这些数据分配一定量的内存块——也就是缓冲区——作为存储资源。而所谓缓冲区漏洞的产生原理就是,写入或者读取自特定缓冲区的数据总量超出了该缓冲区所能容纳量的上限。
事实上,这听起来像是一种相当愚蠢、毫无技术含量的错误。毕竟程序本身很清楚缓冲区的具体大小,因此我们似乎能够很轻松地确保程序只向缓冲区发送不超出上限的数据量。这么想确实没错,但缓冲区溢出仍在不断出现,并始终成为众多安全攻击活动的导火线。
为了了解缓冲区溢出问题的发生原因——以及为何其影响如此严重——我们需要首先谈谈程序是如何使用内存资源以及程序员是如何编写代码的。(需要注意的是,我们将以堆栈缓冲区溢出作为主要着眼对象。虽然这并不是惟一一种溢出问题,但却拥有着典型性地位以及极高的知名度。)
堆叠起来
缓冲区溢出只会给原生代码造成影响——也就是那些直接利用处理器指令集编写而成的程序,而不会影响到利用Java或者Python等中间开发机制构建的代码。不同操作系统有着自己的特殊处理方式,但目前各类常用系统平台则普遍遵循基本一致的运作模式。要了解这些攻击是如何出现的,进而着手阻止此类攻击活动,我们首先要了解内存资源的使用机制。
在这方面,最重要的核心概念就是内存地址。内存当中每个独立的字节都拥有一个与之对应的数值地址。当处理器从主内存(也就是RAM)中加载或者向其中写稿数据时,它会利用内存地址来确定读取或写入所指向的位置。系统内存并不单纯用于承载数据,它同时也被用于执行那些构建软件的可执行代码。这意味着处于运行中的程序,其每项功能都会拥有对应的地址。
在计算机制发展的早期阶段,处理器与操作系统使用的是物理内存地址:每个内存地址都会直接与RAM中的特定位置相对应。尽管目前某些现代操作系统仍然会有某些组成部分继续使用这类物理内存地址,但现在所有操作系统都会在广义层面采用另一种机制——也就是虚拟内存。
在虚拟内存机制的帮助下,内存地址与RAM中物理位置直接对应的方式被彻底打破。相反,软件与处理器会利用虚拟内存地址保证自身运转。操作系统与处理器配合起来共同维护着一套虚拟机内存地址与物理内存地址之间的映射机制。
这种虚拟化方式带来了一系列非常重要的特性。首先也是最重要的,即“受保护内存”。具体而言,每项独立进程都拥有属于自己的地址集合。对于一个32位进程而言,这部分对应地址从0开始(作为首个字节)一直到4294967295(在十六进制下表示为0xffff'ffff; 232 - 1)。而对于64位进程,其能够使用的地址则进一步增加至18446744073709551615(十六进制中的0xffff'ffff'ffff'ffff, 264 - 1)。也就是说,每个进程都拥有自己的地址0,自己的地址1、地址2并以此类推。
(在文章的后续部分,除非另行强调,否则我将主要针对32位系统进行讲解。其实32位与64位系统的工作机理是完全相同的,因此单独着眼于前者不会造成任何影响,这只是为了尽量让大家将注意力集中在单一对象身上。)
由于每个进程都拥有自己的一套地址,而这种规划就以一种非常简单的方式防止了不同进程之间相互干扰:一个进程所能使用的全部参考内存地址都将直接归属于该进程。在这种情况下,进程也能够更轻松地完成对物理内存地址的管理。值得一提的是,虽然物理内存地址几乎遵循同样的工作原理(即以0为起始字节),但实际使用中可能带来某些问题。举例来说,物理内存地址通常是非连续的;地址0x1ff8'0000被用于处理器的系统管理模式,而另有一小部分物理内存地址会作为保留而无法被普通软件所使用。除此之外,由PCIe卡提供的内存资源一般也要占用一部分地址空间。而在虚拟地址机制中,这些限制都将不复存在。
