python3.4爬虫抓取豆瓣热门250本书

一只尼玛
认输,你就输了。写前端好渣啊,没事,多好玩。
个人主页: www.lenggirl.com
项目在此下载: java maven配置的spring mvc和hibernate
瞬间变成前端高手,哈哈哈哈,
Do you know that computer changed our life.
All the things in the world can become a automachine
Which is equel to a algorithm.
Follows our thought and step by step.
Then you don't know the bottom of the truth.
So Gods bless you not lose yourselt.
Just the world have never own such a strange object.
- 博客园
- 首页
- 新随笔
- 联系
- 订阅
- 管理
随笔- 23 文章- 2 评论- 13
python3.4爬虫抓取豆瓣热门250本书
因为找到一份数据挖掘的实习,所以学了一个星期的爬虫,当然先是复习了Python,换到P3
此爬虫是用3.4版本的python,其实,可以抓到更多的书,比如小说可以抓到1000本,链接只有改为:
http://www.douban.com/tag/%E5%B0%8F%E8%AF%B4/book?start=10000
然后重新改下匹配方法。。。。。然后可以再深层次地爬每本书的具体信息,和评论,但是此文
并没有爬具体的图书信息。
还可以抓电影,音乐。。。。
先新建一个project,也就是一个文件夹pythoncode,然后在里面建一个文件夹scrapy,所有代码都在scrapy里面,因为有包依赖.
目录如下图:
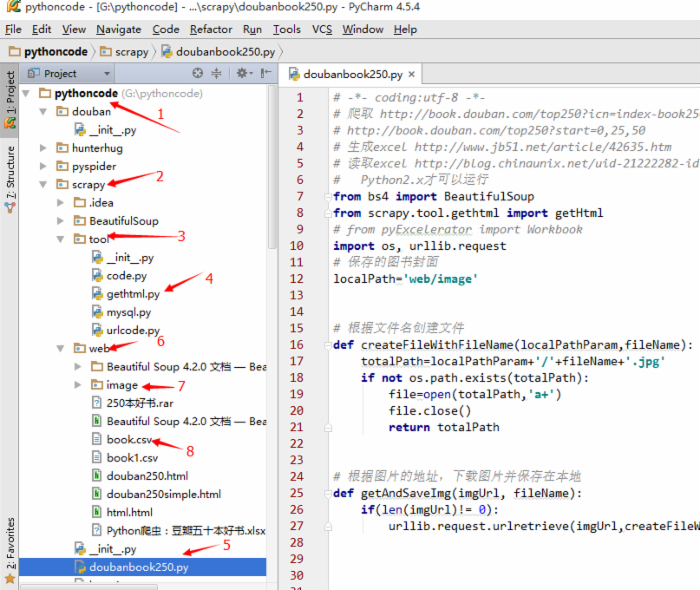
有些库需要自己安装,比如BeautifulSoup等,安装使用这个命令
pip3 install BeautifulSoup
主代码如下:
doubanbook250.py
# -*- coding:utf-8 -*- # 爬取 http://book.douban.com/top250?icn=index-book250-all # http://book.douban.com/top250?start=0,25,50 # 生成excel http://www.jb51.net/article/42635.htm # 读取excel http://blog.chinaunix.net/uid-21222282-id-3420444.html # Python2.x才可以运行 from bs4 import BeautifulSoup from scrapy.tool.gethtml import getHtml # from pyExcelerator import Workbook import os, urllib.request # 保存的图书封面 localPath='web/image' # 根据文件名创建文件 def createFileWithFileName(localPathParam,fileName): totalPath=localPathParam+'/'+fileName+'.jpg' if not os.path.exists(totalPath): file=open(totalPath,'a+') file.close() return totalPath # 根据图片的地址,下载图片并保存在本地 def getAndSaveImg(imgUrl, fileName): if(len(imgUrl)!= 0): urllib.request.urlretrieve(imgUrl,createFileWithFileName(localPath,fileName)) def book(url_content): """ 输入网页内容进行图书爬取 返回图书信息元组 """ books = [] soup = BeautifulSoup(url_content, 'html.parser') # 开始解析 # booktable = soup.select('div.indent table div a') booktable1 = soup.find_all("table", attrs={"width": "100%"}) # 找到所有图书所在标记 # 循环遍历图书列表 for book in booktable1: simplebook = book # print(simplebook) subsoup = BeautifulSoup(str(simplebook), 'html.parser') # 单本书进行解析 # print(subsoup) # 图书封面: # http://img4.doubanio.com/spic/s1237549.jpg # http://img4.doubanio.com/lpic/s1237549.jpg booksmallimg = subsoup.img['src'] imgtemp = booksmallimg.split('/') imgtemp[len(imgtemp)-2] = 'lpic' booklargeimg = '/'.join(imgtemp) # print(booksmallimg) # print(booklargeimg) # 图书信息 # print(subsoup.div) # print(subsoup.div.a) booklink = subsoup.div.a['href'] # 图书链接:http://book.douban.com/subject/1084336/ bookname1 = subsoup.div.a['title'] # 图书名称:小王子 # 下载图片 getAndSaveImg(booklargeimg, bookname1) bookname2t = subsoup.div.span if bookname2t: bookname2 = bookname2t.string else: bookname2 = '' # 图书别称:Le Petit Prince bookinfo = subsoup.p.string # 图书出版信息:[法] 圣埃克苏佩里 / 马振聘 / 人民文学出版社 / 2003-8 / 22.00元 bookstar = subsoup.find('span',attrs={"class": "rating_nums"}).string # 图书星级:9.0 bookcommentnum = subsoup.find('span',attrs={"class": "pl"}).string.strip('/r/n ()人评价') # 评价人数:190325 books.append((bookname1, bookname2, booklink, booklargeimg, bookinfo, bookstar, bookcommentnum)) # 返回图书列表 return books # 本地测试所用 # booklist = book(open("web/douban250.html",'rb').read()) # print(booklist) # 爬取得网页 urllist = [] # 要爬取的网页 url = 'http://book.douban.com/top250?start=' # 基础网址 page = 10 # 总共爬10页 pagesize = 25 # 每页25本 for i in range(page): urllist.append(url+str(i*pagesize)) # print(urllist) # 一张张爬取所有图书列表 bookslist = [] for url in urllist: html_doc = getHtml(url) bookslist.append(book(html_doc)) # # 存入Exexl # w = Workbook() #创建一个工作簿 # ws = w.add_sheet('图书') #创建一个工作表 # ws.write(0,0,'最热图书250本') # ws.write(1,0,'序号') # ws.write(1,1,'图书名称') # ws.write(1,2,'图书别称') # ws.write(1,3,'图书链接') # ws.write(1,4,'图书封面') # ws.write(1,5,'图书出版信息') # ws.write(1,6,'图书星数') # ws.write(1,7,'图书评论数') # # i = 2 # for page in bookslist: # for book in page: # ws.write(i,0,i-1) # ws.write(i,1,book[0]) # ws.write(i,2,book[1]) # ws.write(i,3,book[2]) # ws.write(i,4,book[3]) # ws.write(i,5,book[4]) # ws.write(i,6,book[5]) # ws.write(i,7,book[6]) # # w.save('web/book.xls') #保存 # print(bookslist) # print(len(bookslist)) # 编码问题 :http://blog.csdn.net/greatpresident/article/details/8209712 fout = open('web/book.csv', 'w',encoding='utf-8') # 必须加上编码,写入到文件 title = ['图书名称','图书别称', '图书链接', '图书封面', '图书出版信息', '图书星数', '图书评论数'] html = ','.join(title)+ '/n' for page in bookslist: for book in page: html += ','.join(book) + '/n' # print(html) fout.write(html) fout.close() # 生成的csv默认为ASCII编码,用记事本打开另存为ASCII编码,然后打开再转Excel等 其中有一个函数被封装在工具箱中,在scrapy夹中建立一个tool文件夹
代码如下:
gethtml.py
# -*- coding:utf-8 -*- import urllib.request import urllib.parse import urllib.request, urllib.parse, http.cookiejar from bs4 import BeautifulSoup __author__ = 'hunterhug' def getHtml(url): """ 伪装头部并得到网页内容 """ cj = http.cookiejar.CookieJar() opener = urllib.request.build_opener(urllib.request.HTTPCookieProcessor(cj)) opener.addheaders = [('User-Agent', 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/41.0.2272.101 Safari/537.36'), ('Cookie', '4564564564564564565646540')] urllib.request.install_opener(opener) html_bytes = urllib.request.urlopen(url).read() html_string = html_bytes.decode('utf-8') return html_string def getSoup(html_content,parse='html.parser'): """ 得到网页解析后的对象,方便分拆数据 """ return BeautifulSoup(html_content,parse) 当然没事做还实现了抓图书的封面,然后写入存入excel。
因为有些库只支持python 2.x的,所以直接写入文件,然而写入文本的时候可能会有问题,所以需要想想办法知道是什么问题。
有些网页的编码可能是gbk,可能是utf-8,也可能里面夹杂一些乱七八糟的半角,全角,日文什么的。
我爬的这些图书有个很好的特征,如
http://book.douban.com/top250?start=0 这个网页的html代码
主要的图书html为以下:
