【程序员眼中的统计学(9)】总体和样本的估计:进行预测
总体和样本的估计:进行预测
作者 白宁超
2015年10月15日18:30:07
摘要:程序员眼中的统计学系列是作者和团队共同学习笔记的整理。首先提到统计学,很多人认为是经济学或者数学的专利,与计算机并没有交集。诚然在传统学科中,其在以上学科发挥作用很大。然而随着科学技术的发展和机器智能的普及,统计学在机器智能中的作用越来越重要。本系列统计学的学习基于 《深入浅出统计学》 一书( 偏向代码实现,需要读者有一定基础,可以参见后面PPT学习 )。正如(吴军)先生在 《数学之美》 一书中阐述的, 基于统计和数学模型对机器智能发挥重大的作用。诸如:语音识别、词性分析、机器翻译等世界级的难题也是从统计中找到开启成功之门钥匙的 。尤其是在自然语言处理方面更显得重要,因此,对统计和数学建模的学习是尤为重要的。最后感谢团队所有人的参与 。( 本文原创,转载注明出处 : 总体和样本的估计:进行预测 )
目录
【程序员眼中的统计学(1)】信息图形化:第一印象
【程序员眼中的统计学(2)】 集中趋势度量:分散性、变异性、强大的距
【程序员眼中的统计学(3)】概率计算:把握机会
【程序员眼中的统计学(4)】 离散概率分布的运用:善用期望
【程序员眼中的统计学(5)】 排列组合:排序、排位、排
【程序员眼中的统计学(6)】 几何分布、二项分布及泊松分布:坚持离散
【程序员眼中的统计学(7)】 正态分布的运用:正态之美
【程序员眼中的统计学(8)】 统计抽样的运用:抽取样本
【程序员眼中的统计学(9)】 总体和样本的估计:进行预测
【程序员眼中的统计学(10)】 假设检验的运用:研究证据
【程序员眼中的统计学(11)】卡方分布的应用
【程序员眼中的统计学(12)】 相关与回归:我的线条如何?
1样本均值描述
1.1样本均值的定义
样本均值是我们能为总体均值做出的最好估计。在我们根据现有信息得到的数值中,样本均值是最有可能被作为总体均值的数值。另外样本均值被称为总体均值的点估计量。也就是说,作为一个基于样本数据的计算结果,它给出了总体均值的良好估计。
1.2样本均值符号定义和公式
这张图显示了样本的分布情况以及可以基于样本而期望的总体分布情况。根据已知的情况,样本均值是我们能为总体均值做出的最好估计,所以在这我们把样本均值称为总体均值的点估计量。

符号(读作"缪")表示总体均值,为了不至于混淆,我们用(读作"X拔")表示样本的均值。是的样本对等量,它的计算方法如下:
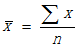
而用û(读作"缪hat")表示总体均值的点估计量,根据上式写出总体的点估计量的简明表达式,由于可以用样本均值估计总体均值,因此:
û = 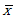
1.3样本均值分布算法描述
类描述
类源码见源程序: predict.vo. SampleMean.java
方法描述
输入一个数组,返回样本均值
类和方法调用的接口
见源程序: predict.vo. SampleMean.java
SampleMean.java 下有方法: public double run(double[] s)
调用封装类: predict.utils.ScoreUtil.java
ScoreUtil.java 下有方法: subZeroAndDot(String s)
package vo; import utils.ScoreUtil; /** * @(#)SampleMean.java * @Comments 样本均值 * @description 样本均值是对总体均值的最好估计,另外样本均值被称为总体均值的点估计量。符号μ(读作“缪”)表示总体均值, * 所以我们用“X拔”表示样本的均值, 样本均值等于样本中所有数据之和除以样本的大小。 * @author gyz * @date 2015-8-15 * @since JDK1.8 */ public class SampleMean{ /** * @param s 输入一个数组:样本数据 * @return sampleMean 返回样本均值 * @date 2015-8-15 * @author gyz */ public double run(double[] s) { double sum = 0.0; double sampleMean = 0.0; for(int i=0;i<s.length;i++){ sum += s[i]; } sampleMean = sum/s.length; //并将结果保留3位小数(四舍五入) String fx_String = ScoreUtil.getFractionDigits(sampleMean,3); sampleMean = Double.valueOf(fx_String); System.out.println("样本均值:"+sampleMean); return sampleMean ; } } 1.4样本均值使用场景
