Docker 架构私有云的机遇和挑战
本文系 ArchSummit 大会 CODING 工程师王振威演讲实录。

大家好,非常高兴在这里跟大家分享,我是王振威,来自 Coding 的一个程序员。今天给大家带来的分享主要是我们团队在使用 Docker 改进原有的业务系统的演进计划和实施的经验教训。

说起 Docker,必须要介绍 Docker 是什么东西,为什么中小企业私有云适合使用 Docker。其次是我们做一套架构系统的变迁,总是事出有因的,我们必须介绍一下为什么变迁。第三是怎么变迁,作为中小型企业要想把业务假设到私有云上,如何一步一步来做。最后我们在使用Docker的过程中遇到了比较棘手和麻烦的问题。
第一,Docker,在座有相当一部分人已经了解了,它是容器技术,跟私有云有什么关系?那么首先要解释一下什么叫私有云。
私有云用这样一句话来形容是最为贴切的:就是企业内部的服务于企业自身的云服务平台。企业内部有很多服务器,有不同的业务系统,但是想让这些业务系统高效地运行起来,我们往往会采用类似于 IaaS 或者 PaaS 的技术来搭建这个平台。那么 Docker 为什么适用于搭建一个私有云的企业平台呢?因为容器技术比传统的VM技术成本更低、效率更高。关键点在于这种技术是兼容性又好的,可以使我们传统的架构变迁显得更为平滑,这是最为重要的一点。另外,容器技术一大特点就是快速实现隔离,统一调配。有如下三快:
-
构建快一个应用最终的形式往往是环境加上程序包,形成最终的镜像,image 就是程序本身外加环境,Docker 让我们可以用 Dockerfile 之类的技术定义镜像,自动构建,免去在很多服务器上繁杂的安装配置应用程序环境的过程
-
启动快容器相比虚拟机的启动速度是非常快的,开一台虚拟机的启动速度慢一点的一分钟,快一点的也要十几秒,但是容器往往可以做到秒级启动,这为我们后面所讲的容器化交付奠定了基础。
-
迁移快应用以容器的方式标准化交付,这个主机跟另外一个主机只要安装了 Docker 就没有什么差别,image 不管扔到这里还是扔到那里都可以很快地正常运行。而传统的 VM,只是省去了我们购置租用物理服务器的过程,本质上来讲还是一个裸的操作系统,本来这个程序在 A 机运行,但 A 机挂了,现在来配置 B机,装了 JDK,发现不行,这个 JDK 版本不对啦,JDK 缺少了本地的库啦,之类一系列问题。但是如果用了 Docker,用了容器技术,它把这些依赖环境全打成 image,只要把 image 下载下来就行了,这是编程语言,框架无关的,因为应用的环境是跟着应用走的。
看一下现在的架构图

开个玩笑。
如果我们的架构是这样的话那就没什么好讲了,我的意思是说一个成熟的以容器来做基层建设的私有云环境,最终的效果应该像巨轮一样,可以把所有的货舱都码放整齐,可以平稳地向前航行,这是基于容器的私有云的愿景。
有人会问了,如果说你之前的架构没问题,为何要迁移到这个环境来呢?
事出有因,假如传统的架构是很好的,我们没必要迁移到 Docker 这种私有云环境来,我们为什么要迁移?
