文本相似度判定
刘 勇 Email:lyssym@sina.com
简介
针对文本相似判定,本文提供余弦相似度和SimHash两种算法,并根据实际项目遇到的一些问题,给出相应的解决方法。经过实际测试表明:余弦相似度算法适合于短文本,而SimHash算法适合于长文本,并且能应用于大数据环境中。
余弦相似度
原理
余弦定理:
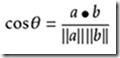
图-1 余弦定理图示
性质:
余弦值的范围在[-1,1]之间,值越趋近于1,代表两个向量的方向越趋近于0°,他们的方向更加一致,相应的相似度也越高。需要指出的是,在文本相似度判定中,因为文本特征向量定义的特殊性,其余弦值范围为[0,1],即向量夹角越趋向于90°,则两向量越不相似。
向量空间模型
VSM(Vector Space Model)把对文本内容的处理简化为向量空间中的向量运算。
概念:
1)文档(D):泛指文档或文档片段,一般表征一篇文档。
2)词汇(T):文本内容特征的基本语言单位,包含字、词、词组或短语。
3)权重(W):表征词汇T的权重,在文档D中的重要程度。
权重:
目前表征一个字词在一个文本集或者语料库中某篇文本中的重要程度的统计方法为TF-IDF(term frequency–inverse document frequency),词汇的重要性随着它在文件中出现的次数成正比增加,但同时会随着它在语料库中出现的频率成反比下降,详细内容在此不赘述。但是本文在实际项目中面临的问题是,文本集是变动的,而且变化速率比较快,因此并不适用于采用TF-IDF方法。本文采用非常简单直观的方法,即以词频来表征该词汇在文本中的重要程度(即权重)。
向量对齐:
由于在实际应用中,表征文本特征的两个向量的长度是不同的,因此必然需要对上述向量进行处理。目前存在两种方法:1)剔除掉向量中不重要的词汇,从而使得两个向量长度保持一致,目前主要依靠经验设定一些关键词来处理,但是其准确率不可保证;2)归并向量,并根据原向量是否在新向量(归并后的向量)存在,若存在则以该词汇的词频来表征,若不存在则该节点置为0,示例如下:
Text1: 我/是/中国人/
Text2: 我们/是/中国人/
Vector: 我/是/中国人/我们/
Vector1 = (1, 1, 1, 0)
Vector2 = (0, 1, 1, 1)
上述“/”为采用IK分词,智能切分后的间隔符,则归并后的向量如Vector所示,对齐后的向量分别为Vector1 和Vector2。之后则根据两向量的余弦值确定相似度。
文本特例
由于在实际项目中,本文发现了2个特例,并相应给出了解决方案。
1)长句包含短句(无需完全包含):
Text1:“贯彻强军目标出实招用实劲 努力开创部队建设新局面”
Text2:“在接见驻浙部队领导干部时强调 贯彻强军目标出实招用实劲 努力开创部队建设新局面”
上述两个文本为网络上实际的网页标题,若简单以余弦相似度来判定,其误判率是比较高的。本文解决方案为:若长句长度(中文切分后以词汇为单位表征,并非以字符为单位)为短句的1.5倍,则针对长句选定短句长度的文本内容逐个与短句进行相似度判定,直至长句结束,若中间达到预设的阈值,则跳出该循环,否则判定文本不相似。
2)文本中存在同义表述
Text1:“台湾居民明日起持台胞证可通关 无需办理签注”
Text2:“明起台胞来京无需办理签注 电子台胞证年内实施”
上述两个文本中“台胞”和“台湾居民”,“明日起”和“明起”为同义表述,可以理解为近义词,但不完全为近义词范畴。本文解决方案为引入同义词词典,鉴于中文词汇的丰富性,其能在一定程度上缓解,仍然不是根本解决之法。
应用场景及优缺点
本文目前将该算法应用于网页标题合并和标题聚类中,目前仍在尝试应用于其它场景中。
优点:计算结果准确,适合对短文本进行处理。
缺点:需要逐个进行向量化,并进行余弦计算,比较消耗CPU处理时间,因此不适合长文本,如网页正文、文档等。
余弦相似度算法源程序:

1 public class ElementDict { 2 private String term; 3 private int freq; 4 5 public ElementDict(String term, int freq) { 6 this.term = term; 7 this.freq = freq; 8 } 9 10 11 public void setFreq (int freq) { 12 this.freq = freq; 13 } 14 15 16 public String getTerm() { 17 return term; 18 } 19 20 21 public int getFreq() { 22 return freq; 23 } 24 25 }Class Element
1 import java.io.BufferedReader; 2 import java.io.File; 3 import java.io.FileInputStream; 4 import java.io.FileReader; 5 import java.io.IOException; 6 import java.io.InputStreamReader; 7 import java.util.HashMap; 8 import java.util.List; 9 import java.util.ArrayList; 10 import java.util.Map; 11 12 import org.apache.lucene.analysis.TokenStream; 13 import org.apache.lucene.analysis.tokenattributes.CharTermAttribute; 14 import org.wltea.analyzer.lucene.IKAnalyzer; 15 16 17 public class TextCosine { 18 private Map<String, String> map= null; 19 20 public TextCosine() { 21 map = new HashMap<String, String>(); 22 try { 23 InputStreamReader isReader = new InputStreamReader(new FileInputStream(TextCosine.class.getResource("synonyms.dict").getPath()), "UTF-8"); 24 BufferedReader br = new BufferedReader(isReader); 25 String s = null; 26 while ((s = br.readLine()) !