当数据或事件数量十分庞大时,很难决定从何处着手收集数据,我们就可以有效地、正确地采用抽样收集数据。我们可以使用样本均值估计数据的总体均值。
1.5样本均值优缺点
1.5.1样本均值优点
可以样本数据的均值估计总体均值,可以由此得知总体方差的期望形态。
1.5.2. 样本均值缺点
通过样本均值估计总体均值不一定是非常正确的,也会存在一些误差,或者需要在进行一些验证等。
1.6 样本均值算法的输入数据
* @param s 输入一个数组:样本数据
1.7样本均值算法的输出结果
* @return sampleMean 返回样本均值
1.8样本均值算法异常和误差
1.8.1样本均值算法可能异常或误差
异常:输入数据不合法;
误差:保留小数位数造成不精确
1.8.2样本均值算法异常或误差处理
异常:解决,输入不合法给予提示。
误差:解决,进行小数点位数自定义保留封装,根据具体精度进行设置。
2估计总体方差的相关描述
2.1 估计总体方差的定义
一个数据集的方差所量度的是数值与均值的偏离程度。当你选择一个样本后,相比总体,你拥有的数值数量变少了,因此,与总体的数值偏离均值的程度相比,样本中的数值更有可能以紧密的方式聚集在均值周围,也就是说,极端数值出现在样本中的可能性下降,这是因为总的来说这样的数值变小了。所以样本数据的方差可能不是总体方差的最好估计办法。我们需要找到一个更好的办法来估计总体方差,也就是说,找到样本数据的某个函数,而这个函数所得出的结果要稍微大于所有样本数值的方差。
2.2估计总体方差符号定义和公式
符号 表示总体方差,所以我们用一个略有变化的 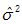 表示总体方差的点估计量,n为样本的大小,估计总体方差计算公式如下:
表示总体方差的点估计量,n为样本的大小,估计总体方差计算公式如下: 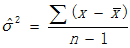
总体方差点估计量的式子通常写作 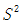 ,由此得到:
,由此得到: 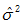 =
= 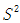
2.3总体方差和估计总体方差的使用场景
如果想求确切的总体方差,且拥有全部总体数据n,总体均值为,则可以使用下式计算: 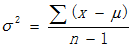
如果需要求样本数据估计总体方差,则需要用 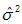 公式,除数为n-1。
公式,除数为n-1。
2.4样本均值分布算法描述
类描述
类源码见源程序: predict.vo. EstimateGeneralityVariance.java
方法描述
输入一个样本数据的数组,返回估计总体方差值
类和方法调用的接口
见源程序: predict.vo. EstimateGeneralityVariance.java
SampleMean.java 下有方法: public double run(double[] s)
调用封装类: predict.utils.ScoreUtil.java
ScoreUtil.java 下有方法: subZeroAndDot(String s)
package vo; import utils.ScoreUtil; /** * @(#)EstimateGeneralityVariance.java * @Comments 估计总体方差 * @description 符号σ^2 表示总体方差,估计总体方差等于样本中的每一个数值减去样本均值,所得之差取平方和数, * 然后将所有平方和相加,再除以样本大小n减1。 * @author gyz * @date 2015-8-15 * @since JDK1.8 */ public class EstimateGeneralityVariance { /** * * @param s 输入一个数组:样本数据 * @return egv 返回估计总体方差值 */ public double run(double[] s) { SampleMean sm = new SampleMean(); double sampleMean = sm.run(s); double different= 0.0; double egv; int n = s.length; for(int i=0;i<n;i++){ different = (s[i]- sampleMean)*(s[i]- sampleMean); } egv = different/(n-1); //并将结果保留3位小数(四舍五入) String fx_String = ScoreUtil.getFractionDigits(egv,3); egv = Double.valueOf(fx_String); System.out.println("估计总体方差值:"+egv); return egv ; } } 2.5估计总体方差使用场景