<div class="indent"> <p class="ulfirst"></p> <table width="100%"> <tr class="item"> <td width="100" valign="top"> <a class="nbg" href="http://book.douban.com/subject/1084336/" onclick="moreurl(this,{i:'0'})"> <img src="http://img4.doubanio.com/spic/s1237549.jpg" width="64" /> </a> </td> <td valign="top"> <div class="pl2"> <a href="http://book.douban.com/subject/1084336/" onclick="moreurl(this,{i:'0'})" title="小王子"> 小王子 </a> <br/> <span style="font-size:12px;">Le Petit Prince</span> </div> <p class="pl">[法] 圣埃克苏佩里 / 马振聘 / 人民文学出版社 / 2003-8 / 22.00元</p> <div class="star clearfix"> <span class="allstar45"></span> <span class="rating_nums">9.0</span> <span class="pl">( 190325人评价 )</span> </div> </td> </tr> </table> 最后爬到的结果如下:

封面在此

总结:
1.先使用Python urllib进行浏览器伪装访问url,得到网页内容
2.使用一些解析库对网页进行解析,也可以用正则re模块
3.保存起来,如保存进数据库或写入文本。
如解析库BeautifulSoup 可参考 http://www.crummy.com/software/BeautifulSoup/bs4/doc.zh/
下面是我集合的代码
# -*- coding:utf-8 -*- # pip3 install html5lib # pip3 install lxml # http://www.w3school.com.cn/css/css_selector_type.asp __author__ = 'hunterhug' from bs4 import BeautifulSoup soup = BeautifulSoup("<html class='c c1' id='id'>" "<head><title>The Dormouse's story</title><meta charset='utf-8' /></head>" "<p>sdd</p><p>dd/n</p>" "/n" "</html>", "html.parser") print(type(soup)) # <class 'bs4.BeautifulSoup'> tag=soup.html print(tag) # 得到标记的内容 print(tag.name) # 标记名称 print(tag.attrs) # 标记内所有属性值 print(tag['class']) # 标记内某个属性值 # print(tag.get('class')) print(tag.string) # 标记内有标记则里面字符串没有 tag1=soup.p print(type(tag1)) # <class 'bs4.element.Tag'> print(tag1) # 只能得到第一个标记 print(type(tag1.string)) # <class 'bs4.element.NavigableString'> print('-'*50) print(tag1.string) # 得到标记内字符串 print('-'*50) # xml_soup = BeautifulSoup('<p class="body strikeout"></p>', 'xml') # print(xml_soup.p['class']) xml_soup1 = BeautifulSoup('<p class="body strikeout"></p>', 'html.parser') print(xml_soup1.p['class']) markup = "<b>都是<!--Hey, buddy. Want to buy a used parser?-->都是<!--Hey, buddy. Want to buy a used parser?--></b>" marksoup = BeautifulSoup(markup,'html.parser') comment = marksoup.b.string print(type(comment)) # <class 'bs4.element.Comment'> print(comment) # 打印注释内容,多个注释则内容为空 print(marksoup.b) # 打印整个标记,下面一个标记空一行 print(marksoup.b.prettify()) # 找所有元素 alla = soup.find_all('p') print(alla) nodes = soup.contents print(nodes) print(nodes[0].name) nodess=soup.html.contents print(nodess) print(len(nodess)) # 子节点循环 for child in soup.html.children: print(child) # 向左深度递归 for child in soup.html.descendants: print(child) print('-'*50) for string in soup.strings: print(repr(string)) print('-'*50) # 得到父节点 title_tag = soup.title print(title_tag.parent) print(title_tag.parent.name) # 递归父节点 for parent in title_tag.parents: if parent is None: print(parent,'none') else: print(parent.name) print('-'*50) print(soup.prettify()) print('-'*50) # 兄弟节点 str = """<p class="story">Once upon a time there were three little sisters; and their names were <a href="http://example.com/elsie" class="sister" id="link1">Elsie</a>, <a href="http://example.com/lacie" class="sister" id="link2">Lacie</a> and <a href="http://example.com/tillie" class="sister" id="link3">Tillie</a>; and they lived at the bottom of a well.</p>""" brother = BeautifulSoup(str, 'html.parser') link = brother.a print(link) print('-'*50) print(repr(link.next_sibling)) print('-'*50) print(link.next_sibling) # str()出来的值是给人看的。。。repr()出来的值是给python看的 print(link.next_sibling.next_sibling) print(link.next_sibling.next_sibling.previous_sibling.previous_sibling) print('-'*50) for sibling in link.next_siblings: print(repr(sibling)) print('-'*50) for sibling in brother.find(id="link3").previous_siblings: print(repr(sibling)) 下面是我参考别人封装的Mysql函数,然后改了一下,本文并没有用,但是抓的数据最好存入数据库
mysql.py
