MongoDB数据空洞解决方法
背景
很多时候,我们项目上线时间比较久了,我们积累了一些无用的数据,而由于MongoDB顺序写的原因,在我们删除部分无用数据后,它的storageSize和fileSize并不会变小,这就造成了大量的数据空洞。 这些数据空洞除了占用磁盘之外,也会加载到内存中,这会降低内存效率。 所以这个时候,我们一般要对这些数据空洞进行处理,一般有下面几种处理方式。 一种是使用MongoDB自带的compact命令:- db.collectionName.runCommand(“compact”)
- 先预热从库
- 提升从库为主库,原主库降为从库
- 移除原主库的DB数据,直接remove掉
- 重新同步
- 完成后,预热,然后将此库提升为主库,原从库依然降为从库
- DB级别,不会有碎片,毕竟是新写的,收缩效率高
- 基本不会影响线上服务(当然,你不能只有一个从,你也不能挑服务高负荷的时候来干这个事情)
搭建简易集群
这里搭建的简易集群只有一主一从(这里不包含仲裁节点,只是为了简单),只作实验之用,并不能用于生产环境。-
配置.conf文件 shard11.conf
dbpath = /Users/fujun/data/mongodb/shard11 shardsvr = true replSet = shard1 port = 28017 oplogSize = 2048 logpath = /Users/fujun/data/mongodb/log/shard11.log logappend = true fork = true nojournal = trueshard12.conf
dbpath = /Users/fujun/data/mongodb/shard12 shardsvr = true replSet = shard1 port = 28018 oplogSize = 2048 logpath = /Users/fujun/data/mongodb/log/shard12.log logappend = true fork = true nojournal = true - 启动mongod
如果没有创建相应的文件夹,这里可能出错,注意一下。 成功之后会显示类似于这样的文字:mongod --config shard11.conf mongod --config shard12.confabout to fork child process, waiting until server is ready for connections. forked process: 878 child process started successfully, parent exiting - 初始化副本集
使用mongo连接
输入:tn-30-20130009:data fujun$ mongo --port 28017 MongoDB shell version: 3.0.7 connecting to: 127.0.0.1:28017/test Server has startup warnings: 2015-11-10T09:17:54.230+0800 I CONTROL [initandlisten] 2015-11-10T09:17:54.230+0800 I CONTROL [initandlisten] ** WARNING: soft rlimits too low. Number of files is 256, should be at least 1000cfg = {"_id":"shard1","members":[ {"_id":0, "host":"127.0.0.1:28017"}, {"_id":1, "host":"127.0.0.1:28018"}]};
- 手动降权
这里没有仲裁节点,我们需要手动降权。我们将shard11降为从节点:
显示已经从Other变为从节点rs.stepDown() 查看副本集状态
查看副本集状态