当数据或事件数量十分庞大时,很难决定从何处着手收集数据,我们就可以有效地、正确地采用抽样收集数据。我们可以使用样本数据估计数据的总体方差。
2.6估计总体方差优缺点
2.6.1估计总体方差优点
我么使用样本数据估计总体方差,可以由此得知总体样本的期望形态。
2.6.2. 估计总体方差缺点
通过使用样本数据估计总体方差不一定是非常正确的,也会存在一些误差,或者需要在进行一些验证等。
2.7 估计总体方差算法的输入数据
* @param s 输入一个数组:样本数据
2.8样本均值算法的输出结果
* @return egv 返回估计总方差值
2.9样本均值算法异常和误差
2.9.1样本均值算法可能异常或误差
异常:输入数据不合法;
误差:保留小数位数造成不精确
2.9.2样本均值算法异常或误差处理
异常:解决,输入不合法给予提示。
误差:解决,进行小数点位数自定义保留封装,根据具体精度进行设置。
3比例的抽样分布描述
3.1比例抽样分布的定义
如果从一个总体中用相同的方法抽取许多大小相同但存在差异的样本,然后用每个样本的某个属性形成一个分布,所得结果称为抽样分布。由此得出,用每个样本的比例形成的抽样分布就是"比例抽样分布"。比例抽样分布是一种概率分布,由所有大小为n的可能样本的各种比例构成。如果我们知道这些比例的分布,就能用这个分布求出某一个特定样本的比例的发生概率。
3.2比例抽样分布符号定义
已知总体中红色糖球的比例,用p(proportion)表示,每一大盒糖球其实就是从糖球总体中取出的一个样本。样本的大小用n来表示。如果随机变量X代表样本中的红色糖球的数目,则X~B(n,p)。样本中的红色糖球的比例取决于X(样本中的红色糖球的数目),即比例本身是一个随机变量,用P s 表示,且P s =X/n。可以取出大小为n的所有可能样本,每一个可能样本会包含n颗糖球,每一盒样本中红色糖球的数量会符合相同的分布。利用所有可能的样本,我们能得出所有样本比例的分布,该分布称作"比例抽样分布",或者称作" P s 的分布"。
3.3比例抽样分布计算步骤
1 查看与我们的特定样本大小相同的所有样本。
如果我们有一个大小为n的样本,就要考虑所有大小为n可能样本,在本例中,盒子的糖球数量为100,因此n为100。
2 观察所有样本形成的分布,然后求出比例的期望和方差。
每一样本都有自己的情况,因此每一个包装盒里的红色糖球的比例都有可能发生变化。我们用随机变量X代表样本中的红色糖球的数目,则 X~B(n,p) ,其中n=100,p=0,25。样本中红色糖球的比例取决于X(样本中红色糖球的数据),即比例本身是一个随机变量,可以将此记为Ps , P s = X/n。所以 P s 的期望和方差分别如下: E(P s ) = p 和 Var(P s ) = 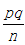
3 得出上述比例的分布后,利用该分布求出概率。
当n很大时,Ps的分布接近正态分布。即当n>30的时候,Ps符合正态分布,利用正态分布解答我们的概率问题。但是每个样本都是离散的,因此在计算概率时,需要进行连续性修正。P s 的正态分布如下:
3.4比例抽样分布使用场景
当数据或事件数量十分庞大时,很难决定从何处着手收集数据,我们就可以有效地、正确地采用抽样收集数据。从一个已知总体中取出某个样本的比例的时候,需要得知样本的期望形态,即可使用比例抽样分布。
3.5比例抽样分布优缺点
-
比例抽样分布优点 : 可以使用比例的抽样分布求出从一个已知总体中取出的某个样本的比例的概率,可以由此得知样本的期望形态。
-
比例抽样 分布缺点 : 通过比例抽样分布得出的样本的期望不一定是非常正确的,也会存在一些误差,或者需要在进行一些验证等。
3.6 比例抽样分布算法的输入数据
* @param n 样本大小
* @param p 总体中某一类的所占比例
* @param x 你 所要求比例抽样分布概率的随机变量
3.7比例抽样分布算法的输出结果
输出中间结果
* @return E(Ps) 比例抽样分布的期望E(Ps)
* @return Var(Ps) 比例抽样分布的方差Var(Ps)
输出最终结果
* @return 小于或等于符合正态分布的随机变量X的概率值
3.8比例抽样分布算法异常和误差
3.8.1比例抽样分布算法可能异常或误差
异常:输入数据不合法
误差:保留小数位数造成不精确
3.8.2比例抽样分布概率算法异常或误差处理
异常:解决,输入不合法给予提示。
误差:解决,进行小数点位数自定义保留封装,根据具体精度进行设置
3.9比例抽样分布算法描述
类的描述
类源码见源程序: predict.vo.ProportionSampleDistribution.java
方法描述
通过对需要计算比例抽样分布的均值和标准差进行计算得出具体标准分再通过调用 org.apache.commons.math3.distribution 类来实现。
类和方法调用的接口
类源码见源程序: predict.vo.ProportionSampleDistribution.java
ProportionSampleDistribution.java 下有如下方法:
public static double calculateExpectedValue(int n,double p)
// 比例抽样分布的期望
public static double calculateVariance(int n,double p)
// 比例抽样分布的方差
cumulativeProbability(double z)
// 需要求符合正态分布的比例抽样分布的标准分。
调用封装方法:
predict.utils.ScoreUtil.java 下有如下方法: subZeroAndDot(String s)
// 对传入的数保留 3 位小数
package vo; import org.apache.commons.math3.distribution.NormalDistribution; import utils.ScoreUtil; /** * @(#)ProportionSampleDistribution.java * @Comments 比例抽样分布(求期望和方差) * @description 样本中某一类的数目X符合二项分布B(n,p),样本中某一类所占的比例是一个随机变量,记为Ps,且Ps=X/n * @author gyz * @date 2015-8-15 @since JDK1.8 */ public class ProportionSampleDistribution { /** * 计算比例抽样分布的期望 * @param n 样本大小 * @param p 总体中某一类的所占比例 * @return 比例抽样分布的期望E(Ps)=E(X/n)=E(X)/n */ public static double calculateExpectedValue(int n,double p){ //计算二项分布B(n,p)的期望 double bEx = n*p; //利用总体期望求样本期望:E(Ps)=E(X/n)=E(X)/n double EPs = bEx/n; //并将结果保留3位小数(四舍五入) String EPs_String = ScoreUtil.getFractionDigits(EPs, 3); EPs = Double.valueOf(EPs_String); System.out.println("比例抽样分布的期望:"+EPs); return EPs; } /** * 计算比例抽样分布的方差 * @param n 样本大小 * @param p 总体中某一类的所占比例 * @return 比例抽样分布的方差Var(Ps)=Var(X/n)=Var(X)/n2 */ public static double calculateVariance(int n,double p){ //计算二项分布B(n,p)的方差[公式:Var(X)=npq] double bVar = n*p*(1-p); //利用总体方差求样本方差:var(Ps)=var(X/n)=var(X)/n double VarPs = bVar/n*n; //并将结果保留3位小数(四舍五入) String VarPs_String = ScoreUtil.getFractionDigits(VarPs, 3); VarPs = Double.valueOf(VarPs_String); System.out.println("比例抽样分布的方差:"+VarPs); return VarPs; } /** * @param args */ public static void run(int n,double p,double x) { NormalDistribution normalDistributioin = new NormalDistribution(0,1); double u = calculateExpectedValue(n,p); double σ2 = calculateVariance(n,p); //normalDistribution(x); double σ = Math.sqrt(σ2); double z = (x-u)/σ; double fx = normalDistributioin.cumulativeProbability(z); //并将结果保留3位小数(四舍五入) String fx_String = ScoreUtil.getFractionDigits(fx,3); fx = Double.valueOf(fx_String); System.out.println("比例抽样分布X的概率:"+fx); } } 4均值的抽样分布
4.1均值抽样分布的定义
如果从一个总体中用相同的方法抽取许多大小相同但存在差异的样本,然后用每个样本的某个属性形成一个分布,所得结果称为抽样分布。由此得出,用每个样本的均值形成的抽样分布就是"均值抽样分布"。均值抽样分布是一种概率分布,由所有大小为n的可能样本的均值构成。如果我们知道这些样本均值的分布,就能用这个分布求出某一个特定样本均值的发生概率。
4.2均值抽样分布符号定义
