【dbdao.com hadoop大数据教程】hadoop HDFS 使用QJM完成HA
dbDao.com 引导式IT在线教育Hadoop 技术学习QQ群号 : 134115150
本文是官方文档的翻译 本文固定链接是:http://t.dbdao.com/archives/hadoop-hdfs-ha-qjm.html
原文链接: http://hadoop.apache.org/docs/r2.7.1/hadoop-project-dist/hadoop-hdfs/HDFSHighAvailabilityWithQJM.html
这个指南提供一个关于HDFS 高可用特性的概述,并且描述了如何使用Quorum Journal Manager(QJM)来管理和配置 HA HDFS集群。
这个文档的假设读者对在HDFS集群中的节点类型和一般组件有一定的理解。更详细的信息请参考HDFS构架指南。
2.备注:使用QJM或者使用常规存储
这个指南讨论了如何使用QJM来配置和使用HDFS HA,在活动的NameNodes和备份NameNodes之间共享edit 日志。如何使用NFS来配置HDFS来进行共享存储代替QJM,请参考HDFS HA
(http://hadoop.apache.org/docs/r2.7.1/hadoop-project-dist/hadoop-hdfs/HDFSHighAvailabilityWithNFS.html)
在 hadoop 2.0.0之前,NameNode在HDFS集群中是一个单独的故障点。每个集群有一个NameNode,一旦这个机器或进程不可用,整个集群就将全部不可用,直到NameNode重新启动或者在另外的机器上完成启动(dbdao.com Hadoop 大数据学习)。
影响HDFS集群总体高可用的问题主要有以下2点:
- 在一些意外事件,例如机器崩溃的情况下,集群将不可用,直到NameNode完成一个重启操作。
- 计划的维护事件,例如NameNode上的软硬件的升级,导致需要集群停机的时间窗口。
HDFS HA特性解决了上述问题,提供一些选择在一个相同集群中运行2个冗余的NameNode,在主动/被动的配置中,具有热备份。这将允许在一个机器崩溃的情况下,或者在有计划维护的目的中,进行快速切换到一个新的NameNode。
在一个普通的HA集群,2个独立的机器被配置成NameNode。在同一时间点,确切地说,只有一个NameNode是活动的,另一个处于备份(standby)状态。这个活动的NameNode负责集群中所有客户端的操作,而备机只是简单地充当一个从属角色,保持一个良好的状态在必要的时候进行快速切换。
为了保证备用节点保持与活动节点的同步状态,所有的节点使用一组单独的进程来进程通信,被称为journalNodes(JNS)。当命名空间被活动节点进行任何修改时,这些JNs记录下这些修改的日志。备份节点能够通过JNS读取这些edits,并且不断的监控这些edit日志的变化。当备份节点发现了edits,它会在本身的命名空间中应用这些edits。发生故障转移时,在促使自身成为活动节点之前,备份节点将确保其通过JounalNode读取到了所有的edits。这确保了在发生故障转移之前,命名空间的状态是完全同步的。
为了提供一个快速故障转移,备份节点有最新关于集群块位置的信息也是非常重要的。为了保证这些,DataNode会在这些NameNode中都注册位置,并且给所有的NameNode都发生块位置信息和心跳信息。
对于HA集群来说,只有一个NameNodes在同一时刻是活跃时,正确的操作是至关重要的。否则,在两者之前,命名空间很快会出现不一致,导致数据丢失或者其他不正确的结果。为了保证这一属性,并且防止所谓的“脑裂”的情况,JournalNode将只允许在同一时间点,只用单独的NameNode可以写。故障转移期间,将要成为活动节点的NameNode将简单的接管写入JournalNodes的角色,这将有效的防止其他的NameNode继续处于活跃状态,允许新的活动节点安全的进行故障转移(dbdao.com Hadoop 大数据学习)。
5.硬件资源
为了部署一个HA集群,你需要准备如下:
- NameNode机器:活动和备份的NameNodes需要用等同的硬件配置,并且等同于其他非HA集群中的硬件。
- Journal machine:运行JournalNodes的机器。JournalNode进程是相对轻量的,所以呢,这些进程可以合理地与其他的hadoop进程的机器一起配置,例如:NameNode,JobTracker,或者YARN ResourceManager。
备注:这里最少需要3个JournalNode进程,由于edit日志修改必须写到多个JNs。这将允许系统容忍一台单独机器故障。你也可以运行超过3个的JournalNodes,但是为了增加系统可以容忍故障的数目,你需要运行一个奇数的Jns,(例如,3,5,7,等等)。注意到在运行N个 journalNodes时,系统可以容忍最多(N-1)/2的故障并且继续正常运行。