有几个原因:
-
第一是我们之前的业务系统随着时间的发展越来越多,不同的组件需要协同去做不同的工作,给运维带来了巨大的挑战,有 JAVA 写的程序,还有些程序制定了必须用 JDK7,一些部门觉得 JDK8 有些特性比较好用所以用了 JDK8,还有些组件是用 Ruby 写的,还有 Golang,NodeJS等等,目前我们系统中牵扯的系统语言已经达到了八九种,这对运维来讲是一个巨大的挑战,我们必须要给各种各样的程序准备各种各样的环境,维护,迁移都非常麻烦。
-
另外配置混乱,当你应用的服务器数量越来越多,有的系统可能是用 upstart 来管理程序,有的是用 Supervisor , 有些程序可能只是个 定时任务。我们的编程语言每一种都会有自己的构建工具,构建工具对依赖的管理也不太一样。最终的结果是操作系统中的配置文件和各种黑科技补丁脚本散落在系统的各个角落,没人能找得到,也没人搞得懂。
-
最后致命的一点是监控和资源的混乱, 监控混乱,如果是一个很简单的程序,往往只需要做到当发生错误,把这个错误日志打印出来,运维上看一下日志就行了。当涉及到几百台应用服务器,其中的各个组件每天打印上百万条、上千万条各种不同级别的日志的时候,运维是没有精力去了解的,我们只能做错误报告,做消息的推送,但是因整体系统混乱,每个应用有各自的方式,最终导致日志,错误监控都没能达到相应的预期。然后是混乱的资源,我们做 WEB 的应用往往出现白天是高峰期,晚上是低峰期,低峰期zi'yuanziyuan使用率很低,属于资源的浪费。另外有些业务在申请计算资源的时候不能提前预估到使用量有多少,申请的过多或者过少,运维又要经常承担着缩容扩容的问题。
-
有因必有果,环境不匹配导致测试跟生产环境不一样,比如生产环境是 JDK8 跑的,某一个开发者本地用 JDK7 测试的程序,上去发现这个东西根本不对,虽然 JDK7 和 JDK8 的兼容性已经是99%以上,但是一个严谨的业务系统必须要做到测试环境跟生产环境是一致的。
配置混乱导致事故频发,做过运维的肯定了解,这个配置被谁改掉了,这个服务宕掉了,当你的组件越来越多的时候根本无从管理。监控不一致,资源效率低。计算资源的成本很高,却达不到相应的目标。所以之前那艘看起来航行很平稳的巨轮,在上面这四大原因的影响下,事实上是这样的。
上面这四点导致我们必须要统一架构,最终把整个业务系统迁移到基于 Docker 的类似于 PaaS 的私有云的平台。
架构变迁,作为一个架构团队的 Leader,在做架构变迁遵循的时候要掌握如下原则:
DevOps 变迁原则
- 即面向未来,又不过于激进
- 即追求稳定,又不过与保守
其实就是掌握平衡,追求一个度。我们用新技术,必然是为了解决旧技术的问题我们才用,但如果过于追求新技术,忽略了业务的重要性,你会发现你最终是得不偿失的。所以我们遵循的原则是既面向未来,又不过于激进,既追求稳定,又不过于保守。
关于技术选型,这是我们团队的做法。
| OS | Container | Service Discovery | Config | Container Management |
|---|---|---|---|---|
| Windows | Rocket | Consul | JSON | K8s |
| Ubuntu | RunC | Etcd | INI | Mesos |
| CentOS | Docker | YAML | Swarm | |
| Redhat | Compose | |||
| Ubuntu | None |
容器技术现在有几种选择,Docker 本身的底层就是 RunC。谷歌内部有自己的容器技术,VMware 也有容器技术,但是就目前来讲,Docker 是最好的选择。服务发现我们用了 ETCD,我不再讲哪个软件好哪个软件坏,不同的软件会适用不同的业务场景,只有适合与不适合。
接下来我会讲具体的架构变迁三步走。
架构变迁三步走遵循的最重要的一点是平滑演进。我们都知道我们的业务系统是脆弱的,经不起风吹雨打,如果大动干戈搞一下,新的架构出问题了,业务系统是承受不住,技术部门也无法承受住其他部门带来的压力。所以我们必须有序平稳平滑的演进升级。微服务是这套升级的一个基础点,如果你的这些应用不是微服务,不是无状态化的,那你就没办法让多个实例协同工作。最后是软硬分离,分割计算资源和具体业务的强依赖,其实这个问题,在我们全部走完,只要在配置好的服务器环境装一个 Docker 就搞定了。
三步走的具体第一步是 Dockerize,什么叫 Dockerize?