那么进程会在自己对应的地址空间中藏进什么小秘密呢?总体来讲,大致有四种觉类别,我们会着重讨论其中三种。这惟一一种不值得探讨的也就是大多数操作系统所必不可少的“操作系统内核”。出于性能方面的考量,内存地址空间通常会被拆分为两半,其中下半部分为程序所使用、上半部分由作为系统内核的专用地址空间。内核所占用的这一半内存无法访问程序那一半的内容,但内核自身却可以读取程序内存,这也正是数据向内核功能传输的实现原理。
我们首先需要关注的就是构建程序的各类可执行代码与库。主可执行代码及其全部配套库都会被载入到对应进程的地址空间当中,而且所有组成部分都拥有自己的对应内存地址。
其次就是程序用于存储自身数据的内存,这部分内存资源通常被称为heap、也就是内存堆。举例来说,内存堆可以用于存储当前正在编辑的文档、浏览的网页(包括其中的全部JavaScript对象、CSS等等)或者当前游戏的地图资源等等。
第三也是最重要的一项概念即call stack,即调用堆——也简称为栈。内存栈可以说是最复杂的相关概念了。进程中的每个分线程都拥有自己的内存栈。栈其实就是一个内存块,用于追踪某个线程当前正在运行的函数以及所有前趋函数——所谓前趋函数,是指那些当前函数需要调用的其它函数。举例来说,如果函数a调用函数b,而函数b又调用函数c,那么栈内所包含的信息则依次为a、b和c。

在这里我们可以看到栈的基本布局,首先是名为name的64字符缓冲区,接下来依次为帧指针以及返回地址。esp拥有此内存栈的上半部分地址,ebp则拥有内存栈的下半部分地址。
调用堆栈属于通用型“栈”数据结构的一个特殊版本。栈是一种用于存储对象且大小可变的结构。新对象能够被加入到(即’push‘)该栈的一端(一般为对应内存栈的’top‘端,即顶端),也可从栈中进行移除(即’pop’)。只有内存栈顶端的部分能够通过push或者pop进行修改,因此栈会强制执行一种排序机制:最近添加进入的项目也会被首先移除。而首个添加进入的项目则会被最后移除。
调用堆栈最为重要的任务就是存储返回地址。在大多数情况下,当一款程序调用某项函数时,该函数会按照既定设计发生作用(包括调用其它函数),并随后返回至调用它的函数处。为了能够切实返回至正确的调用函数,必须存在一套记录系统来注明进行调用的源函数:即应当在函数调用指令执行之后从指令中恢复回来。这条指令所对应的地址就被称为返回地址。栈用于维护这些返回地址,就是说每当有函数被调用时,返回地址都会被push到其内存栈当中。而在函数返回之后,对应返回地址则从内存栈中被移除,处理器随后开始在该地址上执行指令。
栈的功能非常重要,甚至可以说是整个流程的核心所在,而处理器也会以内置方式支持这些处理概念。以x86处理器为例,在x86所定义的各个寄存器当中(所谓寄存器,是指处理器内的小型存储位置,其能够直接由处理器指令进行访问),最为重要的两类就是eip(即指令指针)以及esp(即栈指针)。
esp始终容纳有栈顶端的对应地址。每一次有数据被添加到该栈中时,esp中的值都会降低。而每当有数据从栈中被移除时,esp的值则相应增加。这意味着该栈的值出现“下降”时,则代表有更多数据被添加到了该栈当中,而esp中的存储地址则会不断向下方移动。不过尽管如此,esp所使用的参考内存位置仍然被称为该内存栈的“顶端”。
eip 为现有执行指令提供内存地址,而处理器则负责维护eip本身的正常运作。处理器会从内存当中根据eip增量读取指令流,从而保证始终能够获得正确的指令地址。x86拥有一项用于函数调用的指令,名为call,另一项用于从函数处返回的指令则名为ret。
call 会获取一个操作数,也就是欲调用函数的地址(当然,我们也可以利用其它方式来获取欲调用函数的地址)。当执行call指令时,栈指针esp会通过4个字节(32位)来表现,而紧随call之后的指令地址——也就是返回地址——则会被写入至当前esp的参考内存位置。换句话说,返回地址会被添加至内存栈中。接下来,eip会将该地址指定为call的操作数,并以该地址为起始位置进行后续操作。