=null) { 27 String []synonymsEnum = s.split("→"); 28 map.put(synonymsEnum[0], synonymsEnum[1]); 29 } 30 br.close(); 31 } catch (IOException e) { 32 e.printStackTrace(); 33 } 34 } 35 36 37 public List<ElementDict> tokenizer(String str) { 38 List<ElementDict> list = new ArrayList<ElementDict>(); 39 IKAnalyzer analyzer = new IKAnalyzer(true); 40 try { 41 TokenStream stream = analyzer.tokenStream("", str); 42 CharTermAttribute cta = stream.addAttribute(CharTermAttribute.class); 43 stream.reset(); 44 int index = -1; 45 while (stream.incrementToken()) { 46 if ((index = isContain(cta.toString(), list)) >= 0) { 47 list.get(index).setFreq(list.get(index).getFreq() + 1); 48 } 49 else { 50 list.add(new ElementDict(cta.toString(), 1)); 51 } 52 } 53 analyzer.close(); 54 } catch (IOException e) { 55 e.printStackTrace(); 56 } 57 return list; 58 } 59 60 61 public int isContain(String str, List<ElementDict> list) { 62 for (ElementDict ed : list) { 63 if (ed.getTerm().equals(str)) { 64 return list.indexOf(ed); 65 } else if (map.get(ed.getTerm())!= null && map.get(ed.getTerm()).equals(str)) { 66 return list.indexOf(ed); 67 } 68 } 69 return -1; 70 } 71 72 73 public List<String> mergeTerms(List<ElementDict> list1, List<ElementDict> list2) { 74 List<String> list = new ArrayList<String>(); 75 for (ElementDict ed : list1) { 76 if (!list.contains(ed.getTerm())) { 77 list.add(ed.getTerm()); 78 } else if (!list.contains(map.get(ed.getTerm()))) { 79 list.add(ed.getTerm()); 80 } 81 } 82 83 for (ElementDict ed : list2) { 84 if (!list.contains(ed.getTerm())) { 85 list.add(ed.getTerm()); 86 } else if (!list.contains(map.get(ed.getTerm()))) { 87 list.add(ed.getTerm()); 88 } 89 } 90 return list; 91 } 92 93 94 public int anslysisTerms(List<ElementDict> list1, List<ElementDict> list2) { 95 int len1 = list1.size(); 96 int len2 = list2.size(); 97 if (len2 >= len1 * 1.5) { 98 List<ElementDict> newList = new ArrayList<ElementDict>(); 99 for (int i = 0; i + len1 <= len2; i++) { 100 for (int j = 0; j < len1; j++) 101 newList.add(list2.get(i+j)); 102 103 newList = adjustList(newList, list2, len2, len1, i); 104 if (getResult(analysis(list1, newList))) 105 return 1; 106 else 107 newList.clear(); 108 } 109 } else if (len1 >= len2 * 1.5) { 110 List<ElementDict> newList = new ArrayList<ElementDict>(); 111 for (int i = 0; i + len2 <= len1; i++) { 112 for (int j = 0; j < len2; j++) 113 newList.add(list1.get(i+j)); 114 115 newList = adjustList(newList, list1, len1, len2, i); 116 if (getResult(analysis(newList, list2))) 117 return 1; 118 else 119 newList.clear(); 120 } 121 } else { 122 if (getEasyResult(analysis(list1, list2))) 123 return 1; 124 } 125 return 0; 126 } 127 128 129 public List<ElementDict> adjustList(List<ElementDict> newList, List<ElementDict> list, int lenBig, int lenSmall, int index) { 130 int gap = lenBig -lenSmall; 131 int size = (gap/2 > 2) ? 