先把应用无状态化,你可以采用一些集中式缓存这种技术让应用变得没有自己的状态,它随时起停,起多少份都是无所谓的,只要有负载均衡器就可以让这些组件对外提供一致的服务。当无状态化应用实现之后,我们就可以给这个应用写 Dockerfile 了,Dockerfile 构建的结果就是 Docker image ,其本身就是应用和环境,第一行是from java jdk7,第二行设置应用程序,第三行把这个程序运行起来。
# Base FROM java:jdk-7 COPY ./.src/target/app-1.0.jar /app/ # ENTRYPOINT WORKDIR /app CMD [ "java", "-Dfile.encoding=UTF-8", "-jar", "./app-1.0.jar" ] 这是很简单的 Dockerfile,不要看他简单,我推荐的是各位用 Docker 就应该这么用。不需要在 Dockerfile 里写一堆 apt-get install ,一大堆 run 命令这些东西,记住 Dockerfile 就是声明应用环境和应用本身。Docker 现在做的功能太多了,很多都是不怎么靠谱的,Docker 需要更专注于它本身作为容器的技术。完成无状态化应用和写完 Dockerfile 之后,这个程序就可以被打报成 Docker image 了,放到一个 Docker Host 上运行起来就得到了无状态的应用容器,也就完成了把应用装容器的过程。
架构变迁的第二步是管理你的容器。
不能说应用扔进去就不管了,如何管,管的办法有很多,容器技术这个圈里争论最多的就是编排技术。
容器的管理方式对 Docker 来讲,目前就三种:
-
第一是直接管,我们都知道Docker 官方有一个 CLI 工具,只要装了 Docker 就可以使用这个 CLI 工具把指定的程序运行在容器里,这是更直接的方式。但明显我们有几十台上百台服务器的时候,不能每个都上去搞一下,虽然它更直接,但它比较麻烦。
-
另外一个是 Docker remote API,更为灵活,提供了相关的编程接口来管理容器。
-
最后是编排系统,它们更为复杂,定义的条条框框更多。我这里不推荐做架构渐变演化的团队采用。主要原因是,我们迁移到这些编排系统往往都是跳跃式的升级,不是平滑演进,业务系统不能容许直接把整个业务系统跳跃式升级,无法承担风险,出问题的回退预案也很难定制。当然如果是一个本身从零开始的系统,那你可以尝试一下,但也不保证这种编排系统就适应于你的业务系统。我们推荐一步一步走,先把这种应用变成容器,再来想办法管理这些容器。