ret 的作用则完全相反。简单的ret指令不会获取任何操作数。处理器首先从esp当中的内存地址处读取值,而后对esp进行4字节的数值增量——这意味着其将返回地址从内存栈中移除出去。这时eip接受值设定,并以此为起始位置进行后续操作。
【视频】
在实际操作中了解call与ret。
如果调用堆栈当中只包含一组返回地址序列,那么问题当然就很简单了。但真正的难点在于,其它数据也会被添加到该内存栈当中。内存栈的自身定位就是速度快且效率高的数据存储位置。存储在内存堆上的数据相对比较复杂;程序需要全程追踪内存堆内的当前可用空间、当前所使用数据片段各自占用多大空间外加其它一系列需要关注的指标。不过内存栈本身则非常简单;要为某些数据腾出空间,只需要降低栈指针即可。而在数据不需要继续驻留在内存中时,则增加栈指针。
这种便捷性让内存栈成为一套逻辑空间,能够存储归属于函数的各类变量。每项函数拥有256字节的缓冲空间来读取用户的输入内容。简单来讲,我们只需要在栈指针中减去256这一数值就能创建出该缓冲区。而在函数执行结束时,向栈指针内添加添加256就能丢弃这个缓冲区。
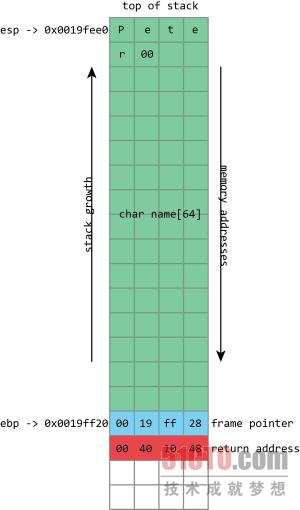
当我们正确使用程序时,键盘输入内容会被存储至name缓冲区中,随后为null(即0)字节。帧指针与返回地址则保持不变。
但这种处理方式也存在局限。内存栈并不适合保存规模庞大的对象;内存的整体可用容量通常在线程创建之时就被确定下来了,而且通常大小为1 MB。因此,那些大型对象必须被保存在内存堆中。栈也不适合保存那些需要长久存在,甚至生命周期比单一函数调用更长的对象。由于每个分配的内存栈都会在函数执行完成后被撤销,因此任何存在于该栈中的对象将无法在函数结束后继续驻留。不过存在于内存堆中的对象则不受此类限制,它们能够独立于函数之外实现长期驻留。
内存栈存储机制并不只适用于程序员在程序中明确创建的命名变量,同时亦可用于存储其它任何程序可能需要的数值。从传统上讲,这算是x86架构的一大问题。X86处理器并不能提供太多寄存器(寄存器的总体数量只有8个,而且其中一部分,例如eip与esp,还需要留作特定用途),因此函数几乎无法在寄存器中长期保留所有数值。为了在不影响现有数值以供今后检索的同时释放寄存器空间,编译器会将寄存器中的数值添加到内存栈当中。在此之后,相关数值可以pop方式从栈内转移回寄存器。用编译器的术语来讲,这种节约寄存器空间并保证数值可重复使用的操作被称为spilling。
最后,内存栈通常被用于向函数传递参数。调用函数会将每个参数添加到内存栈中,而受调用函数之后则能够将这些参数移除出去。这并不是惟一一种参数传递方式——举例来说,也可以在寄存器内部进行参数传递——但却是最为灵活的方式。
函数在内存栈上的所有具体内容——包括其本地变量、spilling寄存器操作以及任何准备传递给其它函数的参数——被整体称为一个“栈帧”。由于栈帧中的数据会被广泛使用,因此需要一种能够实现快速引用的办法与之配合。
栈指针也能完成这项任务,但它的实现方式有些尴尬:栈指针总会指向内存栈的顶端,因此它需要在添加与移除的数据之间来回移动。举例来说,某个变量可能以esp + 4地址作为起始位置,而在有另外两个数值被添加到栈中时,就意味着该变量现在的访问位置变成了esp + 12。而一旦某个数值被移除出去,那么该变量的位置又变成了esp + 8。
这倒不是什么无法克服的障碍,编译器本身能够很轻松地加以解决。不过这仍然无法真正回避栈指针以“内存栈顶端”作为起始位置的问题,特别是在手工编码的汇编程序当中。