插入数据
这里我们使用脚本插入2000w条数据(连接primary节点插入)。mongo_insert.py
#!/usr/bin/python import random from pymongo import MongoClient client = MongoClient('localhost', 28018) test = client.test students = test.students students_count = students.count() print "student count is ", students_count for i in xrange(0,5000000): classid = random.randint(1,4) age = random.randint(10, 30) student = {"classid":classid, "age":age, "name":"fujun"} students.insert_one(student) print i students_count = students.count() print "student count is ", students_count python ~/Desktop/mongo_insert.py 查看数据
每秒插入为4k-6k条(副本集在单台机器上,也就是说本地是有两份写的,可见如果只是单写,插入速度会更快)。 OK,2000w条数据插入成功!
OK,2000w条数据插入成功!
 storageSize和fileSize:
storageSize和fileSize:
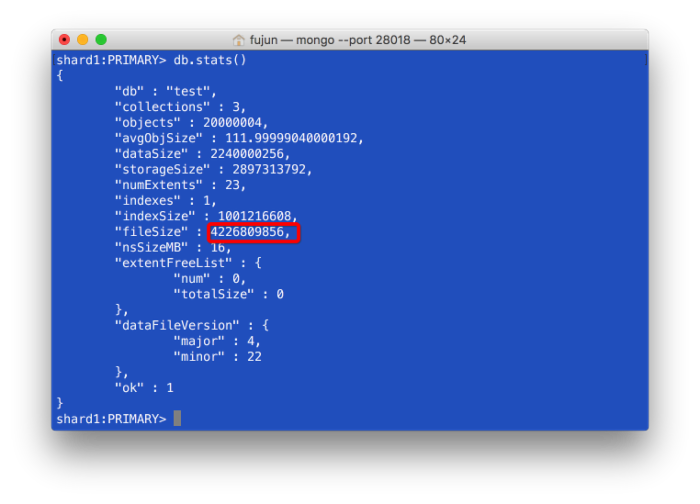 storageSize是dataSize+删除的文档的总大小(文档删除后,storageSize并不会变小)。
fileSize是文件空间的占用、索引等所有内容的总和。所以它会比storageSize大。
现在的fileSize由于Mongodb避免碎片,采用预分配机制,大小比较规律,类似于这样:
storageSize是dataSize+删除的文档的总大小(文档删除后,storageSize并不会变小)。
fileSize是文件空间的占用、索引等所有内容的总和。所以它会比storageSize大。
现在的fileSize由于Mongodb避免碎片,采用预分配机制,大小比较规律,类似于这样:
 我们可以看到,基本上是在翻倍。
我们可以看到,基本上是在翻倍。
生成空洞数据
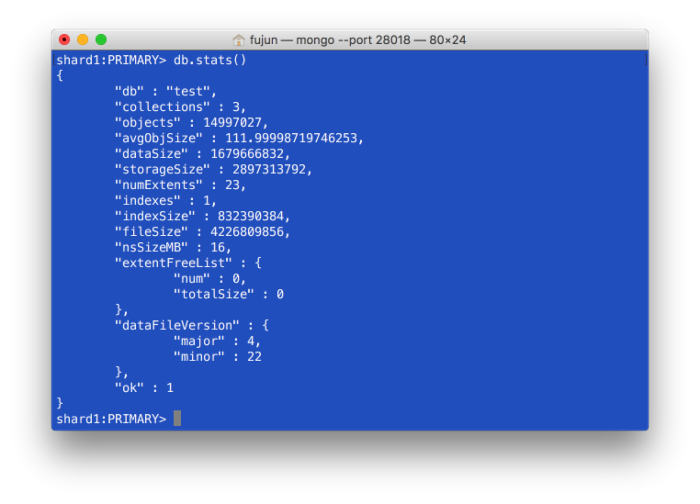
删除所有classid<4的数据。db.students.remove({"classid":{"$lt":4}}) 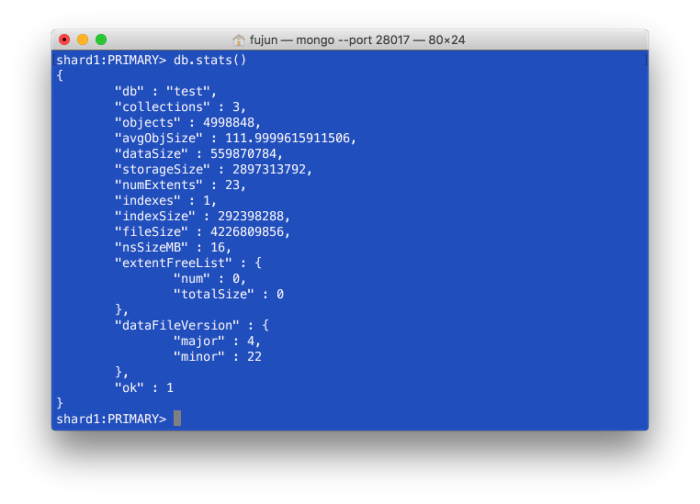 再次查看storageSize和fileSize,没有变化:
再次查看storageSize和fileSize,没有变化:
降权、停止
原shard12降为从节点,原shard11升为主节点。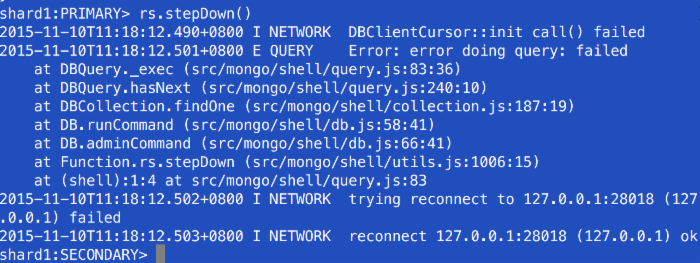
 停止shard12
停止shard12
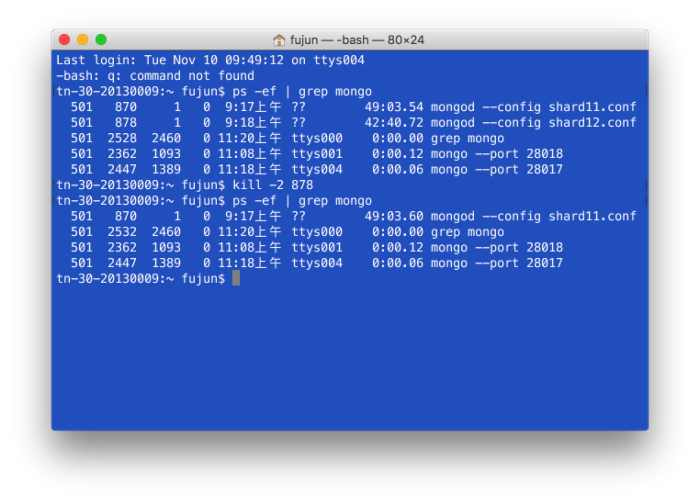
删除数据
rm -rf ~/data/mongodb/shard12/* 