2: gap/2; 132 if (index < gap/2) { 133 for (int i = 0; i < size; i++) { 134 newList.add(list.get(lenSmall+index+i)); 135 } 136 } else { 137 for (int i = 0; i > size; i++) { 138 newList.add(list.get(lenBig-index-i)); 139 } 140 } 141 return newList; 142 } 143 144 145 public double analysis(List<ElementDict> list1, List<ElementDict> list2) { 146 List<String> list = mergeTerms(list1, list2); 147 List<Integer> weightList1 = assignWeight(list, list1); 148 List<Integer> weightList2 = assignWeight(list, list2); 149 return countCosSimilariry(weightList1, weightList2); 150 } 151 152 153 public List<Integer> assignWeight(List<String> list, List<ElementDict> list1) { 154 List<Integer> vecList = new ArrayList<Integer>(list.size()); 155 boolean isEqual = false; 156 for (String str : list) { 157 for (ElementDict ed : list1) { 158 if (ed.getTerm().equals(str)) { 159 isEqual = true; 160 vecList.add(new Integer(ed.getFreq())); 161 } else if (map.get(ed.getTerm())!= null && map.get(ed.getTerm()).equals(str)) { 162 isEqual = true; 163 vecList.add(new Integer(ed.getFreq())); 164 } 165 } 166 167 if (!isEqual) { 168 vecList.add(new Integer(0)); 169 } 170 isEqual = false; 171 } 172 return vecList; 173 } 174 175 176 public double countCosSimilariry(List<Integer> list1, List<Integer> list2) { 177 double countScores = 0; 178 int element = 0; 179 int denominator1 = 0; 180 int denominator2 = 0; 181 int index = -1; 182 for (Integer it : list1) { 183 index ++; 184 int left = it.intValue(); 185 int right = list2.get(index).intValue(); 186 element += left * right; 187 denominator1 += left * left; 188 denominator2 += right * right; 189 } 190 try { 191 countScores = (double)element / Math.sqrt(denominator1 * denominator2); 192 } catch (ArithmeticException e) { 193 e.printStackTrace(); 194 } 195 return countScores; 196 } 197 198 199 public boolean getResult(double scores) { 200 System.out.println(scores); 201 if (scores >= 0.85) 202 return true; 203 else 204 return false; 205 } 206 207 208 public boolean getEasyResult(double scores) { 209 System.out.println(scores); 210 if (scores >= 0.75) 211 return true; 212 else 213 return false; 214 } 215 216 }Class TextCosine
备注:同义词词典“synonyms.dict”文件较大,完全可以自己构建,在此就不赘述了。
SimHash
SimHash为Google处理海量网页的采用的文本相似判定方法。该方法的主要目的是 降维 ,即将高维的特征向量映射成f-bit的指纹,通过比较两篇文档指纹的汉明距离来表征文档重复或相似性。
过程
该算法设计十分精巧,主要过程如下:
1. 文档特征量化为向量;
2. 计算特征词汇哈希值,并辅以权重进行量化;
3. 针对f-bit指纹,按位进行叠加运算;
4. 针对叠加后的指纹,若对应位为正,则标记为1,否则标记为0。
备注:此处f-bit指纹,可以根据应用需求,定制为16位、32位、64位或者其它位数等。
