如何使用HBase构建NewSQL?
本文是刘奇在SDCC 2015数据库实践论坛上分享的《HBase分布式事务与SQL实现》主题内容。
目前主流的数据库或者NoSQL要么在CAP里面选择AP,比较典型的例子是Cassandra,要么选择CP比如HBase,这两个是目前用得非常多的NoSQL的实现。我们的价值观一定认为未来是分布式的,一定是尽量倾向于全部都拥有,大部分情况下取舍都是HA,主流的比较顶级的数据库都会选择C,分布式系统一定逃不过P,所以A就只能选择HA。现在主要领域是数据库的开发,完全分布式,主要方向和谷歌的F1方向非常类似。
目前看NewSQL代表未来(Google Spanner、F1、FoundationDB),HBase在国内有六个Committer,在目前主流的开源数据库里面几乎是最强的阵容。大家选型的时候会有一个犹豫,到底应该选择HBase还是选Cassandra。根据应用场景,如果需要一致性,HBase一定是你最好的选择,我推荐HBase。它始终保持强一致,我们非常喜欢一致性,丧失一致性的时候有些错误会特别诡异,很难查。对于Push-down特性的设计其实比较好,全局上是一个巨大的分布式数据库,但是逻辑上是分成了一个个Region,Region在哪台机器上是明确的。
比如要统计记录的条数,假设数据分布在整个系统里面,对数十亿记录做一个求和操作,就是说不同的机器上都要做一个sum,把条件告诉他要完成哪些任务,他给你任务你再汇总,这是典型的分布式的 MPP,做加速的时候是非常有效的。
2015年HBaseConf 上面有一句总结: “Nothing is hotter than SQL-on-Hadoop, and now SQL-on- HBase is fast approaching equal hotness status”, 实际上SQL-on-HBase 也是非常火。因为 Schema Less 没有约束其实是很吓人的一件事情,当然没有约束也比较爽,就是后期维护十分痛苦,规模进一步扩大了之后又需要迁移到 SQL。
现在无论从品质还是速度上要求已经越来越高,拥有SQL的同时还希望有ACID的东西(OLAP一般不追求一致性)。所以TiDB在设计时就强调这样的特点:始终保持分布式事务的支持,兼容MySQL协议。无数公司在SQL遇到Scale问题的时候很痛苦地做出了选择,比如迁移到HBase,Cassandra MongoDB已经看过太多的公司做这种无比痛苦的事情,现在不用痛苦了,直接迁过来,直接把数据导进来就OK了。TiDB最重要的是关注OLTP,对于互联网业务来说通常是在毫秒级内就需要返回一个结果。
我们到目前为止开发了六个月,开源了两个月。昨天晚上TiDB达到了第一个Alpha的阶段,现在可以拥有一个强大的数据库:支持分布式事务,始终保持同步的复制,强大的按需Scale能力,无阻塞的Schema变更。发布第一个Alpha版本的时候以前的质疑都会淡定下来,因为你可以阅读每一行代码,体验每个功能。选择这个领域也是非常艰难的决定,实在太Hardcore了,当初Google Spanner也做了5年。不过我们是真爱,我们就是技术狂,就是要解决问题,就是要挑大家最头痛的问题去解决。好在目前阿里的OceanBase给我们服了颗定心丸,大家也不会质疑分布式关系型数据库是否可行。
TiDB名字由来
为什么叫TiDB?大家起名字的时候特别喜欢用希腊神话里面的人物,但几乎所有的希腊神话人物的名字都被别的项目使用了,后来我们就找了化学元素周期表(理工科男与生俱来的特征),化学元素周期表里找到一个不俗且又能代表我们数据库特性的元素-Ti 。Ti是航空航天及航海里面很重要的设备都会用到的,特别稳定,也比较贵。

TiDB的系统架构图
TiDB怎么支持MySQL这个协议?这里会有一个协议解析层,它的作用就是去分析MySQL协议,转成内部可以识别的分发给自己的SQL Layer。当SQL Layer 拿到这个语句之后会把它拆成对应的分布式KV操作,所以这里会有一个Transactional KV Storage。接下来是在KV基础上增加事务的支持,再往上是普通的KV操作,理论上KV选什么都可以,如果选的是HBase有一个好处,它本身就是分布式,省掉分布式的工作。目前我们在小米的Themis基础上做了些优化和改进,和我们TiDB做了一个很好的结合。后期我们有一个计划,准备自己重写一套底层的分布式KV,把HBase换掉。因为HBase对于Container不友好,加上GC也是让人比较讨厌的问题,压力比较大的时候GC延迟会加长。
Google Percolator实现方式
HBase上面分布式事务典型的设计,先来说一下Goolge Percolator 内部实现,看架构图:

Goolge Percolator内部实现
分布式事务基本设计是在上面这个 Percolator层,Timestamp Oracle 可以保证严格的递增。Percolator是在KV上的实现,它对于SQL的角度考虑比较少,有一个隔离级别的问题,很典型的是Snapshot Isolation, SQL 语句落在KV上的实现,如果只有Snapshot Isolation的话隔离级别就太低了。此外,这个模型还有其它的问题。比如,它每秒能分配多少个递增的Timestamp?Google分享的一个slides的数据,每秒200万,小米也开源了自己的实现,每秒60万,我们前一阵也写了一个每秒400万,优化一下可以达到800万。因为Timestamp业务特别简单,所以可以做针对性的优化,当然很少有业务能跑到这个级别的事务。
Yahoo OMID的实现
雅虎的OMID实现,架构图如下:

雅虎的OMID实现
除了Timestamp的职能,TSO还维护更多信息用于检测事务冲突。TSO是整个Omid系统的单点,如果一个系统只需要一个单点,单点做得越少就能获得越多的性能,也更容易优化。
下图是它的分布式事务的执行过程:
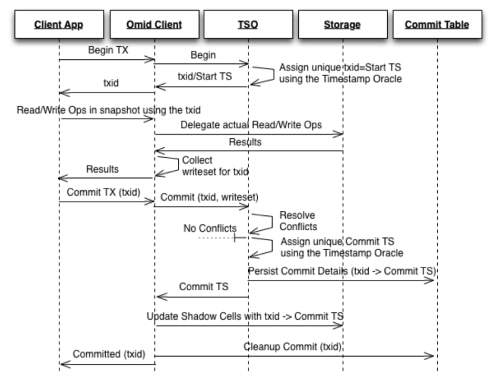
假设现在要发起一个分布式事务,第一个事情是拿Start TS,再去做你的读写操作,做读写操作的时候会把Key都记下来。Commit的时候要先冲突检测,这就是TSO 要做的更多的事情,更具体的细节请参考Omid 的论文或者 <<从零开始写分布式数据库>> 一书。
谷歌的Spanner,细节非常多,引用的论文有40多篇,很吓人,有些引用的论文也非常经典,很值得一读。Spanner已经不再使用NTP了,需要用一个有信心的靠谱的方式来同步时间。内部也说不再用NTP做时间的维护,GPS是非常简单便宜的方式,GPS是大家使用滴滴打车时用于得到定位信息的。GPS还给了当前精确的时钟信息,有软件可以把这个检测出来,可以直接使用它的这个信号来同步时间。使用GPS信号的好处很明显,随便在哪个山区都有GPS信号,但不一定能收到基站的信号,同时它的精度也非常高。
TiDB的技术选型
再来说说TiDB的一些技术选型的例子。选择MySQL协议后会做一些取舍,有些地方不完全按Google F1去做设计的。Google F1里做的比较好的是非常经典的Non-blocking schema changes。比如现在要加一个索引,如果横跨数十台机器,数十亿条记录,加索引的速度是非常慢的,那么这个过程必须是不阻塞的,不影响正在运行的业务的。因为在建立索引的同时需要修改别的地方,所以要做一个原子的提交,细节上还要处理事务冲突的错误。F1有并发的图,我们刚才提到HBase里通过Push-down可以把一些计算下推到对应的节点上去。但由于F1依赖Spanner,而Spanner会频繁地做Reblancing,会把数据不断的移动,所以它在上面很难基于range信息一次做最优的决策。
SQL如何映射分布式KV?
SQL到底是怎么映射到分布式KV上?现在HBase分层分得更加清楚,SQL层不太关心下面到底用什么,在乎的是接口。映射的过程,假设User Table里面有个Email,我们存储的时候是用ID做它的标识,这有很多的好处,比如删掉再重新添加一样的,它要生成不同的ID。在数十亿条记录的情况下删除一个Table,删除的过程完全可以由Map-Reduce异步去做。
为什么提供MySQL协议的支持?如果重新写一个数据库会遇到一个很大的问题,大家凭什么相信你是对的,数据库需要时间需要测试,好在你接入MySQL协议,你可以经过和MySQL一样严谨的测试。但如果是自己完全写一个,不借用它的协议,不借用它的语法,没有测试,大家凭什么相信你是对的。现在这个时代没有Communit是很可怕的,闭门造车很容易走偏。TiDB现在可以让用户一行代码都不改,跑WordPress等,还支持很多的ORM,这些ORM可以直接用,用户的代码一行不改可以直接迁过来,完全拥有水平扩展的能力,完全拥有分布式事务的支持。前TiDB在 Github 上2800+star。

个人简介:
刘奇,开源分布式数据库TiDB创始人,Codis项目创始人,分布式系统专家。曾任豌豆荚,京东资深系统架构师。同时也是知名的Go语言专家和Redis专家。现从事开源的分布式NewSQL数据库TiDB(受Google F1启发)的开发。擅长高并发、大规模、分布式数据库系统架构设计, 微博( @goroutine ) 。
正文到此结束
- 本文标签: mysql sql redis App 小米 src wordpress git HBase Codis 创始人 软件 schema 2015 mail 京东 数据 时间 谷歌 同步 Word db 互联网 UI 代码 key 微博 删除 tab 压力 系统架构 GitHub 分布式事务 开源 http Hadoop 数据库 Region Google 解析 总结 统计 测试 Oracle map NSA MongoDB 开发 core 协议 tar NOSQL IDE Cassandra 滴滴
- 版权声明: 本文为互联网转载文章,出处已在文章中说明(部分除外)。如果侵权,请联系本站长删除,谢谢。
- 本文海报: 生成海报一 生成海报二
热门推荐










相关文章

近期评论
-
Your article is a perfect article without a hitch. Thank you. My site: horse racing betting game
-
-
你这基本没有更新呀,最近文章显示还是2019年的文章。不符合要求哈
-
关键词:慕云博客 链接:https://www.lilun.me 描述:分享原创文字的个人博客
-
-
-
可以提供一下源码吗
-
不是商业站,鸡娃学习笔记
-
-
Loading...
![[HBLOG]公众号](http://www.liuhaihua.cn/img/qrcode_gzh.jpg)

