创业型小公司如何做好日常的监控运维

从大公司投身到创业型的小公司,我最深的感受就是“由奢入俭难”这五个字。以前公司里有完善的框架体系,涵盖了分布式log、监控、实时报警、大数据存储等等方面,并且有成熟的团队来运营,使用者大部分时间只要做好集成就行;换到了小公司,初始的一长段时间内,技术团队只有3人,起步阶段一穷二白,而且要做两个体系的产品,每天业务的压力就很大,做起事来只能用些比较粗糙的手段。业务的压力和质量的追求始终是个矛盾。然而,该有的绝不能少,所以我们还是尽量抽出一些时间做好部分必须的框架工作。在我们看来,监控和报警框架是优先级最高的:
1.创业型公司在测试方面,无法做到非常充分, 出现问题的概率比较大,需要做好监控 。
2.对一个复杂系统的把握,必然是大量的自动化的监控、度量,时刻要知道系统里每个组件的各种运行指标。实际上,有经验的工程师会体会到, 做好监控和运营,在难度和重要性上要远高于你写的功能代码 。
3. 人少,就要自动化程度高 。只有做好监控和自动化报警,才能抽出更多的精力忙业务,晚上才能放心睡觉。
因此,想要做出可靠稳定的产品,首先要有靠谱的监控报警框架去做支撑。而对于像我们这样的创业公司来说,还需要关心以下几点:
1. 有没有成熟的开源产品 。大公司可以花费一个团队专心做一件事情;而小公司每个人都是非常珍贵的资源,半个人的开销都嫌大,所以会更多的借力于开源产品。
2. 坑多不多 。开源产品的质量和支持没有办法和商业产品相比,所以我们需要选用可以hold住的,坑少且稳定的产品使用。
3. 能否支持跨语言 。我们的产品基本上是C、Java、Python、JSON的混合产品,尤其是后端主要由Java和python组成。
4. 可伸缩性是否足够好 。我们的业务和数据在快速发展,所以使用的产品必须能支持后期海量数据的涌入。
5. 是否有一定的扩展性 。使用过程中必然会有一些特殊的需求,如何快速的做些定制化也是需要考量的点。
6. 能否同时支持单机和分布式的部署 。我们情况比较特殊,既有传统的私有化部署的软件解决方案,又有公有的SaaS以及配套的大规模计算集群。因此,我们很多产品都要有高低配两种实现,同时通过配置来实现无缝切换。监控系统也不例外。
极度重要,要求又多,资源还少,所以我们在监控和报警方面还是花了一些心思。下面,我会详细分享下我们所做的实践探索。
先看监控
首先要谈监控。 监控的要点就是通过定义多种metrics来辅助我们去了解产品 。从硬件到软件,从LB到后端数据库的实时运行状况,帮助我们发现问题、故障甄别和确认恢复。这是最重要的事情。
举个例子
废话少叙,先来张以前的图看个大概:

此图是我们业务系统metrics的一个例子,显示了我们前置nginx的部分metrics,通过实时的分析nginx log,我们可以得到所有机房nginx在吞吐量、延时、负载分配、流量等等多方面的实时信息,一目了然;还可以根据不同维度进行分析比较,帮我们有效的找到各种异常情况(图里就有一个小缺口)。类似的metrics,我们目前已经有几百个,通过不同的面板组织起来,并且还在不断的增加。目前,公司的原则是每个项目在开发之前,就需要尽可能多的定义出相应的metrics,做好详尽的监控。
技术选型
眼尖的同学会发现我们用了开源组件grafana。事实上,我们在metrics存储上采用的就是influxdb/redis+grafana的组合:
1.在我们的SaaS后台,采用influxdb+grafana 2.0(2.0有单独的后台服务)的组合,存储了海量的metrics,同时满足大量数据的写入,以及监控报警系统的频繁读取,同时保留横向扩展的可能性。
2.在我们的测试环境/私有化部署环境,采用redis+grafana 1.9的组合,这个组合部署简单,开销相对较小,可以满足少量的metrics使用。实现上,我们根据influxdb的存储结构在redis上复刻了一份,并且通过proxy来模拟influxdb的接口。
3.实现方式上,我们提供了Python/Java两个库,并通过配置文件来作redis/influxdb的无缝切换。每个应用根据自己的需求来决定配置,并调用api将metrics信息记录到合适的地方;同时框架自身也做了一些组件专门用来收集系统层面的metrics(比如上面的例子就是通过syslog服务来接受nginx日志,并做实时的metrics统计)。
得出这样的架构选型,我们当初也是伤透了脑筋:
1.前公司用的是类opentsdb的系统,在使用便捷性和性能上没的说,但后端强依赖于hbase,对于我们并不合适。
