Kubernetes性能测试和发展计划
【编者的话】Kubernetes是谷歌在2014年发起的开源容器编排框架,作者 Wojciech Tyczynski ,谷歌软件工程师,本文主要阐述目前状态下Kubernetes的性能测试和下一步发展计划。
无论你的容器编排系统是多灵活多可靠,你最终还是会有些工作要做,而且你还希望它能够完成得更快。对于大的问题,常见的方案就是投入更多的机器在这个问题上。毕竟,更多的计算=更快,对吗?
有趣的是,投入更多节点有点像『火箭方程的暴政』( tyranny of the rocket equation ;译者注:根据火箭方程,并不是火箭级数越多速度就会越快),事实上,在某些系统里加入更多的机器会使你的处理变得更慢。但是,又不像火箭方程,我们可以做的更好。Kubernetes在v1.0版本支持最多100个节点的集群,但是我们的目标是在2015年末将这个数字番10倍。这篇博文会阐述我们目前所在的位置和我们打算如何达到下一阶段的目标性能。
测量什么?
第一个需要回答的问题是Kubernetes可以管理一个多节点集群的真正含义是什么?用户期望是它处理所有操作都“相对较快”,但是我们需要精确的定义『快』。我们基于下面两个指标定义了性能和可扩展性的目标:
- “API响应性”:99%的API调用响应时间小于1秒
- “Pod启动时间”:99%的pods(已经下好镜像)启动时间在5秒以内
注意,对于『Pod启动时间』,我们明确地假设pod运行的所有镜像都已经提前下载到将要跑机器上。在我们的试验中,镜像之间虽然会有很高程度的差异性,如网络吞吐量,镜像大小等,但这些变化几乎不会影响Kubernetes的整体性能。
决定选择这些指标是基于我们在Google一星期内不断启动20亿个容器的试验。我们明确地希望测量与面向用户交互流(user-facing flows)的时延,因为这是我们的客户真的关心的事。
如何测量?
为了监控性能提高量和检测回归性,我们搭建了持续测试的基础设施。每2-3个小时我们会启动一个含有100个节点的集群,并且运行我们的扩展性测试这个集群上。我们使用一个GCE的n1-standard-4(4核,15G内存)机器作为master和多个n1-standard-1(1核,3.75G内存)机器作为节点。
在扩展性测试中,我们只专注于满集群情况,意思是一个满N个节点的集群含有30*N个pods运行在集群中,从性能测试的角度来看这是非常严苛的场景。为了重现一个客户可能的操作,我们按照下面的步骤运行:
- 构建pods和replication controllers去填充集群
- 制造一些负载,如创建或删除多余的pods或replication controllers,缩放现有的pods或replication controllers等操作,记录性能参数
- 停止所有运行中的pods或replication controllers
- 改变一些指标,检查是否满足我们的预期
需要强调的是测试主要部分是完成在满集群上(每个节点30个pods,一共100个nodes),启动一个pod在一个空集群中,即使它含有100个节点会变得更快。(译者注:这里不太清楚作者的意思)
为了测量pod启动时延,我们使用非常简单的pod,只含有一个容器,运行『gcr.io/google_containers/pause:go』镜像,镜像启动后就永远休眠。容器保证已经提前被下到节点上,我们使用它作为所谓的『pod-infra-container』。
性能数据
下面的表格包含pod启动的百分位数(第50位,第90位,第99位),在含有10%,25%,50%和100%的100个节点的集群中。

对于API响应性,下面图片展示百分位数是第50位,第90位和第99位的API请求时延,它们是根据操作和资源类型分类的。但是,要注意的是这些仍然包括内部系统API请求,并不仅仅是由用户发出的(这种情况下是由测试本身发出)