如图-2所示,为SimHash作者Charikar在论文中的图示,本文结合实际项目解释如下:Doc表征一篇文本,feature为该文本经过中文分词后的词汇组合,按列向量组织,weight为对应词汇在文本中的词频,之后经过某种哈希计算得出哈希值,见图中1和0的组合,剩余部分不再赘述。需要指出,Charikar在论文中并未指定需要采用哪种哈希函数,本文作者认为,只要哈希计算值能够 均衡化、分散化 ,哈希函数可以根据实际应用场景进行设计,本文在实际的项目中自行设计哈希函数,虽未经过完全验证,但是测试结果表明,该函数当前能够满足需求。
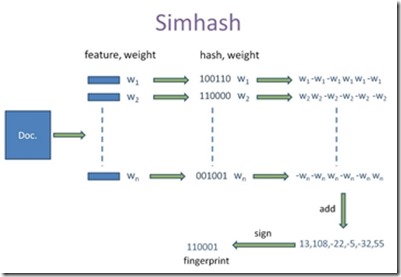
图-2 SimHash处理过程
汉明距离
汉明距离应用于数据传输差错控制编码,它表示两个(相同长度)字对应位不同的数量。鉴于SimHash最后计算出的指纹采用0和1进行组织,故而用其来衡量文档相似性或者重复性,该部分详细内容在此不再赘述。
应用场景与优缺点
本文目前将该算法应用于话题发现和内容聚合等场景中,同时也在尝试其它应用场景。
优点:文本处理速率快,计算后的指纹能够存储于数据库,因此对海量文本相似判定非常适合。
缺点:由于短文本的用于哈希计算的数据源较少,因此短文本相似度识别率低。
SimHash算法源程序:
1 public class TermDict { 2 private String term; 3 private int freq; 4 5 public TermDict(String term, int freq) 6 { 7 this.term = term; 8 this.freq = freq; 9 } 10 11 public String getTerm() { 12 return term; 13 } 14 15 public void setTerm(String term) { 16 this.term = term; 17 } 18 19 public int getFreq() { 20 return freq; 21 } 22 23 public void setFreq(int freq) { 24 this.freq = freq; 25 } 26 27 }Class TermDict
1 import java.io.IOException; 2 import java.math.BigInteger; 3 import java.util.List; 4 import java.util.ArrayList; 5 6 import org.wltea.analyzer.lucene.IKAnalyzer; 7 import org.apache.lucene.analysis.TokenStream; 8 import org.apache.lucene.analysis.tokenattributes.CharTermAttribute; 9 10 public class SimHash { 11 private String tokens; 12 private int hashBits = 64; 13 private int distance = 5; 14 15 public SimHash(String tokens) 16 { 17 this.tokens = tokens; 18 } 19 20 21 public SimHash(String tokens, int hashBits, int distance) 22 { 23 this.tokens = tokens; 24 this.hashBits = hashBits; 25 this.distance = distance; 26 } 27 28 29 public List<TermDict> tokenizer() 30 { 31 List<TermDict> terms = new ArrayList<TermDict>(); 32 IKAnalyzer analyzer = new IKAnalyzer(true); 33 try { 34 TokenStream stream = analyzer.tokenStream("", this.tokens); 35 CharTermAttribute cta = stream.addAttribute(CharTermAttribute.class); 36 stream.reset(); 37 int index = -1; 38 while (stream.incrementToken()) 39 { 40 if ((index = isContain(cta.toString(), terms)) >= 0) 41 { 42 terms.get(index).setFreq(terms.get(index).getFreq()+1); 43 } 44 else 45 { 46 terms.add(new TermDict(cta.toString(), 1)); 47 } 48 } 49 analyzer.close(); 50 } catch (IOException e) { 51 e.printStackTrace(); 52 } 53 return terms; 54 } 55 56 57 public int isContain(String str, List<TermDict> terms) 58 { 59 for (TermDict td : terms) 60 { 61 if (str.equals(td.getTerm())) 62 { 63 return terms.indexOf(td); 64 } 65 } 66 return -1; 67 } 68 69 70 public BigInteger simHash(List<TermDict> terms) 71 { 72 int []v = new int[hashBits]; 73 for (TermDict td : terms) 74 { 75 String str = td.getTerm(); 76 int weight = td.getFreq(); 77 BigInteger bt = shiftHash(str); 78 for (int i = 0; i < hashBits; i++) 79 { 80 BigInteger bitmask = new BigInteger("1").shiftLeft(i); 81 if ( bt.and(bitmask).signum() != 0) 82 { 83 v[i] += weight; 84 } 85 else 86 { 87 v[i] -= weight; 88 } 89 } 90 } 91 92 BigInteger fingerPrint = new BigInteger("0"); 93 for (int i = 0; i < hashBits; i++) 94 { 95 if (v[i] >= 0) 96 { 97 fingerPrint = fingerPrint.add(new BigInteger("1").shiftLeft(i)); // update the correct fingerPrint 98 } 99 } 100 return fingerPrint; 101 } 102 103 104 public BigInteger shiftHash(String str) 105 { 106 if (str == null || str.length() == 0) 107 { 108 return new BigInteger("0"); 109 } 110 else 111 { 112 char[] sourceArray = str.toCharArray(); 113 BigInteger x = BigInteger.valueOf((long) sourceArray[0] << 7); 114 BigInteger m = new BigInteger("131313"); 115 for (char item : sourceArray) 116 { 117 x = x.multiply(m).add(BigInteger.valueOf((long)item)); 118 } 119 BigInteger mask = new BigInteger("2").pow(hashBits).subtract(new BigInteger("1")); 120 boolean flag = true; 121 for (char item : sourceArray) 122 { 123 if (flag) 124 { 125 BigInteger tmp = BigInteger.valueOf((long)item << 3); 126 x = x.multiply(m).xor(tmp).and(mask); 127 } 128 else 129 { 130 BigInteger tmp = BigInteger.valueOf((long)item >> 3); 131 x = x.multiply(m).xor(tmp).and(mask); 132 } 133 flag = !flag; 134 } 135 136 if (x.equals(new BigInteger("-1"))) 137 { 138 x = new BigInteger("-2"); 139 } 140 return x; 141 } 142 } 143 144 145 public BigInteger getSimHash() 146 { 147 return simHash(tokenizer()); 148 } 149 150 151 public int getHammingDistance(SimHash hashData) 152 { 153 BigInteger m = new BigInteger("1").shiftLeft(hashBits).subtract(new BigInteger("1")); 154 System.out.println(getFingerPrint(getSimHash().toString(2))); 155 System.out.println(getFingerPrint(hashData.getSimHash().toString(2))); 156 BigInteger x = getSimHash().xor(hashData.getSimHash()).and(m); 157 int tot = 0; 158 while (x.signum() != 0) 159 { 160 tot += 1; 161 x = x.and(x.subtract(new BigInteger("1"))); 162 } 163 System.out.println(tot); 164 return tot; 165 } 166 167 168 public String getFingerPrint(String str) 169 { 170 int len = str.length(); 171 for (int i = 0; i < hashBits; i++) 172 { 173 if (i >= len) 174 { 175 str = "0" + str; 176 } 177 } 178 return str; 179 } 180 181 182 public void getResult(SimHash hashData) 183 { 184 if (getHammingDistance(hashData) <= distance) 185 { 186 System.out.println("match"); 187 } 188 else 189 { 190 System.out.println("false"); 191 } 192 } 193 194 }Class SimHash
备注:源程序中“131313”只是作者挑选的一个较大的素数而已,不代表特别含义,该数字可以根据需求进行设定。
作者:志青云集
出处: http://www.cnblogs.com/lyssym/p/4880896.html
如果,您认为阅读这篇博客让您有些收获,不妨点击一下右下角的【推荐】。
如果,您希望更容易地发现我的新博客,不妨点击一下左下角的【关注我】。
如果,您对我的博客所讲述的内容有兴趣,请继续关注我的后续博客,我是【志青云集】。
本文版权归作者和博客园共有,欢迎转载,但未经作者同意必须保留此段声明,且在文章页面明显位置给出原文连接。
正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](http://www.liuhaihua.cn/img/qrcode_gzh.jpg)