–2个journalNodes一组与active和standby通信。也就是其中一个故障都不行。所以最少3个才有用,3个可以容忍坏一个进程。5个能坏2个。
注意到这些,在一个HA集群中,备份节点也执行命名空间的检查点,因此在HA集群中,没必要再运行一个Secondary NameNode,CheckpointNode,或者BackupNode。实际上,这样做会出项一个错误。也允许重用之前非HA HDFS中为 SecondaryNameNode配置的硬件。
6.1配置概要
和联合配置类型,HA配置是相关兼容的,并且允许现有的单节点的工作配置不用改变。新的配置被设置为,让集群中所有节点可以有相同的配置,而不需要为不同类型的机器节点部署不同的配置文件。
像HDFS联邦,HA集群使用namesever ID来识别一个单独的HDFS实例,事实上可能包括多个HA NameNode。除此之外,一个新的抽象 NameNode ID被添加到HA中。每个集群中不同的NameNode,拥有不同的NameNode ID来区分。为了支持为所有的NameNode配置一个独立的配置文件,相关的配置参数需要以nameservice ID以及NameNode ID为后缀(dbdao.com Hadoop 大数据学习)。
6.2 详细配置
为了配置HA NameNode,你需要在hdfs-site.xml配置文件中增加一系列配置选项。
这些配置的顺序是不太重要的,但是你选择的df.nameservices和dfs.ha.namenodes.[nameservice ID]的值是确定它们的关键。因此你需要在设置这些值之前,确定好这些值。
- dfs.nameservices -新nameservice的逻辑名称
为这个nameservice选择一个逻辑名称,例如”mycluster”,然后在这个配置选项中使用这个逻辑配置的值。这个名称的选择是任意的。它将被用于配置和作为集群中HDFS绝对路径的权限组件。
备注:如果你也使用HDFS Federation,这个配置还应该包括其他nameservices的列表,HA或其他的列表,以逗号分隔。
<property> <name>dfs.nameservices</name> <value>mycluster</value> </property>
- dfs.ha.namenodes.[nameservice ID]-每个NameNode在nameservice中唯一标识符
配置是以逗号分隔的NameNode IDs的列表。这个将被DataNode使用来确定集群中所有的NameNodes。例如,如果你之前使用”mycluster” 作为nameserver ID,你想使用”nn1″和”nn2″作为NameNodes的个人的IDS,你需要配置如下:
<property> <name>dfs.ha.namenodes.mycluster</name> <value>nn1,nn2</value> </property>
备注:目前,只有最大2个NameNode可以在每个nameservice被配置。
- dfs.namenode.rpc-address.[nameservice ID].[name node ID]-为每个NameNode监听的完全合格的RPC地址(dbdao.com Hadoop 大数据学习)
为之前配置的NameNode IDs,设置NameNode进程的完整地址和IPC端口。注意到这个在2个不同的配置选项中。例如:
<property> <name>dfs.namenode.rpc-address.mycluster.nn1</name> <value>machine1.example.com:8020</value> </property> <property> <name>dfs.namenode.rpc-address.mycluster.nn2</name> <value>machine2.example.com:8020</value> </property>
备注:如果你希望呢,可以同样的配置”servicerpc-address”的设置
- dfs.namenode.http-address.[nameservice ID].[name node ID]- 为每个NameNode监听的完全合格的HTTP地址
和rpc-address类型,为所有的NameNode的hTTP服务设置监听地址。例如:
<property> <name>dfs.namenode.http-address.mycluster.nn1</name> <value>machine1.example.com:50070</value> </property> <property> <name>dfs.namenode.http-address.mycluster.nn2</name> <value>machine2.example.com:50070</value> </property>
备注:如果你开启了hadoop的安全特性,你还需要为每个Namenode设置 类似地https-address。
dfs.namenode.shared.edits.dir -这个URI定义了JNs组从哪个NameNode读取和写edits
这是一个配置 journalnodes来提供共享edits存储的地址,让活动的nameNode写入所有系统的变化,让备份NameNode来保存最新的。虽然你必须指定多个JournalNode地址,你只需要配置一个URIs。这个URI需要按照这个格式: qjournal://*host1:port1*;*host2:port2*;*host3:port3*/*journalId*。Journal ID是确定nameservice的唯一标识符,允许单个JournalNodes设置提供多个联合命名系统的存储。虽然不是要求,利用nameservice ID来作为journal 标识符是一个好主意(dbdao.com Hadoop 大数据学习)。
例如,这个集群的journalNode 运行在机器”node1.example.com”,”node2.example.com”,”node3.example.com”,并且nameservice ID是”mycluster”,你需要使用下列设置的值(默认的journalNode的端口是8485):
<property> <name>dfs.namenode.shared.edits.dir</name> <value>qjournal://node1.example.com:8485;node2.example.com:8485;node3.example.com:8485/mycluster</value> </property>
dfs.client.failover.proxy.provider.[nameserivce ID]-HDFS客户端用来接触活动namenode的java class
配置将被DFS客户端使用的java class 名称,来确定哪个NameNode是当前活动的,同时哪个NameNode是当前服务器客户端请求的。目前hadoop实施只有ConfiguredFailoverProxyProvider,除非你使用自定义的一个。例如:
<property> <name>dfs.client.failover.proxy.provider.mycluster</name> <value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value> </property>
- dfs.ha.fecing.methods – 在故障转移期间,保证活动namenode使用的脚本或java classses的列表
在任何时候只有一个NameNode是活动状态,这种理想下系统的正确的。重要的,当使用QJM,只有一个NameNode将被运行写入到JournalNodes,这样不可能破坏文件系统元数据出现脑裂的情况。但是当故障转移发生,任然可能发生之前的活动节点从客户端读取到请求,这个过程会直到NameNode试图往JournalNode写入时关闭(Namenode)。因为这个原因,还需要配置一些保护方法,在使用QJM时。但是,在防护措施失败的情况下,为了提高系统的可用性,建议设置一个可以保证成功的方法,作为列表中最后一个防护方法来返回成功。注意到,如果你没有选择任何防护反复,你还是需要为这个配置设置(dbdao.com Hadoop 大数据学习)。例如:
“shell(/bin/true)”
在故障转移期间使用的保护方法可以使用回车符分隔的列表来配置,其将尝试直到有一个表明是成功的。在hadoop中有2个方法:shell和sshfence。关于实施自定义的保护方法,可以参考org.apache.hadoop.ha.NodeFencer 类。
sshfence -ssh到活动的nameNode并且杀死进程
这个sshfence选项 ssh到目标节点然后使用 fuser来市调监听在service TCP端口上的进程。为了是这个防护选项工作,必须配置好到目标节点的ssh信任。因此,还必须设置dfs.ha.fencing.ssh.private-key-files选项,这是一个逗号分隔的ssh私钥文件列表。例如:
<property> <name>dfs.ha.fencing.methods</name> <value>sshfence</value> </property> <property> <name>dfs.ha.fencing.ssh.private-key-files</name> <value>/home/exampleuser/.ssh/id_rsa</value> </property>
通常情况下,可以配置一个非标准的用户名和端口来执行SSH。另外可以配置超时时间,以微秒为单位,作为ssh认为是失败的防护方法。其可以配置如下:
<property> <name>dfs.ha.fencing.methods</name> <value>sshfence</value> </property> <property> <name>dfs.ha.fencing.ssh.private-key-files</name> <value>/home/exampleuser/.ssh/id_rsa</value> </property> <property> <name>dfs.ha.fencing.ssh.connect-timeout</name> <value>30000</value> </property>
shell – 运行任意的shell命令来防护活动NameNode
shell防护可以运行任意的shell命令。可以配置如下:
<property> <name>dfs.ha.fencing.methods</name> <value>shell(/path/to/my/script.sh arg1 arg2 ...)</value> </property>
在()之间的字符串,是一个bash shell的绝对路径,并且不能包含任何园括号。
这个shell命令将在包含当前所有hadoop配置的变量环境中运行,在配置中替换‘_‘字符为‘.’。这个配置会使用任何namenode-指定的配置使用 -格式,例如 dfs_namenode_rpc-address 将包含目标节点的PRC地址,即使通过配置指定了变量dfs.namenode.rpc-address.ns1.nn1.(dbdao.com Hadoop 大数据学习)
此外,下列变量也肯一在指定目标节点中来使用:
| $target_host | 被防护的节点的主机名 |
| $target_port | 被防护的节点的IPC端口 |
| $target_address | 上面2者的结合 host:port |
| $target_nameserviceid | 被防护的NN的nameservice ID |
| $target_namenodeid | 被防护的NN的namenode ID |
这些环境变量也可以使用shell 命令中的替换,例如:
<property> <name>dfs.ha.fencing.methods</name> <value>shell(/path/to/my/script.sh arg1 arg2 ...)</value> </property>
如果shell 命令返回一个退出代码0,这个防护被认为是成功的。如果返回任何其他的推出代码,这个防护是不成功过的,列表中下一个防护方法被允许。
备注:这个防护方法不能实施任何超时,如果超时是必须的,其需要在shell脚本中自身实现(例如在超过多少秒后,fork一个子shell 来杀掉父进程。)
–其实就是自己用脚本来处理原来namenode上的进程问题(dbdao.com Hadoop 大数据学习)。
- fs.defaultFS-当没指定的时候,Hadoop FS客户端使用的默认路径前缀
通常呢,现在可以为Hadoop客户端配置默认的路径来使用新的HA 逻辑URI。如果在之前使用了”mycluster”作为nameservice id呢,这将是HDFS路径中最权威的值。其可以在core-site.xml中配置如下:
<property> <name>fs.defaultFS</name> <value>hdfs://mycluster</value> </property>
- dfs.journalnode.edits.dir -这个路径就是JournalNode 进程将存储其本地状态的位置。
这是在jouralNode机器上的绝对路径,JNs的edits和其他本地状态将被存储在此处。你只需要使用一个单独的路径配置。数据冗余是通过多个独立的journalnodes提供,或者通过在本地在局部路径上增加RAID阵列来实现。例如:
<property> <name>dfs.journalnode.edits.dir</name> <value>/path/to/journal/node/local/data</value> </property>
6.3 部署细节
在所有必须的配置选项都设置好后,你必须在设置为journalNode的集群上启动JournalNode 进程。可以使用” hadoop-daemon.sh start journalnode “命令,然后等待所有相关集群上的进程启动。