同步数据
重启shard11,查看log。

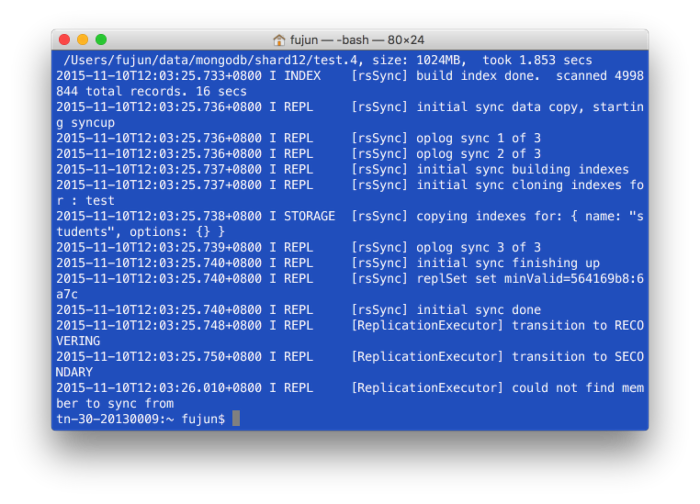 由于数据变的很少,mongodb并没有创建test.5,也就是那个2GB的文件。
由于数据变的很少,mongodb并没有创建test.5,也就是那个2GB的文件。

再次查看storageSize和fileSize
我们发现,不管是storageSize还是fileSize都下降非常明显。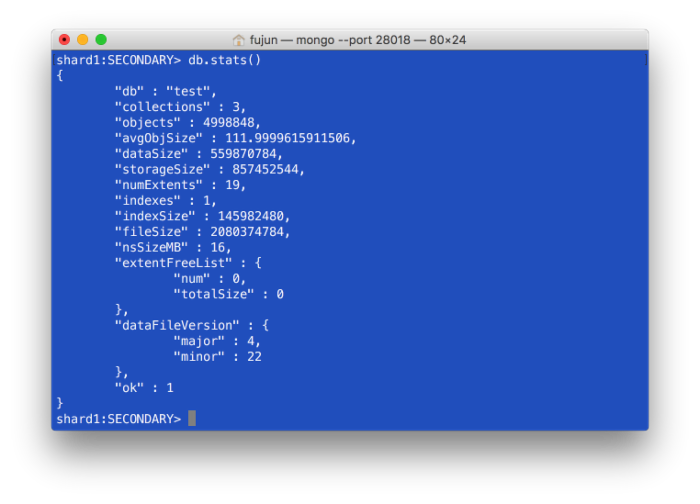
升权
将shard12升为主库,shard12降为从库,这里和上面类似,不再重复。原文链接:http://ifujun.com/mongodbshu-ju-kong-dong-jie-jue-fang-fa/
正文到此结束
热门推荐










相关文章

近期评论
-
你这基本没有更新呀,最近文章显示还是2019年的文章。不符合要求哈
-
关键词:慕云博客 链接:https://www.lilun.me 描述:分享原创文字的个人博客
-
-
-
可以提供一下源码吗
-
不是商业站,鸡娃学习笔记
-
-
-
-
听他们说很厉害的样子
Loading...
![[HBLOG]公众号](http://www.liuhaihua.cn/img/qrcode_gzh.jpg)