很显然我们采用的是第二种选择。
配置文件配合 Docker remote API。根据实际情况,选择Docker的少量的一些特性,例如文件系统、网络、资源限定等这些成熟的,我们最为需要的功能,我们编写了一个便捷的操作工具 cli/web。
在配置文件中定义一个任务,名字写下来,这个任务用什么 image 跑,什么版本,运行在哪台机器上,注意这里,机器名并不跟具体的业务绑定,而是一个资源池,不管什么应用都是无差别的,只要是无状态的应用,所有的存储、依赖都通过网络的形式来解决,我们整个资源池就可以实现自由调度。
如果把这个应用绑定到某一些具体的特有的机器上的话,局限性比较大,万一这些机器出问题,将无法快速迁移。有一些选项是没填的,比如 port, port 其实是 Docker 支持把容器内的某个端口映射到容器外,我们没填这个东西是因为,我们默认在全系统级都只使用Docker的 host 网络模式。 host 模式下,Docker 内部容器的网络跟宿主机的网络是一样的,这是 Docker 所有网络模式中性能最高的,缺点是不能做隔离。
这里有人可能会问,为什么要放弃隔离呢?这里解释下没用 Docker 的高级的网络模式,以及 SDN、端口映射等的原因。就是没必要。注意我们讲的是私有云平台,私有云平台内部都是企业自身的业务,大部分业务都基于业务层面做隔离和权限就可以了, 所以 Docker 用 host 的模式运行就跟传统应用没有差别,不需要做 NAT,SDN,也不需要做端口影射,另外一个好处就是,对于应用来讲他们的依赖用容器和不用容器都是一样的,这完全符合我们要求的平滑演进。
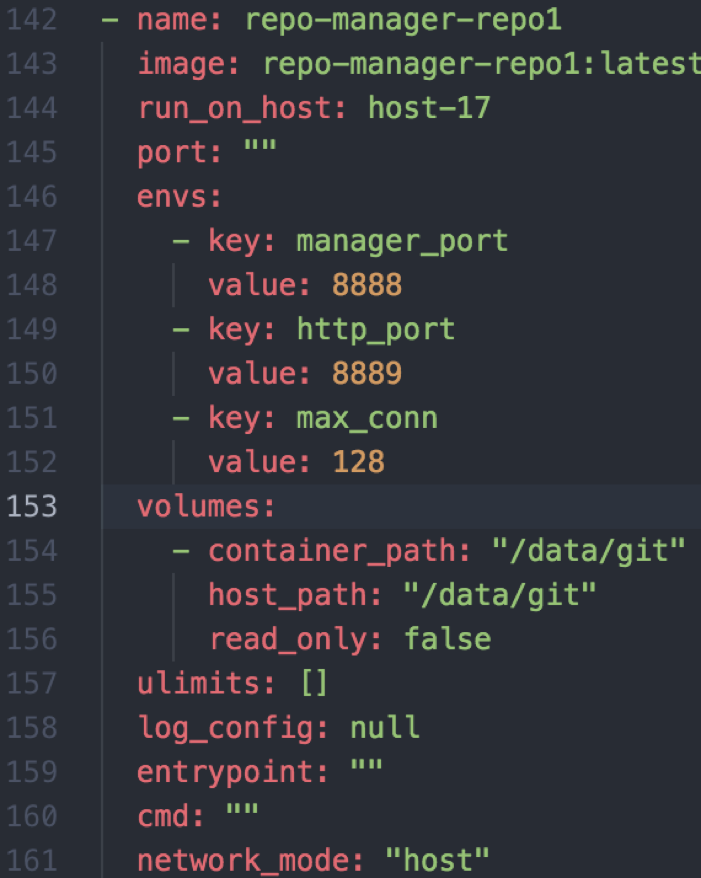
下面还有其他的配置,我们会通过环境变量控制一些应用内部的参数,因为我们的配置文件往往是打包到 image 里面,但是 Docker 这点挺烦的,改一个配置文件都要重新打一个 image,我们最终把配置项做成环境变量或者 CMD 参数,这样可以在组件间共享一些 image。

这是我们用CLI在更新某个实例的时候打印出的内容,这是我们自己的定制的,它会告诉我们当前运行的实例的名字是什么,运行时间是什么等等一系列内容,只要选择指定版本代码的 Docker image,我们就可以完成全自动化的更新。
另外我们还部署了一套 DockerUI,这个软件总体用下来不是特别好用,这是它大概的界面,跟我们 CLI 的功能比较类似,我们之后会自己定制一个运维的系统级 DashBoard。