一旦JournaNode 被启动,必须在HA 两个nameNode 之间完成磁盘元数据的同步(dbdao.com Hadoop 大数据学习)。
- 如果是设置一个新的HDFS集群,你需要在NameNodes上首先运行格式化命令(hdfs namenode -format)
- 如果你已经完成了NameNode的格式化,或者是将一个非HA集群转换到一个HA机器,你需要拷贝NameNode元数据目录的的内容到另外的机器上,然后在非格式化NameNode上使用命令” hdfs namenode -bootstrapStandby “。在运行这个命令的时候也要确保JouralNodes(被dfs.namenode.shared.edits,dir配置)包含足够的的edits事务能够启动所有的NameNodes。
- 如果你将一个非HA的NameNode转换为HA,你需要运行命令” hdfs namenode -initializeSharedEdits “,这个命令将从本地NameNode edits目录初始化 JournalNodes的edits数据。
在此时,你可以启动所有的HA NameNode,就和普通启动NameNode一样。
你可以通过访问他们单独配置的HTTP地址来游览NameNode的web页面。你需要注意的,配置的地址将成为NameNode的HA状态(也就是”standby”或”active”)。每当一个HA NameNode启动时,它最初的状态是standby。
6.4 管理命令
现在,你的HA NameNode 已经被配置好和启动了,你将需要一些额外的命令来管理你的HA HDFS集群。通常呢,你需要熟悉所有的” hdfs haadmin “的一些子命令。不加任何参数执行将显示如下的帮助信息:
Usage: haadmin[-transitionToActive <serviceId>][-transitionToStandby <serviceId>][-failover [–forcefence] [–forceactive] <serviceId> <serviceId>][-getServiceState <serviceId>][-checkHealth <serviceId>][-help <command>]
本指南描述了每个子命令的高级用法。对于每个命令使用的详细信息,你可以运行” hdfs haadmin -help <command> “。
- transitionToActive 和 transitionToStandby -为指定的NameNode转换状态到active或standby
这个子命令可以让NameNode过渡到Active或standby状态。这个命令不会执行任何防护,因此很少被使用。替代的,经常是使用” hdfs haadmin -failove “的子命令。
- failover – 在2个NameNode之间启动一个故障转移(dbdao.com Hadoop 大数据学习)
这个子命令导致一个故障转移从提供给的第一NameNode到第二NameNode。如果第一NameNode是standby状态,这个命令简单的将第二个装换为主动状态而没有错误。如果第一个NameNode是active状态,将尝试进行standby状态的过渡。如果这个过程失败,防护程序(被dfs.ha.fencing.methods配置)将被执行,直到一个成功。在这个过程中,只有第二个NameNode将被过渡到active状态。如果没有防护程序成功,第二个NameNode将不会过渡到active状态,然后会返回一个错误。
- getServiceState – 明确给定的NameNode是acitve或Standby
连接到提供的NameNode来确认当前的状态,在标准输出上打印”standby”或”active”。这个子命令可以被日常的job或监控脚本使用,来根据当前NameNode状态是active或standby作出不同的行为。
- checkhealth 检查给定NameNode的健康
连接到提供的NameNode来检查健康。NameNode可以对自身进行诊断,包括检查内部的服务是否如期的运行。这个命令在NameNode 健康的情况下返回0,否则是非0值。这个命令可以作为监控的目的。
备注:这个还没完全实现,执行的时候总是返回成功,除非给定的NameNode是完全关闭的。

也可以在通过web页面来获取信息:

7.自动故障转移
7.1 介绍
上面的章节描述了如何配置手动故障转移,在这个模式下,系统不会自动的触发从acitve到standby NameNode的故障转移,即使active节点已经故障了。本节介绍了如何配置和部署自动故障转移(dbdao.com Hadoop 大数据学习)
