我是如何构建高并发下响应式读服务的
一. 该系统的特点  三. 第一版系统遇到的问题
三. 第一版系统遇到的问题 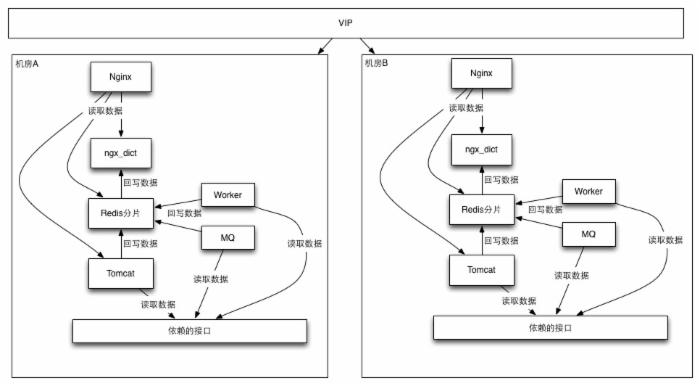 六 我们后续要做的事情
六 我们后续要做的事情
该系统的特点是业务方多,后台依赖系统多。由于各个服务方使用的语言各不相同,为了方便各个系统调用,我们统一使用http协议形式来提供数据。
这就需要我们将后端依赖的各种数据类型进行组装并转换成服务方需要的数据,同时我们也需要解决快速响应的问题
二. 最早的系统架构我们是这样做的我们用nginx代理后端的多个tomcat实例,tomcat负责从各个系统读取数据并组装成客户需要的数据,同时为了解决快速响应问题,我们将数据缓存redis。
大致的数据访问流程很简单:当请求过来后通过HttpRedis2Module模块直接从redis获取需要的数据,如果redis获取不到就回源到tomcat,tomcat负责将数据返回并向redis写一份数据。
另外为了保证多个机器数据一致性问题,采用redis一主多从来解决数据一致性问题。
架构图:
三. 第一版系统遇到的问题 初期由于系统访问量不大,基本可以满足我们的要求。后续随着业务量的增长,以及每年的618和双十一活动的影响,基本上每个活动的当天的访问量都会高出日常十倍。
遇到的问题主要如下:
1. 主redis需要向多个从redis同步数据,流量过大会造成主的性能下降,比如cpu负载升高,网卡流量打满等。
2. 由于缓存失效导致的回源问题,导致tomcat压力过大
3. 单个redis实例的内存使用量过高
4. 存入redis中单个key-value数据体积过大
5. 由于主redis单点问题,如果挂掉造成数据无法及时同步
四. 针对第一版遇到的问题我们做了哪些事情1. 为了降低主redis的压力,我们采用了redis树状结构,比如我们在主redis下只设置了两个从实例,然后每个从实例下又可以挂载几个从实例。
2. 对于应对缓存失效导致的回源问题,我们采用了两种方式来解决;一种是让缓存不过期,我们通过定时的跑worker或者mq来更新数据,同时为了节约内存,这种方式只适用于数据量小的业务。 另一种是通过lua-resty-lock的方式对需要回源到后端的相同请求进行无阻塞锁。
lua-resty-lock是一个基于共享内存(ngx.shared.DICT)的非阻塞锁。首先该锁是基于共享内存的,并且锁在创建后还会为自身设置一个超时时间,也就是说在这个指定的超时时间内,不管有没有对其解锁,该锁都会被回收掉。另外在nginx中对于使用DICT缓存的数据它是每个worker都是可见的;说它是非阻塞的是因为它不会阻塞nginx的worker进程,当某个key被锁住之后,后续试图对该key尝试进行锁的操作都会被非阻塞等待在这里,查看lua-resty-lock的源码可以看到,它实际上是用ngx.sleep实现的,而ngx.sleep又是利用了nginx自身的定时器和lua中协程的概念实现的。
下面我们看一下具体业务代码实现步骤:
1. 首先我们检查请求的key是否在dict中有一份数据,有就直接返回,如果没有,那么我们就从redis中获取数据,有则返回,没有则进入第2步
2. 这时候我们需要创建一个锁,创建锁的时候可以为该锁对象设置一些超时时间等参数,然后调用lock方法对其加锁。然后我们判断该锁是否已经超时,如果超时这里有两种策略供我们选择,根据具体业务的不同,一种是直接返回一个错误数据;另一种是直接回源;如果选择的是直接回源,那么在超时时间内积压的请求会全部走后后端,对于后端是个不小的压力;如果选择返回错误数据,对客户体验又不好,这两者需要权衡。如果没有超时,那么进入第3步。
3. 再次从dict中获取数据,因为数据成功回源后不但会向redis写一份数据,还会向dict中写一份数据,如果从dict中获取到数据,那么我们对该key进行unlock操作,这个时候所有在该key上等待的请求会直接从dict中获取数据,这样就避免了因为缓存失效导致后端压力过大的问题。如果从dict中还是获取不到数据,直接进入第4步。
4. 通过回源向后端请求数据,然后解锁。