架构变迁第三步就是如何真正地把我们上面实现的内容替换到现有的系统中。
釜底抽薪,这个形容是比较贴切的。我们的服务都是无状态化的,这个服务运行在哪里是无关紧要的,运行多少份也是无关紧要的,只要把这些新的容器化的交付应用替换掉之前的以各种杂乱的形式运行的应用,由于演进是平滑的,直接替换即可,整个系统就有机结合起来了。
完成架构变迁前两部之后,假如现在系统有50个组件,只完成了5个组件的 Docker 化、无状态化、编排。没问题,我们的原则就是平滑,渐进,你不需要全部搞定,就可以开始应用到生产环境了。目前 Coding 的 95% 的组件都运行在 Docker里面,为什么留5%,是因为有一些极其边缘的组件,因历史遗留原因还没有迁移过去。事实上我们发现只要前两步做的好,第三步是很容易的,简单来说就是停掉旧服务,启动新服务。
这里值得一提的是,不光我们的主业务系统需要这么做,我们的一些附属业务系统包括监控系统、负载均衡系统、服务发现等等,都应该按照这个架构一步一步替换过来。最后实现计算和存储分离,软件和硬件分离。因之前不是在容器中运行,应用对某个服务器可能都是一种强依赖的状态,而现在把这些组件替换掉之后,你所有应用的环境都封装在 Docker image 里面,这些服务器上本身没有任何各个语言的执行环境,他们都是 Docker 宿主机,自动就变成无差别化的了。Docker Image只要放到任何一台装有 Docker 的环境上,就可以很快运行起来。
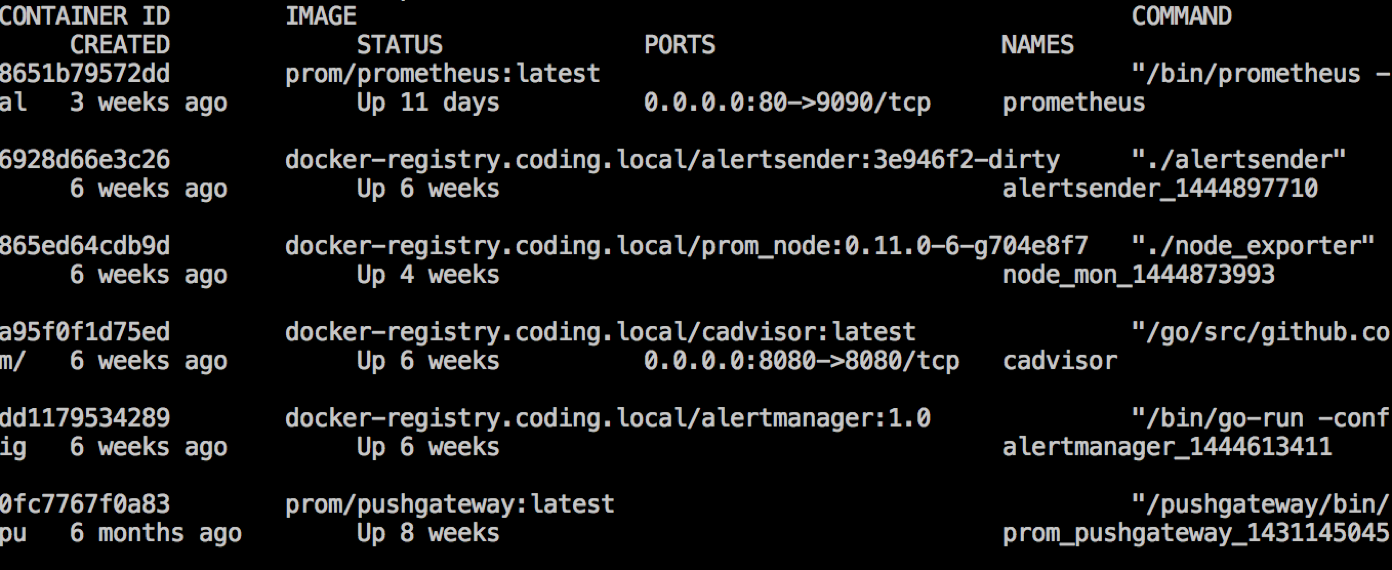
这是线上的 Docker 容器的列表截图,这是某一台服务器运行的实例。最终形成的架构是这样的:
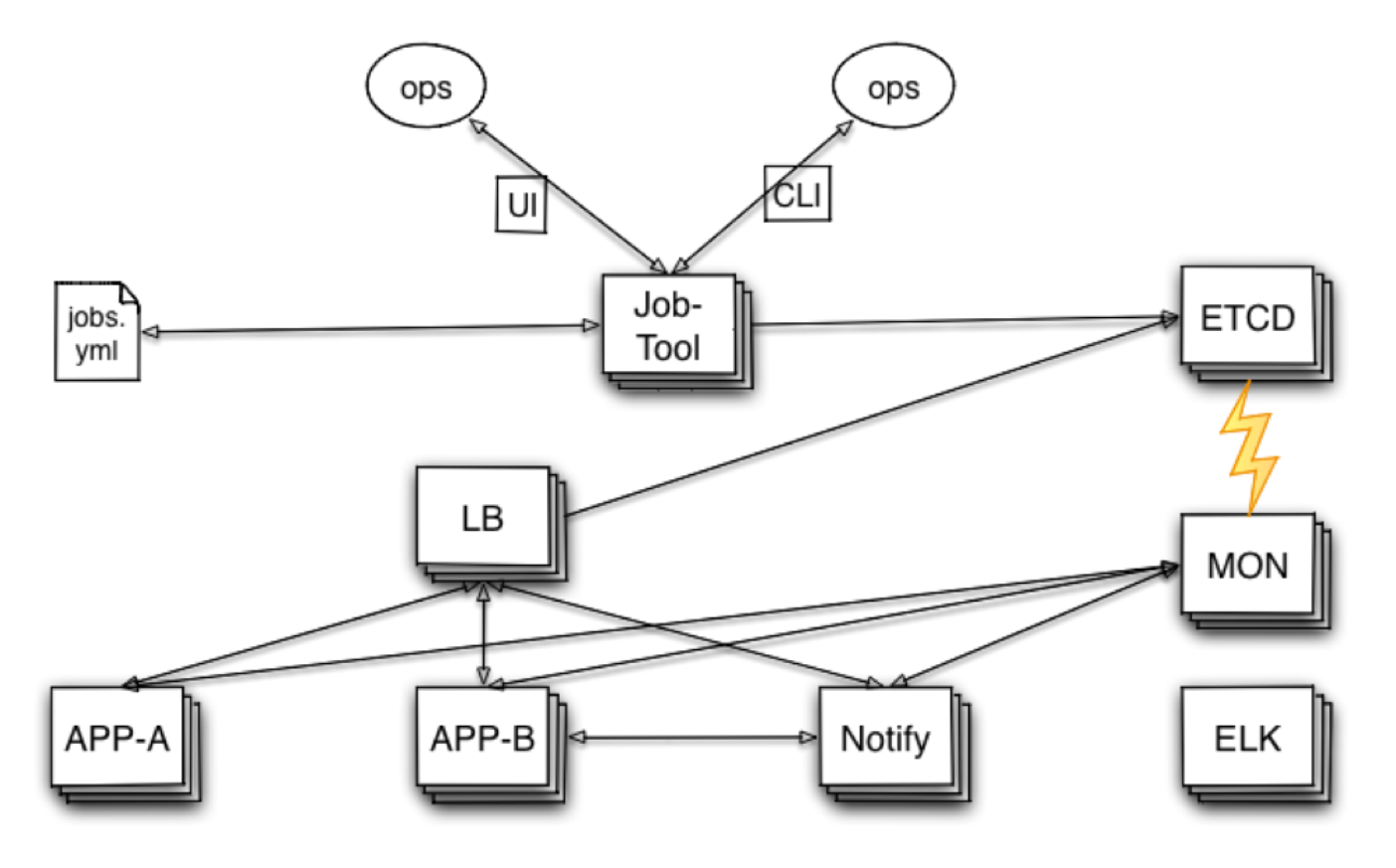
当你们看到这个架构的时候觉得它并不高端也并不奇怪,因为很多传统架构就是这样。而我想说的是我们完成这些东西其实也并不违背传统的高可用分布式架构,只是釜底抽薪,把底层的进程组件换成了容器,把原来管理应用的方式换成了管理容器的方式。
我们现在运维的流程是这样,运维有两种方式来操作这些容器,分别是 CLI 和 UI 界面,运维操作都是发往这个工具,这个工具是可以管理现有所有的容器,所有的容器的定义都会存放在相应的配置文件里,这些配置文件还会在 ETCD 里做一个副本,LB 系统监控系统等等需要知道这些组件的状态。
LB系统是内部服务的总入口,比如内部有一个很小的服务,这个服务做的事情很简单,所以它属于微服务的特点,微服务就是某一个组件每一个服务只做好一件事情,把这个事情做到极致。而 LB 就是把对这些服务的请求转发给相应的无状态组件。
