Spotify的监测框架(上)
【编者的话】 Spotify 是全球最大的正版流媒体音乐服务平台。Spotify提供的服务需要一个巨大的基础设施平台作为支撑,而监测这个平台的运行显得至关重要。Spotify实验室的 John-John Tedro 近日对Spotify的监测进行了一个简单的介绍。作为该系列文章两个部分的 第一篇 ,本文主要介绍了Spotify的监控的历史,当前面临的挑战,以及Spotify又是如何解决这些挑战的。

Spotify的运行监测一开始是作为两个系统的组合,即Zabbix和sitemon,其中sitemon是一个 支持RRD 的土生土长的图形系统,它采用 Munin 用来进行数据收集。 Zabbix的所有权属于我们的SRE团队,而sitemon由我们的后端基础架构团队负责运行。当时,我们的团队很小,身边的很多问题常常都是由自己亲手解决。我们采取了这种方案的原因更多的是因为我们选择这个问题。
从2013年年底起,我们开始把更多的注意力放在 自助服务和分布式运行监测 上。我们想停止监测单个主机,并开始将服务作为一个整体考虑。Zabbix并不适合,因为它主要关注单个主机。唯一可以操作它的是SRE团队的成员。随着整个基础设施变得越来越庞大,我们的系统在强大的负载压力下开始产生裂痕。
我们也在试图尽力将目前的工作做一些改进:基于内存的sitemon方案仅仅能在当前负载压力下保存大约1个月的指标数据,从而我们的首席架构师提出了一种新的替代方案。在这种方案下,虽然我们还有一些喘息的空间,但我们估计我们最多只能持续一年。出于这样的体验,Spotify组建了一个新的团队:Hero。他们的目标是改进Spotify的监测,并为未来做好准备。不惜一切代价。下面是他们采取的主要做法。
报警作为一种服务
报警是我们需要攻克的第一个问题。
我们考虑进一步发展Zabbix。它使用 触发器表达式 来检查报警条件。我们在系统中观测到大量位衰减,许多正在运行的触发器很难理解、已经损坏或无效。这就引出了我们为下一代警报系统所提出的其中一个要求:它必须使得对触发器的测试变得简单,以使其容易理解。Zabbix的可扩展性也是一个问题。在接下来两年中,我们不相信我们的系统可以在我们预期的规模上运行。
在参加 Monitorama EU 时,我们偶然发现了 Riemann 。一个分布式监测系统解决方案。Riemann并没有提供不确定情况下的可扩展性,但对于无状态规则的偏爱很容易地让它可以对负载进行划分和分配。我们为一个服务中的每个主机配对至少两个实例,这些实例运行了相同的规则集。
我们在Riemann之上建立了一个库,称为 Lyceum 。这使我们能够建立一个git仓库,仓库内部,每一个方格可以将它们的规则放入一个隔离的命名空间中。使用这个配置,我们的工程师可以定义可重复的集成测试。它使得任何人可以打开repo,并可以在产品中直接部署这些变更。我们的立场发生了改变,如果测试通过,我们便知道它的工作原理。这被证明是非常成功的。Clojure是一门远远比触发器表达式更易于理解的语言,基于git的审查过程更适合我们的开发方法。
制图
在这个方面,我们折腾了好几次。我们初始的堆栈是基于Munin的,其中的插件对应着收集到的所有东西。一些指标是标准的,但最重要的那些是服务指标。
切换到基于push的方式来降低我们选用工程师的门槛,是值得期待的。使用Munin的经历告诉我们,复杂的定义指标的过程会延缓最后指标的采纳。基于Pull的方法需要配置读出什么,以及从哪里读出。而用Push的方法,你会忘记在最近的API中的样本,最好使用一个共同的协议。考虑一个短暂的任务,其中可能没有足够的时间被收集器发现。但对于Push来说,这并不是问题,因为是任务本身控制了度量的发送。
如果您想了解更多, sFlow 和 Alan Giles 针对这个问题进行了更深入的分析。
我们最初的实验中,部署了一个基于 collected 和 Graphite 的通用解决方案来积累经验。分析性能测试的结果,我们感觉对这种垂直的可扩展性并不满意,我们不想只有一个Graphite节点。