为了简化实现流程,最常见的办法就是使用一个次级指针——其需要始终将数据保存在每个栈帧的底部(起始)位置——我们往往将该值称为帧指针。在x86架构中,甚至还有名为ebp的专门寄存器用于存储这一值。由于这种机制不会对特定函数造成任何内部变更,因此我们可以利用它作为访问函数变量的一种固定方式:位于ebp – 4位置的值在整个函数中始终保持自己的ebp – 4位置。这种效果不仅有助于程序员理解,同时也能够显著简化调试程序的处理流程。
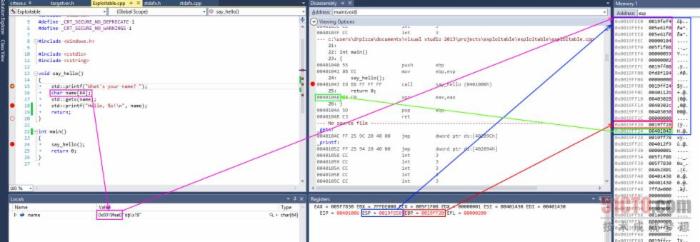
以上截图来自Visual Studio,其中显示了某简单x86程序完成上述操作的过程。在x86处理器当中,名为esp的寄存器负责容纳顶端内存栈中的地址——在本示例中为0x0018ff00,以蓝色高亮表示(在x86架构中,内存栈实际上会不断向下推进并指向地址0,但其仍然会以栈顶端为起点进行地址调用)。该函数只拥有一个栈变量,即name,以粉色高亮表示。其缓冲区大小固定为32字节。由于属于惟一一个变量,因此其位置同样为0x0018ff00,与该内存栈的顶端保持一致。
x86还拥有一个名为ebp的寄存器,以红色高亮表示,其通常专门用于保存帧指针的位置。帧指针的位置紧随栈变量之后。帧指针之后则为返回地址,以绿色高亮表示。返回地址所引用的代码片段地址为0x00401048。在这条指令之后的是call指令,很明显返回地址会从调用函数剩余的地址位置处执行恢复。
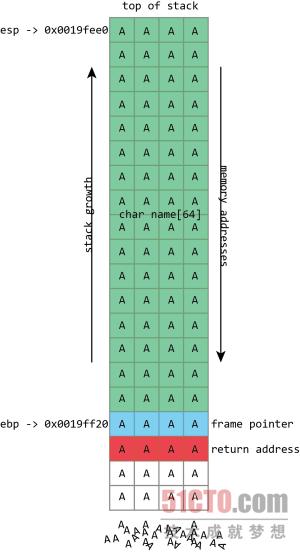
遗憾的是,gets()实在是个极其愚蠢的函数。如果我们按住键盘上的A键,那么该函数会不间断地一直向name缓冲区内写入“A”。在此过程中,该函数一直向内存中写入数据,覆盖帧指针、返回地址以及其它一切能够被覆盖的内容。
在以上截图当中,name属于会定期被覆盖的缓冲区类型。其大小固定为64字符。在这里的示例中,它被填写进一大堆数字,并最终以null结尾。从上图中可以清楚地看到,如果name缓冲区的写入内容超出了64字节,那么该内存栈中的其它数值也会受到影响。如果有额外的4字节内容被写入,那么该帧指针就会被破坏。而如果写入的内容为额外8个字节,那么帧指针与返回地址将双双被覆盖。
很明显,这会导致程序数据遭到破坏,但缓存区溢出还会造成其它更加严重的后果:通常会影响到代码执行。之所以会出现这种情况,是因为缓冲区溢出不仅会覆盖数据,同时也可能覆盖内存栈中的返回地址乃至其它更为重要的内容。返回地址负责控制处理器在完成当前函数之后,接下来执行哪些指令。返回地址正常来说应该处于调用函数之内的某个位置,但如果由于缓冲区溢出而被覆盖,那么返回地址的指向位置将变得随机而不可控制。如果攻击者能够利用这种缓冲区溢出手段,则能够选定处理器接下来要执行的代码位置。
在这一过程中,攻击者可能并没有什么理想的、便捷的“设备入侵”方法可供选择,但这并不会影响恶意活动的发生。用于覆盖返回地址的缓冲区同时也可以被用于保存一小段可执行代码,也就是所谓shellcode,其随后将能够下载一段恶意可执行代码、开启某个网络连接或者是实现其它一些攻击手段。
从传统角度讲,这确实是种令人有些意外的、小处引发的大问题:总体而言,每款程序在每次运行时都会使用同样的内存地址——即使在经过重启之后也不例外。这意味着内存栈上的缓冲区位置将永远不会变化,所以用于覆盖返回地区的值也可以不断重复加以使用。攻击者只需要一次性找出对应地址,就能够在任何运行着存在漏洞的代码的计算机上再度实施攻击。
正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](http://www.liuhaihua.cn/img/qrcode_gzh.jpg)