我们有一个微服务的组件 md2html 就做一件事情,就是编译 Markdown ,所有其他组件但凡有需要编译 Markdown 的都通过 LB 系统调它。这个组件使用 Ruby 写的,其运行环境比较难配置,牵扯到一些原生的 C 的库,会对一些本地库有些版本需求,新增服务器很容易配置错误。现在就没问题了,这个应用的环境已经被我们打包成 image 存入了 Docker registry ,即便我们装有运行环境的那台机器宕了,我们只要用 Docker pull 下来,立马就能迁移到另外一台服务器。
我们的监控系统跟 LB 是什么关系?监控系统会对每一个容器的关键指标做数据收集,比如 LB,比如刚提到的 md2html ,都会维护一个 Http 接口,这个接口里提供它的关键指标的数据信息。计算资源服务器的关键指标有内存使用量,CPU 使用率等等。应用程序的关键指标都由各个业务应用自己定义。
例如我们这个 md2html 他的一个关键指标就是每秒钟处理的MD数量。
我们的监控系统会定时抓取这些关键指标,要求较高的是 5 秒一次,要求低的可能是1分钟,抓取之后存入数据库,再配上一些监控的报警规则。比如一个 md2html 实例,正常业务量可能是每秒钟处理10个编译的任务,但是监控系统查到连续五分钟处理量都低于3,我们就认为这个实例有问题了。
监控系统在遇到问题时,一方面会发一条消息到 ETCD 里面,告知现在这个实例异常,LB 系统订阅ETCD,LB 系统 watch 到相应的改变之后就会把自己的配置改一下然后做一次 reload,这个实例就自动下线了。另外,监控系统监测到问题的时候会发一条消息到通知中心,通知中心会把错误的信息直接通过手机 APP 推送给运维人员。另外我们还支持包括发邮件,发短信,打电话等等形式。通知中心是我们这个系统中组件共用的,还有些普通的业务应用也会用到通知中心这个组件。
这些组件都是运行的多个实例,不要觉得业务量不大何必运行这么多实例,对一个服务来讲,它没什么负载,它运行着也不会占你太多的计算资源,据我的了解我接触大多数人的系统架构里计算资源都属于过剩的状态,他们却不愿意去多运行几个实例来提升可靠度。
这里是我们这个架构图的一些细节:
- LB 系统: Nginx / HAProxy / confd / Etcd
- 监控系统: Prometheus / cAdvisor / Http Metrics
- Docker Registry V1
- Docker 网络:Host
- Docker 日志:Mount 宿主机