需要pip3 install pymysql
# -*- coding:utf-8 -*- import pymysql class Mysql: """ 对pymysql的简单封装,实现基本的连接 """ def __init__(self, host, user, pwd, db): self.host = host self.user = user self.pwd = pwd self.db = db def __GetConnect(self): """ 得到连接信息 返回: conn.cursor() """ if not self.db: raise (NameError, "没有设置数据库信息") self.conn = pymysql.connect(host=self.host, user=self.user, passwd=self.pwd, db=self.db, charset="utf8") cur = self.conn.cursor() if not cur: raise (NameError, "连接数据库失败") else: return cur def ExecQuery(self, sql): """ 执行查询语句 返回的是一个包含tuple的list,list的元素是记录行,tuple的元素是每行记录的字段 调用示例: ms = MYSQL(host="localhost",user="sa",pwd="123456",db="PythonWeiboStatistics") resList = ms.ExecQuery("SELECT id,NickName FROM WeiBoUser") for (id,NickName) in resList: print str(id),NickName """ cur = self.__GetConnect() cur.execute(sql) resList = cur.fetchall() # 查询完毕后必须关闭连接 self.conn.close() return resList def ExecNonQuery(self, sql): """ 执行非查询语句 返回的是执行成功返回1,否则0 调用示例: cur = self.__GetConnect() cur.execute(sql) self.conn.commit() self.conn.close() """ cur = self.__GetConnect() try: cur.execute(sql) self.conn.commit() return 1 except Exception: # 出现异常回滚 self.conn.rollback() return 0 finally: self.conn.close() def main(): mysql = Mysql(host="localhost", user="root", pwd="lenggirl", db="lenggirl") resList = mysql.ExecQuery("SELECT * FROM think_user") for inst in resList: print(inst) if __name__ == '__main__': main() #print(dir(Mysql)) 学会了这个,什么都可以爬。
当然,也可以使用scrapy这种包好的库,但原理一样,不过对于爬几百万数据什么的,要考虑线程池什么的,别人包好的当然更好用。
下面是我电脑存的一些开发用的工具等等
下载
posted @ 2015-11-23 20:01 一只尼玛 阅读( ... ) 评论( ... ) 编辑 收藏
刷新评论刷新页面返回顶部
博客园首页 博问 新闻 闪存 程序员招聘 知识库
Copyright ©2015 一只尼玛
我是一个喜欢学知识的人,只是因为学了计算机,发现很多东西要学。
我用了一个星期,也可以说是五天,做出了至今为止第一个完整的博客。 OOXX
我会很多计算机语言,C,C++,Python,PHP,JAVA,HTML,CSS,JS,MATLAB。
可是并没有卵用,并没有改变人类,呵呵。
我之前学了一学期数学,我知道数学家,计算机科学家和哲学家
从无到有创造东西真的很奇妙
比如不知从哪里学会了写网站,然后莫名奇妙的
晚上会突然做梦梦到学到很厉害的技术
可是却很害怕,因为摸不到
代码这种东西说来不复杂
只是顺从人的逻辑,提取数据再插入数据
自从得了精神病精神好多了
正文到此结束
- 本文标签: CTO XML build 招聘 java node 数据库 IDE Apple Select example 文章 spring windows find 数据 注释 parse 总结 数据挖掘 目录 tab tar UI 代码 遍历 final python mysql unix 配置 HTML5 解析 开发 博客 测试 js 安装 SDN HTML Chrome http root ip sql 管理 程序员 list src PHP maven 网站 App Excel lib 下载 web db 线程 CSS
- 版权声明: 本文为互联网转载文章,出处已在文章中说明(部分除外)。如果侵权,请联系本站长删除,谢谢。
- 本文海报: 生成海报一 生成海报二
热门推荐










相关文章

近期评论
-
你这基本没有更新呀,最近文章显示还是2019年的文章。不符合要求哈
-
关键词:慕云博客 链接:https://www.lilun.me 描述:分享原创文字的个人博客
-
-
-
可以提供一下源码吗
-
不是商业站,鸡娃学习笔记
-
-
-
-
听他们说很厉害的样子
Loading...
![[HBLOG]公众号](http://www.liuhaihua.cn/img/qrcode_gzh.jpg)