7.2 组件
自动故障转移增加了2个新组件到HDFS部署中:ZooKeeper quorum,和ZKFailoverController (缩写为ZKFC)进程。
apache ZooKeeper是一个高可用服务,维护少量的协调数据,通知客户端变更这些数据,并且检测客户端失败。部署自动的HDFS 故障转移依赖于ZooKeeper的以下几点:
- 故障检测 – 集群中每个NameNode机器在ZooKeeper中维护一个持续会话。如果集群崩溃,这个会话将过去,通知其他的NameNode一个故障转移应当被触发。
- Active NameNode 选择 -ZooKeeper提供了一个简单的机制来只选择一个节点作为active。如果当前的NameNode 崩溃,另一个节点可以在ZooKeeper中产生一个特殊的排他锁,表示它将成为下一个acive。
ZKFS是一个新的组件,是一个健康和管理nameNode状态的ZooKeeper客户端。每个运行NameNode的机器也运行一个ZKFC,ZKFS有下列责任:
- 健康监控 -ZKFC定期的使用健康检查命令 ping 本地的NameNode。只要及时得到NameNode的响应的健康状态,ZKFC就认为节点是健康地。如果节点崩溃,冻结,或者进入了不健康状态,健康监控进程将标记其为非健康地。
- ZooKeeper会话管理 – 当本地NameNode是健康地,ZKFC在ZooKeeper中保持一个会话。如果本地NameNode是active,其还将持有一个特殊的锁znode。这个锁被ZooKeeper为节点”短暂地“使用;如果会话过期,这个锁node将自动删除。
- ZooKeeper-基础选择 -如果本地NameNode是健康地,ZKFS查看当前没有其他的节点持有锁znode,它自己将试图获得这个锁。如果其成功了,那么其”赢得了选择“,并且其负责运行一个故障转移来保证本地Namenode是active。故障转移过程类似于上述的手动故障转移:首先,之前的active是被防护的,如果必要的话,然后本地的NameNode过渡到active状态。
更详细关于自动故障转移的设计,可以参考HDFS JIRA上的设计文档HDFS-2185
7.3 部署ZooKeeper
在普通的部署中,ZooKeeper进程被配置和运行在3个或4个节点上。由于ZooKeeper本身只需要少量的资源,配置ZooKeeper节点在同样硬件上的HDFS NameNode和standby Node上是可以接受的。许多运营商选择将第三个ZooKeeper进程部署到作为YARN资源管理的节点上。建议配置ZooKeeper节点存储他们的数据使用不同的磁盘驱动器来隔离HDFS元数据和保证最高性能。
对ZooKeeper的配置超出了本文的范围。我们将假设你已经设置一个ZooKeeper集群,运行在3个或者以上的节点上,并且通过 ZK CLI验证了其操作的正确性。
7.4 在开始之前
在配置自动故障转移之前,你需要关闭集群。目前做不到在集群运行的时候从手动故障转移转变成自动故障转移。(dbdao.com Hadoop 大数据学习)
7.5 配置自动故障转移
配置自动的故障转移,需要在配置文件中增加2个参数配置。在hdfs-site.xml中增加:
<property> <name>dfs.ha.automatic-failover.enabled</name> <value>true</value> </property>
这说明集群配置为自动故障转移。在core-site.xml中,增加:
<property> <name>ha.zookeeper.quorum</name> <value>zk1.example.com:2181,zk2.example.com:2181,zk3.example.com:2181</value> </property>
这个列表是运行ZooKeeper服务的主机-端口对。
正如本文之前描述的参数,这些设置可以被配置在每个 namneservice基础上,通过使用nameservice ID的后缀。例如,在一个集群中启用了federation,你可以对单一的nameservice明确的开启自动故障转移,通过设置dfs.ha.automatic-failover.enabled.my-nameservice-id
这里也有一些其他的配置参数来控制自动故障转移的行为;但是,在大多数安装情况下并不是所需的。详情请参阅配置文件的具体说明。
7.6在ZooKeeper中初始化HA状态
在配置增加之后,下一步就是在ZooKeeper中初始化所需的状态。你可以在其中的一个NameNode 主机上运行以下命令:
Shell
[hdfs]$ $HADOOP_PREFIX/bin/hdfs zkfc -formatZK