HAProxy/ nginx这些很普通的负载均衡软件。confd 是一个很简单的程序,就做一件事情,confd 一直 watch Etcd 中服务的容器应用状态,一旦有改动,就生成新的LB 配置文件,并 reload LB 程序。这也印证了我们坚持的一点,系统中所有的组件只做一件事情,而且把这件事情做到极致。
假如说我们现在有三个 md2html 实例,当某一个实例挂了,监控系统检查到了相关问题,知道它挂了,这时监控系统会两件事情,把它挂的消息通知到 ETCD,推送到ETCD 后,confd 会自动 reload LB,实现 LB 系统的自动切换。另外就是发送通知给运维人员,好让运维查出系统的问题,从而做出响应。
我们搭建一个 Docker RegistryV1 版本,现在已经发布了V2 版本,Docker 官方 V1 和 V2 版本不兼容,V2 也改了名字,叫做 Distribution。我们用到现在没出特别大的问题,完全没有激发我们升级新版本的动力,因为V1用得挺好的。
Docker 网络,Host 模式,优点在于性能高,平滑。如果不用Host的模式,用 NAT 模式会非常痛苦,NAT 模式虽然安全,但是对于私有云内部来讲没有危险的应用,所有程序都是自己写的,没有不安全的,就算它不安全,你之前没有用 Docker 的时候它也是这样,所以用这个 Host 模式并没有增加不安全度。最后是 Docker 日志,我们之前踩了一些坑,现在的做法是让它直接写到宿主机的日志文件里。
我们的架构接下来的改进方向是如下几个点:
- Job-Tool 进化成 Job DashBoard ,集成监控(cAdivsor),日志(ELK)等功能
- 利用监控系统的硬件指标,根据业务用量实现自动扩容,缩容
- 分析各个业务对硬件资源的使用量和高低峰,设计混布实现提升硬件使用率
- Docker image 的构建和管理
- 动态调整 container 的资源限制
吐槽一下Docker的问题。Dockerfile 有点用,但没什么大用,就是几句话的问题非要编译那么大的镜像,改一行配置都需要重新编译一个 image。Docker Daemon,很不稳定,我们出的很多问题都是它导致的,它功能太多,很多问题也就是他这些无用的功能导致,我们认为 Docker daemon 只需要做几件简单的事情,帮你管理容器,起、停、删除就完了。Docker 官方最近刚推出了一个 ContainerD,就是一个简化版的 Docker Daemon,基于 RunC 的,就非常符合我们对于 Container 管理的看法。