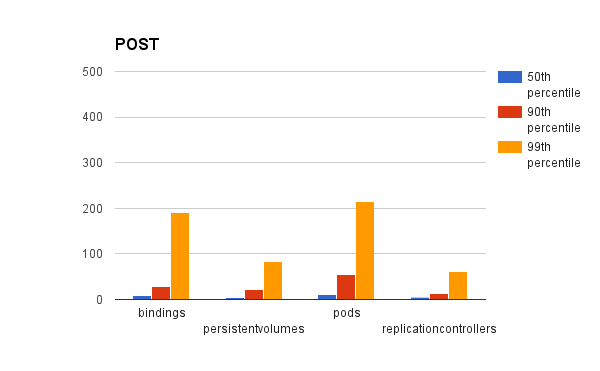

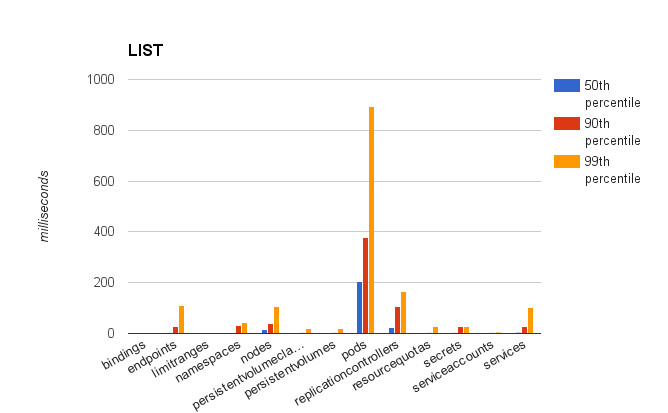
一些资源只出现在某些的图片中,这是因为图片是根据在这个操作过程中运行了什么画出来的,例如在『PUT』这个操作中并没有名字空间。
正如你看到的结果,我们已经领先的我们目标,在100个节点的集群里,对于一个pod启动时间,有14%的情况是一个满集群甚至会比99分位快5秒钟。有意思的是在『LIST』图中列出pod的时间会远远大于其他操作,这是可以理解的,在一个满集群中有3000个pods,并且每个pod大约有几KB的数据,意味着MB级的数据需要处理对于每个『LIST』操作。
已完成的工作和一些未来计划
起初的性能可以满足在100个节点的集群之上做任何测试都能足够稳定的运行,包括很多小的修复和协调,如在apiserver增加文件描述符的限制和对etcd在不同请求之间重新使用tcp连接。
然而,构建一个稳定性能的测试只是完成了第一步,使我们的集群支持增加10倍的节点。正如这个工作的结果所展示的,我们已经尽全力消除未来的瓶颈,包括:
- 重写controllers,使其可以被观察:之前他们是每隔几秒重新列出指定类型的对象,这会对apiserver造成极大的负载。
- 使用代码生成器去生成转换和深度复制的函数:尽管默认使用Go的反射功能非常方便,但它被证明效率非常的低,和生成代码相比慢10倍左右。
- 添加一个缓存给apiserver,避免从etcd多次读取相同数据而造成的反序列化。
- 减少更新状态的频率:显示一个缓慢自然变化的状态,只是在更新pod状态时,节点状态每10秒钟更新一次才可以理解。
- 在apiserver实现观察功能而不是重定向请求给etcd:我们更希望避免多次观察到相同的数据从etcd而来,因为,在很多情况下,它会被apiserver过滤掉。
进一步看,对于1000个节点的集群目标,建议实现的功能包括:
- 将事件从etcd中移除:他们更像是系统日志,并不是系统状态的一部分,也不是Kubernetes正确运行的关键点。
- 使用json解析器:默认使用的Go语言解析器非常慢,因为它是基于反射实现的。
- 重写调度,使其更高效和满足并发
- apiserver和kubelets间沟通提升效率:特别是我们计划在每次更新节点状态时减小传输数据的大小。
这绝不是一个详尽的清单。我们会不断添加新的内容(或者删除现有的内容),基于在运行现有扩展性测试和新的测试中注意到的瓶颈。如果有特别使用场景和方案你希望我们去解决,请把它们加进来!
- 我们会每周召开Kubernetes关于扩展讨论的小组会议去讨论问题和性能跟踪和提高的计划。
- 如果你有性能和扩展性的问题,可以通过Slack加入我们的讨论:
https://kubernetes.slack.com/messages/sig-scale - 一般性问题可以加入我们Kubernetes社区讨论:
https://kubernetes.slack.com/m ... sers/ - 提交合入和提出问题,你可以在GitHub上完成。非常欢迎每个人贡献你们的经验或者PR来使Kubernetes变得更好。
**需要注意的是我们排除了API响应性参数中所有对『events』资源的操作,我们不提供任何保证对于它们,因为,这些不会影响Kubernetes去正确操作的能力(它们更像是系统日志)。*
原文链接: Kubernetes Performance Measurements and Roadmap (译者:何炜)
正文到此结束
热门推荐










相关文章

近期评论
-
你这基本没有更新呀,最近文章显示还是2019年的文章。不符合要求哈
-
关键词:慕云博客 链接:https://www.lilun.me 描述:分享原创文字的个人博客
-
-
-
可以提供一下源码吗
-
不是商业站,鸡娃学习笔记
-
-
-
-
听他们说很厉害的样子
Loading...
![[HBLOG]公众号](http://www.liuhaihua.cn/img/qrcode_gzh.jpg)