这将在ZooKeeper中创建一个znode代替自动故障转移系统存储的数据
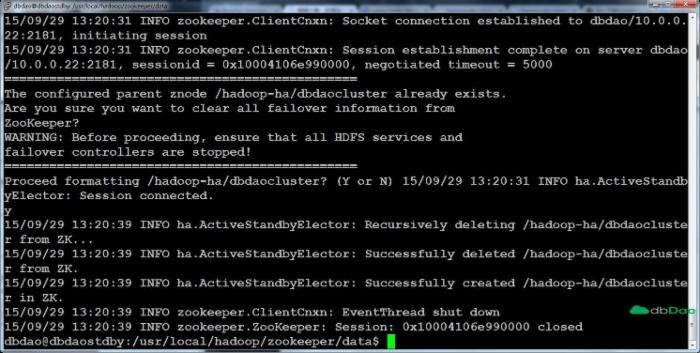
7.7 使用 start-dfs.sh启动集群
在配置中开启自动故障转移之后,start-dfs.sh脚本会自动在那些运行NameNode的机器上,启动一个ZKFC进程。当ZKFCs启动,他们会自动选择一个NameNode作为active(dbdao.com Hadoop 大数据学习)
7.8 手动开启集群
如果你手动的管理集群服务,你需要在那些运行NameNode的机器上,手动开启ZKFS进程。你可以使用下面命令来开启:
Shell
[hdfs]$ $HADOOP_PREFIX/sbin/hadoop-daemon.sh --script $HADOOP_PREFIX/bin/hdfs start zkfc
7.9 安全访问ZooKeeper
如果你运行一个具有安全性的集群,你想保证存储在ZooKeeper中的数据也是安全的。这可以防止恶意用户修改ZooKeeper的元数据或者可能引发一个错误的故障转移。
为了在ZooKeeper中的信息安全,首先在core-site.xml中加入下列配置:
<property> <name>ha.zookeeper.auth</name> <value>@/path/to/zk-auth.txt</value> </property> <property> <name>ha.zookeeper.acl</name> <value>@/path/to/zk-acl.txt</value> </property>
请注意在值中’@’符号-这指定配置不是内联的,而是指向磁盘上的一个文件。
第一个配置文件中指定了zookeeper的认证列表,以ZK CLI使用的相同格式。例如,你可以指定类似:
digest:hdfs-zkfcs:mypassword
hdfs-zkfcs是zookeeper的唯一用户名,mypasswd是使用到的唯一密码字符串。
然后生成一个zookeeper ACL 对此进行验证,使用命令如下:
Shell
[hdfs]$ java -cp $ZK_HOME/lib/*:$ZK_HOME/zookeeper-3.4.2.jar org.apache.zookeeper.server.auth.DigestAuthenticationProvider hdfs-zkfcs:mypassword output: hdfs-zkfcs:mypassword->hdfs-zkfcs:P/OQvnYyU/nF/mGYvB/xurX8dYs=
复制和粘贴在’->’之后的字符串到 文件zk-acls.txt中。以”digest:”为前缀。例如:
digest:hdfs-zkfcs:vlUvLnd8MlacsE80rDuu6ONESbM=:rwcda
为了使这项ACL生效,你应该再运行之前的描述的 zkfc -formatZK的命令。
这样做之后,你可以从ZK CLI验证ACLS 例如:
[zk: localhost:2181(CONNECTED) 1] getAcl /hadoop-ha 'digest,'hdfs-zkfcs:vlUvLnd8MlacsE80rDuu6ONESbM=: cdrwa
7.10 验证自动故障转移
一旦自动故障转移被设置,你应该测试这个功能。首先,找到活动的NameNode。你可以通过访问NameNode web接口来找到哪个节点是active的-每个节点的首页上会报告它们HA的状态。(dbdao.com Hadoop 大数据学习)
当你找出了活动的nameNode,你可以在这个节点上引发一个故障。例如,你可以使用 kill -9 <pid NN> 来模拟一个 JVM崩溃。或者你可以关闭机器的电源或者拔出网络接口来模拟不同类型的中断。在触发了你想要的中断之后,在几秒种内,其他的NameNode将自动的成为active。检测故障和引发故障转移所需的时间取决于在ha.zookeeper.session-timeout.ms中的配置,默认是5秒。
如果测试不成功,你可能有一个错误。检查NameNode进程和zkfc的日志来进一步诊断问题。
8.自动故障转移 FAQ
8.1 启动ZKFC和NameNode进程的顺序是重要的么?
不是。你可以在给定的节点上在对应NameNode之前或者之后启动ZKFC。
8.2 我应该将额外的监控放在什么地方?
你应该在每个运行NameNode的主机上增加监控,确保ZKFC是持续运行的。在一些ZooKeeper故障的情况下,例如,ZKFC意外退出,需要重新启动它,来确保系统是可以进行故障转移的。
此外,你需要监控在ZooKeeper quorum的每个服务。如果ZooKeeper崩溃,那么自动故障转移功能也不能使用。
8.3 如果ZooKeeper 关闭之后会发生什么?