已知总体的均值和方差,并用和表示,一个包装袋中的糖球数量可以用X表示。随机选择的每一袋糖球都是X的一个独立观察结果,如果用代表随机选择的一袋糖球中的糖球数量,则每个的期望都是u,方差为。我们可以用表示这n袋糖球的容量均值,计算如下: 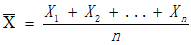
现在我们取出大小为n的所有可能样本,每一个可能样本包含n袋糖球,即每一个样本都包含X的n个独立观察结果。利用所有可能的样本,我们利用从所有可能样本得出的形成一个分布,该分布称作"均值抽样分布",或者称作" 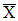 的分布"。
的分布"。
4.3均值抽样分布计算步骤
1 查看与我们的特定样本大小相同的所有样本。
如果我们有样本大小为n,就要考虑所有大小为n可能样本,在本例中,小包装糖球有30袋,因此n为30。
2 观察所有样本形成的分布,然后求出样本均值的期望和方差。
每一样本都各有特点,每个包装袋中的糖球数目有变化。已知总体的均值和方差,并用和表示,一个包装袋中的糖球数量可以用X表示。随机选择的每一袋糖球都是X的一个独立观察结果,如果用代表随机选择的一袋糖球中的糖球数量,则每个的期望都是u,方差为。我们用表示这n袋糖球的容量均值。这里的每一个Xi都是X的一个独立观察值,且我们已知E(X) = u,Var(X)=。 所以 的期望和方差分别如下: E(x) = u 和Var(x) = 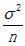
3 得出上述样本均值的分布后,利用该分布求出概率。
只要知道所有可能样本的均值的分布情况,就能利用该分布求出一个随机样本的均值的概率,在本例中,随机样本即小包装糖球。当n很大时,的分布接近正态分布。当X符合正态分布,则符合正态分布;当X不符合正态分布,但是当n>30的时候,仍然符合正态分布。
4.4均值抽样分布使用场景
当数据或事件数量十分庞大时,很难决定从何处着手收集数据,我们就可以有效地、正确地采用抽样收集数据。从一个已知总体中取出某个样本的均值的时候,需要得知样本的期望形态,即可使用均值抽样分布。
4.5均值抽样分布优缺点
4.5.1 均值抽样分布优点
可以使用均值的抽样分布求出从一个已知总体中取出的某个样本的均值的概率,可以由此得知样本的期望形态。
4.5.2.均值抽样分布缺点
通过均值抽样分布得出的样本的期望不一定是非常正确的,也会存在一些误差,或者需要在进行一些验证等。
4.6 均值抽样分布算法的输入数据
* @param s 输入一个数组:样本数据
* @param x 你 所要求均值抽样分布概率的随机变量
4.7比例抽样分布算法的输出结果
输出中间结果
* @return E(mean) 均值抽样分布的期望
* @return Var(mean) 均值抽样分布的方差
输出最终结果
* @return 小于或等于符合正态分布的随机变量X的概率值
4.8均值抽样分布算法异常和误差
4.8.1均值抽样分布算法可能异常或误差
异常:输入数据不合法;当n小于或等于30时,抛出异常,不能使用正态分布计算概率。
误差:保留小数位数造成不精确
4.8.2均值抽样分布算法异常或误差处理
异常:解决,输入不合法给予提示。
误差:解决,进行小数点位数自定义保留封装,根据具体精度进行设置
4.9均值抽样分布算法描述
类的描述
类源码见源程序: predict.vo.MeanSampleDistribution
方法描述
通过对需要计算均值抽样分布的均值和标准差进行计算得出具体标准分再通过调用 org.apache.commons.math3.distribution 类来实现。。
类和方法调用的接口
类源码见源程序: predict.vo.MeanSampleDistribution.java
MeanSampleDistribution.java 下有如下方法:
public static double calculateExpectedValue(double[] s)
// 均值抽样分布的期望
public static double calculateVariance(double[] s)
// 均值抽样分布的方差
cumulativeProbability(double z)
// 需要求符合正态分布的比例抽样分布的标准分。
调用封装类:
predict.utils.ScoreUtil.java 下有如下方法: subZeroAndDot(String s)