我们之前踩了两个比较大的坑,一个是容器标准输出输出大量数据,会导致内存泄露,从而导致 Docker Daemon crash。另外一个是Docker Daemon 在频繁创建删除容器(每天几十万个)会出现性能严重下降等问题,只能重启 Docker Daemon。标准输出问题,必须要满足的两个条件是输出数据量大、输出速度快。
这里列出了我们关于标准输出问题的简易重现方式和最终 Docker 的修复方案。
- 重现方式一: docker run ubuntu yes “something long”
- 重现方式二:docker run -i ubuntu dd if=/dev/zero of=/proc/self/fd/1 bs=1M count=1000
- Issue: https://github.com/docker/docker/issues/14460
- Fix By: https://github.com/docker/docker/pull/17877
最后,关于并发性能问题,测试环境比较复杂,还在进一步研究中,欢迎各位来Coding.net 冒泡共同探讨。
谢谢大家。
正文到此结束
- 本文标签: cmd https 进程 UI IaaS json 性能问题 web tab git 数据库 系统架构 GitHub 实例 开发 下载 java 测试 VMware 事故 配置 SDN HTML 操作系统 删除 Ubuntu 定制 自动化 科技 安装 API 程序员 参数 http 云 编译 node tar 安全 管理 App 快的 主机 服务器 remote apr PaaS 时间 软件 src Nginx 端口 负载均衡 centos 数据 需求 谷歌 dist windows js 压力 开发者 代码 Docker 企业 安装配置
- 版权声明: 本文为互联网转载文章,出处已在文章中说明(部分除外)。如果侵权,请联系本站长删除,谢谢。
- 本文海报: 生成海报一 生成海报二
热门推荐










相关文章

近期评论
-
你这基本没有更新呀,最近文章显示还是2019年的文章。不符合要求哈
-
关键词:慕云博客 链接:https://www.lilun.me 描述:分享原创文字的个人博客
-
-
-
可以提供一下源码吗
-
不是商业站,鸡娃学习笔记
-
-
-
-
听他们说很厉害的样子
Loading...
![[HBLOG]公众号](http://www.liuhaihua.cn/img/qrcode_gzh.jpg)