如果ZooKeeper 集群崩溃,那么自动故障转移将不会触发。但是,HDFS将继续运行不会收任何影响。当ZooKeeper重启,HDFS将重新连接不会有任何问题。
8.4 我可以指定一个NameNode作为主/优先?
不行。当前,这个并不支持。NameNode 首先启动的将成为active。你可以在启动的时候选择一定的顺序,例如将你期望的节点先启动。
8.5 在配置了自动故障转移时,我如何启动手动故障转移?
即使自动故障转移被配置,你可以使用相同的命令hdfs haadmin。其将执行一个协调的故障转移。(dbdao.com Hadoop 大数据学习)
9. 在HA启用时HDF的 升级/确定/回滚
在HDFS各个版本之间移动,有时新的软件可以简单的被安装,然后集群重启。有的时候,你在升级HDFS版本时需要变更磁盘数据。在这个情况下,必须使用 HDFS 升级/确定/回滚命令,在安装了新软件之后。在HA环境中,这个过程是更复杂的,由于NN磁盘上的元数据,是依赖于定义分布的,2个HA NNs是一对,并且在 journalNode这种情况下,QJM被用来共享edits存储。本文介绍了在HA配置中使用HDFS 升级/确定/回滚的部分过程。
9.1为了进行一个HA升级,必须进行如下操作:
1.正常的关闭所有的NNs,然后安装新软件。
2.启动所有的JNs。注意这是至关重要的,在执行升级,回滚或最终确认操作时,所有的JNs需要运行。如果有任何的JNs关闭,这是运行任何操作都将失败。
3.使用 ’-upgrade‘标签启动一个NNs
4.开始,这个NN并不是像平常HS设置那样进入standby状态。而是立即进入active状态,在本地存储的目录执行升级,并且为共享的edit日志执行升级。
5.在这一点上HA中配对的NN将于升级的NN不同步。为了将其再一次的同步并且拥有高可用的配置,你需要重启这个NameNode 使用命令’-bootstrapStandby’ 。在第二个NN上使用’-upgrade’启动会出现一个错误。
注意到,如果在最终确认或回滚之前的任何时候,你想重启NameNode,你需要正常的启动NNs,也就是不要制定任何的标记。
9.2确认一个HA升级
这个操作需要使用’hdfs dfsadmin -finalizeUpgrade’命令,当NNs均在运行状态,并且其中一个是active。active NN在这个时候会在共享日志上执行确认,并且NN中所有本地存储的目录中包含之前FS状态删除它们本地的状态。(dbdao.com Hadoop 大数据学习)
9.3 执行一个回滚
首先,所有的NNs需要关闭。这个操作需要在启动了升级过程的NNs上运行回滚命令,其将执行回滚本地目录,共享日志,无论是在NFS或者JNs上。然后,这个NN应该被启动,在其他NN上需要运行’-bootstrapStandby ‘让两个NNs同步此回滚文件系统的状态。
dbDao.com 引导式IT在线教育
dbDao 百度贴吧:http://tieba.baidu.com/dbdao
扫码关注dbDao 微信公众号:

正文到此结束
- 本文标签: 管理 key 同步 运营 翻译 shell cat zookeeper 大数据 XML provider core 服务器 db 进程 安全 Bootstrap 实例 百度 src 备份 node 教育 secondarynamenode IDE HTML final lib web 端口 nfs Secondary Namenode 数据 空间 锁 dist apache tab tar Datanode UI TCP 参数 client 删除 ssh Hadoop Namenode 配置 时间 软件 example http java 认证 https HDFS 代码 value QQ群 主机 目录 测试 ip 集群 安装
- 版权声明: 本文为互联网转载文章,出处已在文章中说明(部分除外)。如果侵权,请联系本站长删除,谢谢。
- 本文海报: 生成海报一 生成海报二
热门推荐










相关文章






Loading...
![[HBLOG]公众号](http://www.liuhaihua.cn/img/qrcode_gzh.jpg)