whisper 写入模式涉及到 跨众多文件的随机搜寻和写入 。文件搜索过程中的向下采样,存在一个很高的成本。
分片和再平衡Graphite存在的困难也经常让人望而却步。其中的一些可能最近通过使用后端支持的Cyanite已经得到了解决。但对我们来说,Graphite仍然遭受了一个重大的理论障碍:分层命名。
数据层次
Graphite中一个典型的时间序列按照类似下面这种方式命名:
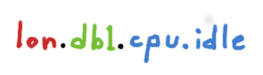
确切的形式分情况不同,但是这可以被视为一个固定的层次结构。在一些情况下这种方式工作得很好,因为它们本质上就是层次结构。但是,如果我们想在一个特定的网站选择所有服务器。我们有两个选择:我们希望服务器名称在不同的基础架构中保持一致,并执行通配符匹配;或者为了解决这个问题,我们可以对命名层次结构进行重新洗牌:
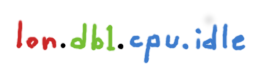
这种类型的重构是很难的。
没有正确的答案。一个团队可能要求将网站作为筛选的主要手段,也可能希望将角色作为筛选的主要手段。这两个要求具有相同的优点。因此,弱点也都在于命名方案。
标签
在解决这个问题中有一个完全不同的方式,即考虑将一个时间序列的标志符由一组标签组成。
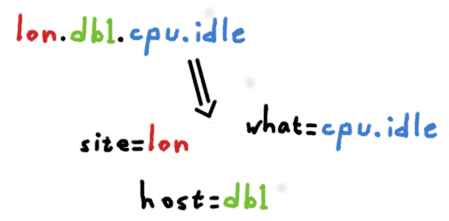
看看我们前面的例子,我们将现有层次结构映射到一组标签。
通过一个过滤系统,其能够让工程师将内部组件相互连接的一大片时间序列进行拆分。提高了互操作性。
这样一来,这就没有了我们必须严格遵守的层次结构。按照惯例,他们可能是结构的一部分(“网站”和“主机”总是存在),但它们既没有被要求,也不是严格有序的。
Atlas 、 Prometheus 、 OpenTSDB 、 InfluxDB 和 KairosDB 都是使用标签的数据库。 Atlas和Prometheus被认真考虑过,但在时间上并不可用。我们最终并没有选择OpenTSDB,因为在使用HBase时的糟糕的运行体验。InfluxDB不成熟,因为它缺乏自助服务的功能,而这正是我们需要推出的。KairosDB似乎像最好的选择,所以我们进行了广泛的试验。但发现它在性能和稳定性上存在问题,我们试图做一些努力,但均告失败。我们认为该项目由于缺乏社区的参与,并没有朝着我们期待的方向前进。
受KairosDB的启发,我们开始了一个新的项目。我们针对这个项目做了一些小的实践,并取得了可喜的成果,所以我们坚持下来了,并给它取了一个名字;Heroic。
请继续关注下一篇文章,我会介绍Heroic,即我们的可扩展的时间序列数据库。
编后语
《他山之石》是InfoQ中文站新推出的一个专栏,精选来自国内外技术社区和个人博客上的技术文章,让更多的读者朋友受益,本栏目转载的内容都经过原作者授权。文章推荐可以发送邮件到editors@cn.infoq.com。
感谢杜小芳对本文的审校。
给InfoQ中文站投稿或者参与内容翻译工作,请邮件至editors@cn.infoq.com。也欢迎大家通过新浪微博(@InfoQ,@丁晓昀),微信(微信号: InfoQChina )关注我们,并与我们的编辑和其他读者朋友交流(欢迎加入InfoQ读者交流群  (已满),InfoQ读者交流群(#2) )。
(已满),InfoQ读者交流群(#2) )。
正文到此结束
热门推荐










相关文章

近期评论
-
你这基本没有更新呀,最近文章显示还是2019年的文章。不符合要求哈
-
关键词:慕云博客 链接:https://www.lilun.me 描述:分享原创文字的个人博客
-
-
-
可以提供一下源码吗
-
不是商业站,鸡娃学习笔记
-
-
-
-
听他们说很厉害的样子
Loading...
![[HBLOG]公众号](http://www.liuhaihua.cn/img/qrcode_gzh.jpg)