package vo; import java.util.ArrayList; import java.util.List; import java.util.Scanner; import org.apache.commons.math3.distribution.NormalDistribution; import utils.ScoreUtil; /** * @(#)MeanSampleDistribution.java * @Comments 均值抽样分布(求期望和方差) * @description * 1.我们抽取总体中的大小为n的所有可能样本,可以标记为S1,S2,,,Sn,然后用这些样本的均值形成一个分布。 * 2.S1=[X1,X2,,,Xn] S2=[X1,X2,,,Xn],,,Sn=[X1,X2,,,Xn] 由于每一个Xi都是X的一个独立观察结果。所以每个Xi * 的期望都是u,方差都是σ^2。 * 3.E(X)=u,var(X)=σ^2, 样本均值mean=(X1+X2+...+Xn)/n * @author gyz * @date 2015-8-15 @since JDK1.8 */ public class MeanSampleDistribution { /** * 计算均值抽样分布的期望 * @param s 输入一个数组:样本数据 * @return 均值抽样分布的期望E(mean)=E((X1+X2+....+Xn)/n)=(E(X1)+E(X2)+...+E(Xn))/n */ public static double calculateExpectedValue(double[] s){ //计算样本均值 int sum=0; for(int i=0;i<s.length;i++){ sum += s[i]; } double mean = sum*1.0/s.length; //求均值抽样分布的期望 double Emean; Emean = mean; //并将结果保留3位小数(四舍五入) String Emean_string = ScoreUtil.getFractionDigits(Emean, 3); Emean = Double.valueOf(Emean_string); System.out.println("均值抽样分布的期望:"+Emean); return Emean; } /** * 计算均值抽样分布的方差 * @param s 输入一个数组:样本数据 * @return 比例抽样分布的方差var(mean)=var((X1+X2+....+Xn)/n)=(var(X1)+var(X2)+...+var(Xn))/n */ public static double calculateVariance(double[] s){ //求均值抽样分布的方差 int sum = 0; int n = s.length; double Varmean=0.0; for(int i=0;i<n;i++){ sum += s[i]; } double mean = sum*1.0/n; for(int i=0;i<n;i++){ Varmean += (s[i] - mean)*(s[i] - mean); } Varmean = Varmean/n; //并将结果保留3位小数(四舍五入) String Varmean_string = ScoreUtil.getFractionDigits(Varmean, 2); Varmean = Double.valueOf(Varmean_string); System.out.println("均值抽样分布的方差:"+Varmean); return Varmean; } /** * @param args * @return */ public static void run(double[] t,double x) { NormalDistribution normalDistributioin = new NormalDistribution(0,1); double u = calculateExpectedValue(t); double σ2 = calculateVariance(t); double σ = Math.sqrt(σ2); double z = (x-u)/σ; double fx = normalDistributioin.cumulativeProbability(z); //并将结果保留3位小数(四舍五入) String fx_String = ScoreUtil.getFractionDigits(fx,3); fx = Double.valueOf(fx_String); System.out.println("均值抽样分布X的概率:"+fx); } } 5 中心极限定理的使用

6 总结与共享
6.1 总结

6.2共享
PPT: http://yunpan.cn/cFkdV5ViBBPcj 访问密码 1db5
开源代码: http://yunpan.cn/cFkdQqGbcwEYp 访问密码 b03a
正文到此结束
热门推荐










相关文章

近期评论
-
你这基本没有更新呀,最近文章显示还是2019年的文章。不符合要求哈
-
关键词:慕云博客 链接:https://www.lilun.me 描述:分享原创文字的个人博客
-
-
-
可以提供一下源码吗
-
不是商业站,鸡娃学习笔记
-
-
-
-
听他们说很厉害的样子
Loading...
![[HBLOG]公众号](http://www.liuhaihua.cn/img/qrcode_gzh.jpg)

