数据聚合 & 分组:新一代系统监控的核心功能
遥想 2015 年 8 月 17 日,Cloud Insight 还在梳理功能原型,畅想 Cloud Insight 存在的意义: 为什么阿里云用户需要使用 Cloud Insight 来加强管理 。
而今,我们就已经实现了这样的功能:
使用标签来实现数据的聚合和分组。
相信使用过 OpenTSDB 或者 InfluxDB 的人都知道标签的存在:Tag。这也是为什么越来越多 Zabbix 或者 Nagios 用户迁移至 OpentsDB 来自建运维监控系统的原因。

如果所示,Zabbix 只提供单台 Host 的 Disk 使用量。如果 3 台主机,都同属于一个组 Mi-Kafka,想要知道这个组的总体 Disk 使用量,是无法得知的。
从而,就算线上系统发生了故障,要在短期内知道, 到底是哪个模块的哪个部分出了哪样的问题 ,所需要的经验和时长都是很大的。
而 OpenTSDB 和 StatsD 的出现改变了现状。
运维 2.0 时代
在非常早期的时候,淘宝团队就引入了 OpenTSDB 来辅助他们的运维监控。详情见: OpenTSDB监控系统的研究和介绍 。
随后的几年,云计算和 SaaS 的兴起,国外也出现了多种采用 StatsD 和 OpenTSDB 的开源工具搭建的 SaaS 服务:Boundary、CopperEgg、Datadog 等等。
他们都不约而同地采用了同一种产品逻辑,也是 Cloud Insight 的产品逻辑,也是时间序列数据库的逻辑:
- 任何的性能指标,都作为时间序列数据被采集、被处理;
- 任何的 Host 等归属于性能指标的属性,都作为指标的标签信息。
而在产品逻辑上,则表现为:

Cloud Insight 通过 3 个步骤达到操作系统、数据库、中间件,以及未来通过 Developer API 对接进来的所有 Metric 进行处理:
- Cloud Insight Agent 采集并处理 Metric;
- 在平台服务仪表盘和自定义仪表盘中,提供 Metric 聚合、分组、统计运算、基本数学运算等操作;
- 针对操作的结果,提供曲线图、柱状图等多样化的展现形式。
数据聚合和分组
在 Beta v 0.2.1 中,我们实现了数据的聚合和分组。沿袭了 OpenTSDB 的查询方式:用一种类 SQL 的方式来查询指标。
具体操作可以访问 Cloud Insight 文档中心 • Metric 查询 。
接下来我们会介绍 Cloud Insight 已经实现的 Metric 的查询,以及其中的数据聚合和分组。
语法
Aggregation: MetricName {FromTag} by {TagKey}
在介绍语法前,我们先通过一组样本来解释 Metric 查询的语法。
| Series | MetricName | TagValue: Host | TagValue: Owner |
|---|---|---|---|
| A | system.cpu.idle | ChengMoMacAir | chengmo |
| B | system.cpu.idle | UbuntuChengMo | chengmo |
| C | system.cpu.idle | WZL-CentOS | wangzhili |
| Series | 00:00 | 01:00 | 02:00 | 03:00 | 04:00 | 05:00 |
|---|---|---|---|---|---|---|
| A | 0.3 | 0.5 | 0.1 | 0.2 | 0.8 | 0.1 |
| B | 0.8 | 0.3 | 0.7 | 0.8 | 0.9 | 0.3 |
| C | 0.6 | 0.2 | 0.4 | 0.6 | 0.1 | 0.1 |
Aggregation 和 FromTag
- Aggregation:聚合算子。指 Metric 查询范围 FromTag 所查询到的多条 series 通过 avg、max、min、sum 哪种方式聚合。
- FromTag:查询范围。指 Metric 所需聚合的 series 的查询条件。
如:
max: system.cpu.idle {host:ChengMoMacAir, host:UbuntuChengMO}
所得的结果是:
| Series | 00:00 | 01:00 | 02:00 | 03:00 | 04:00 | 05:00 |
|---|---|---|---|---|---|---|
| A | 0.3 | 0.5 | 0.1 | 0.2 | 0.8 | 0.1 |
| B | 0.8 | 0.3 | 0.7 | 0.8 | 0.9 | 0.3 |
| Output | 0.8 | 0.5 | 0.7 | 0.8 | 0.9 | 0.3 |
同样,上述查询也可以简化成:
max: system.cpu.idle {owner:chengmo}
这就是标签管理在 Cloud Insight 的重要性啦。
by 其实就是 group_by
Cloud Insight 还支持类似 SQL 的 group_by 查询语法。这个在查看:
- 多个磁盘分区的容量
- Docker 中不同 Container 的性能消耗
都是非常有用的。还是以上诉例子举例,如果我们想要看每个 host 的 CPU 空闲率:
avg: system.cpu.idle {} by {host}
此时,第一个 {FromTag} 缺省代表从所有 Metrics 中查询数据。如图所示,得到以下图表:
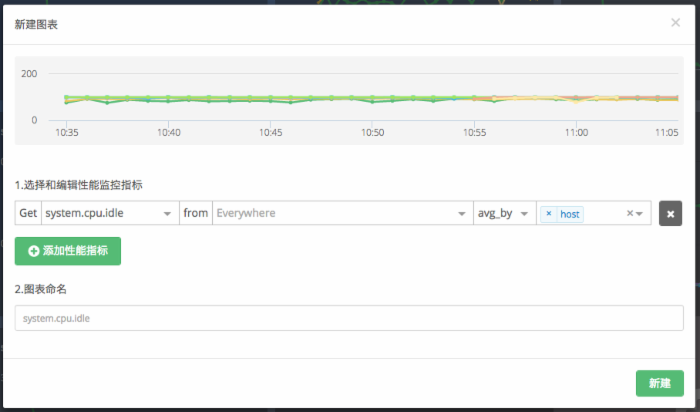
在实际的测试环境中,由于我们有 6 台测试主机,所以会得到如下的曲线。并且,当鼠标悬停至曲线时,下方的悬停窗口会分别显示 6 台主机的 system.cpu.idle 。
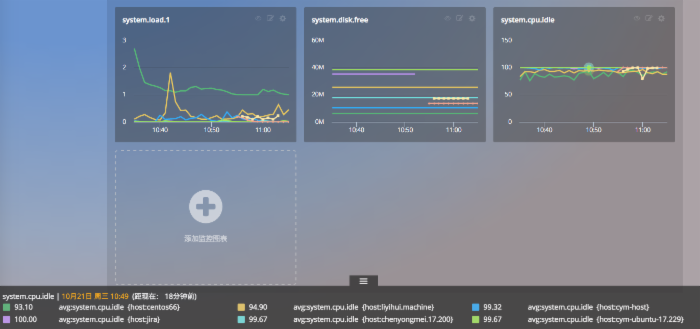
灵活查询
聚合和分组并存
除开单纯的聚合和分组,Cloud Insight 还支持聚合和分组的复合查询。如:
avg: system.cpu.idle {} by {owner}
| Series | MetricName | TagValue: Host | TagValue: Owner |
|---|---|---|---|
| A | system.cpu.idle | ChengMoMacAir | chengmo |
| B | system.cpu.idle | UbuntuChengMo | chengmo |
| C | system.cpu.idle | WZL-CentOS | wangzhili |
此时,虽然有 3 个 host,但是分组是以 owner 来进行分组。所以,A 与 B 会聚合为一条曲线,而 C 和 A&B 的关系是分组的关系。
| Series | 00:00 | 01:00 | 02:00 | 03:00 | 04:00 | 05:00 |
|---|---|---|---|---|---|---|
| A | 0.3 | 0.5 | 0.1 | 0.2 | 0.8 | 0.1 |
| B | 0.8 | 0.3 | 0.7 | 0.8 | 0.9 | 0.3 |
| C | 0.6 | 0.2 | 0.4 | 0.6 | 0.1 | 0.1 |
| Output A&B | 0.55 | 0.4 | 0.4 | 0.5 | 0.85 | 0.2 |
| Output C | 0.6 | 0.2 | 0.4 | 0.6 | 0.1 | 0.1 |
多条件查询
FromTag 可以承接多个条件,如上文提到的:
max: system.cpu.idle {host:ChengMoMacAir, host:UbuntuChengMO}
查询到是两个 Host 的聚合结果。那么,如果是以下查询呢:
max: system.cpu.idle {host:ChengMoMacAir, owner:wangzhili}
此时,查询到结果为 NULL 。因为,Metric 查询遵循以下原则:
- 同一 Tag Key,Metric 查询求并集;
- 不同 Tag Key,Metric 查询求交集。
也就是说,上述查询分别代表:
- 我想查询
host为ChengMoMacAir和host:UbuntuChengMO的聚合结果 - 我想查询
host为ChengMoMacAir且owner为wangzhili的聚合结果
自然,根据表格,我们发现这样的 Host 是不存在的,故而结果为 NULL 。
我们之所以这么设计,是因为此类思考更符合人的思维习惯:
- 当人们选择多个 host 时,自然而然想到的是这些 host 的求和结果,即:同一 Tag Key 求并集;
- 当人们选择某个 host,又再次选择另一个 Tag 时,想到的是在这个 host 下满足这些 tag 的结果,即:不同 Tag Key 求交集。
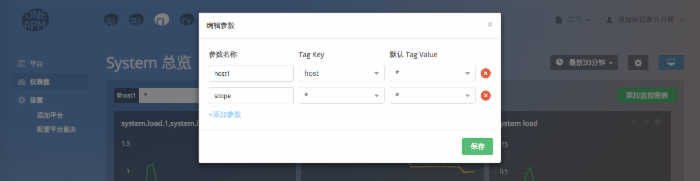
参数查询
Cloud Insight 还添加了 参数 来提取出 {FromTag} ,可以让用户不用每次都修改 {FromTag} 来查看 Metric;而只需在参数下拉框中选择 {FromTag} 来动态查询 Metric。
正文到此结束
热门推荐










相关文章

近期评论
-
你这基本没有更新呀,最近文章显示还是2019年的文章。不符合要求哈
-
关键词:慕云博客 链接:https://www.lilun.me 描述:分享原创文字的个人博客
-
-
-
可以提供一下源码吗
-
不是商业站,鸡娃学习笔记
-
-
-
-
听他们说很厉害的样子
Loading...
![[HBLOG]公众号](http://www.liuhaihua.cn/img/qrcode_gzh.jpg)