3. 最早我们每个机器上都是用的单个redis实例,当redis单实例占用内存过大并且高并发下,通过slowlog会看到响应速度明显变慢,同时一但redis挂掉,或者因为网络的原因就会导致redis主从之间进行数据全量重同步。这对于线上网卡又会产生一个不小的压力。为了解决这个问题,我们对数据进行了分片处理,就是没太机器上启动多个redis实例,通过hash的方式将数据分散到不同的实例上。在做分片的时候我们需要保证后端的写入分片算法,和nginx读取数据的分片算法一直。
后端采用的是在jedis的基础上扩展出一套简单的取摸算法;nginx这端为了方便和快速,我们用C实现和后端相同的算法,并将其嵌入到lua中,通过ngx_lua模块对其进行调用。
具体算法这里就不做解释了,简单说一下调用过程:
1)在nginx指定.so动态库路径 lua_package_cpath "/path/?.so;;";
2) location ~ ^/test$ {
content_by_lua_file /path/get.lua
}
3 在get.lua文件中调用该方法
local redis = require “redis” local chash = require “chash” local function read_redis(index) local red,ok,err = redis.connect(“127.0.0.1”,index对应的端口号) if not ok then return nil,nil,err; end ---- 这里为了方便做了一个简单的封装 local ok,res,err = redis.excute(red,”get”,key) ---- 释放链接,同样做了一个简单封装 redis:release(red); return ok,res,err; end local index = chash.mod(key,摸数) ---- read data local ok,res,err = read_redis(index); // 对获取到的数据res进行一些处理
以上就是对于分片的大概处理逻辑。
4. 对于单个key数据量过大的问题,我们目前用两种方式来解决,一种是对业务数据进行简单的字符串替换,比如我们对某个数据项的字段名做精简,用更短的字符替代长的字段名;另一种方式是对整个数据进行gzip压缩;
5. 采用多机房部署,每个机房的都是一个独立的集群,redis之间也不会存在跨机房同步的问题。对于数据一致性问题,根据业务需要采用worker、mq等方式来解决。如果业务对于数据一致性要求不高,我们完全可以使用被动更新缓存和控制缓存时间来解决。
6. 对于某些业务,后端可能要调用很多服务才能完成数据组装,之前我们对于这种业务都是顺序的去调用后端依赖的服务。目前我们的做法是只要这些依赖的服务没有上下逻辑关系,我们都是并行的去调用,然后再统一组装数据。
五 架构图
六 我们后续要做的事情 1. 对单个key数据进行分片处理,这里是对超过一定大小的key值进行平均分割,放到多个redis分片实例中,最后通过ngx.location.capture_multi的方式对其进行并行调用,并将得到的数据进行组装。
2. 目前如果缓存失效我们最后一道防线是后端应用,如果后端一个用挂掉,或者由于后端的某个接口有问题,比如处理速度慢、超时等,会造成系统无法提供正常业务。后续我们考虑使用像ssdb这样的nosql数据库做一个托底方案,这样如果业务允许,当缓存和应用都出现问题我们可以使用托底方案对业务进行降级处理。
3. 后端应用和redis进行隔离部署。
已有 0 人发表留言,猛击->> 这里 <<-参与讨论ITeye推荐
- —软件人才免语言低担保 赴美带薪读研!—
正文到此结束
热门推荐










相关文章

近期评论
-
你这基本没有更新呀,最近文章显示还是2019年的文章。不符合要求哈
-
关键词:慕云博客 链接:https://www.lilun.me 描述:分享原创文字的个人博客
-
-
-
可以提供一下源码吗
-
不是商业站,鸡娃学习笔记
-
-
-
-
听他们说很厉害的样子
Loading...
![[HBLOG]公众号](http://www.liuhaihua.cn/img/qrcode_gzh.jpg)