2.当时也看了其他针对这种Time-series data的开源方案,目前其实没有什么特别好的方案。
3.最终我们还是选了 influxdb做为主力 ,这是一个相对轻量的开源时间序列数据库,很适合于做为metrics使用:它有类似SQL的查询语句比较容易上手;自带简易管理界面;可以用grafana作为前端看板;还有各个语言的客户端支持;最后,它最近还是比较火。
4.选redis的原因在于:私有环境下需要一个简单的方案;比较熟悉,当influxdb碰到问题时,redis版可以作为备胎顶上。
5.最初我们也考虑过用elasticsearch这个大杀器来做metrics使用,然而:
(1)es 是重读轻写。由于是搜索引擎的出身,它强调索引。你写一条记录,还伴随着大量的索引工作,有人做过实验,es和influxdb之间在存储上是10x的关系。所以es注定写性能不是强项(就单机而言),而且索引的建立必然带来延时和复杂性。当然有了索引,在做一些过滤和聚合的时候,搜索引擎的优势就发挥出来了,能出更多的报表,也能支持长时间的查询。
(2)influxdb是面向时间序列的数据库,这一类数据的特征是数据量大,写入压力高,所以influxdb在索引上没有侧重,保证了大量数据的快速存储;缺陷在于,没有索引,每次查询需要过滤全量数据,但是基本上能保证读到最新数据(没有延迟索引的影响)。所以,influxdb是轻读重写。
(3)我们的metrics主要是监控当前状况,偶尔会回溯一下历史,同时这些数据会被实时报警系统使用,要求响应比较快。从使用场景和成本的角度,我们最终选择了influxdb做为metrics的存储,elasticsearch单做BI工具使用。
metrics监控架构
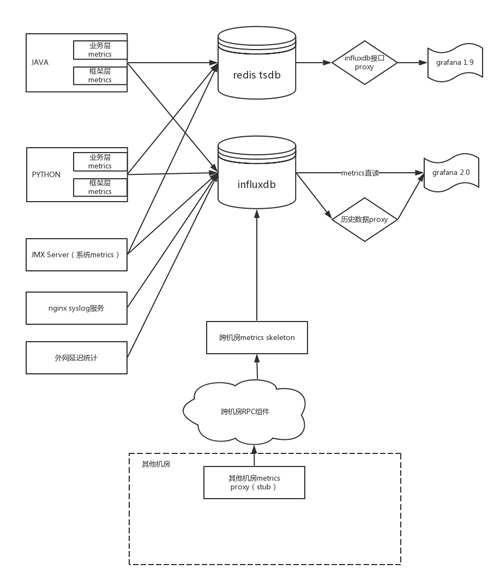
此图概括描述了我们的监控结构。
1.Python和Java程序 通过metrics库将相应的数据打到指定的地方 。
(1)程序里用到的框架组件(如rpc,分布式log等)会由组件自身进行打点,方便框架层面的统一监控排错。
(2)程序里的业务metrics需要由工程师手动打点,来记录每个业务和程序模块的特殊运行状况。
(3)为了保证后端metrics数据写入的稳定性,我们在client段做了部分聚合操作,减少打点数据。
‘ * redis和influxdb做成驱动形式,通过配置来指定,开发人员不需要关心具体的实现。
2. 通过jmx,我们来获得系统数据 ,并打入到metrics系统,来查看各个机器的物理状况(感谢前同事wxc的jmx库)。
3.建立syslog服务,对nginx日志进行统计分析,可以 得到网站访问的各种统计信息 。
4.对于 外网延迟等其他数据 ,也可以用相应的agent来打入到metrics系统。
5.由于我们的架构是跨数据中心的统一架构,还需要接收各个分机房的数据,我们通过在每个机房建立proxy来接收数据,并由自研的跨数据中心的rpc服务来进行数据传递。这样, 在主机房的报表中能看到全国的系统运行状况 。
6.对于 线上的大型系统 ,我们采用grafana 2.0直连来进行数据展示,历史数据通过proxy来完成。
7.对于 私有部署环境和测试环境 ,我们将数据记入redis版的tsdb,通过proxy来提供influxdb接口,来无缝的接入到grafana 1.9(比较轻量,可以嵌入web应用)之中。
其他监控工具
上文描述的metrics系统解决了我们大部分的问题,是我们监控系统的主要成分。同时,我们还使用了一些其他零散的手段:
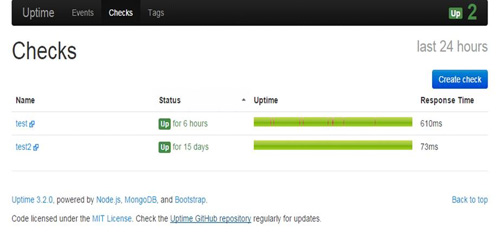
1. uptime 。Uptime是一个开源项目,通过获取网页的心跳数据来检测网页的可用性。如图:
2. 系统资源(CPU、内存、硬盘)监控 。系统监控工具很多,一开始我们使用的是collectd这个传统的工具;后来出于定制化、统一化、练兵的需要,我们改成自己写Java程序,通过jmx来获取相关数据,并打入到metrics系。collectd就停止使用了。
3. 脚本和外部工具 。在遇到特殊需求,通用的系统无法满足的时候,我们也会通过写shell脚本来做一些工作,这种方式在开发效率和功能上都比较棒,只是不能很好的和其他数据集成;同时,目前互联网上也有不少监控服务,我们也用了一些,来作为自身监控系统的补足和备胎。
二次开发
因为主要借助于开源系统,所以有时候需要进行一些二次开发来满足公司的定制化需求。这里举一些比较有用的例子:
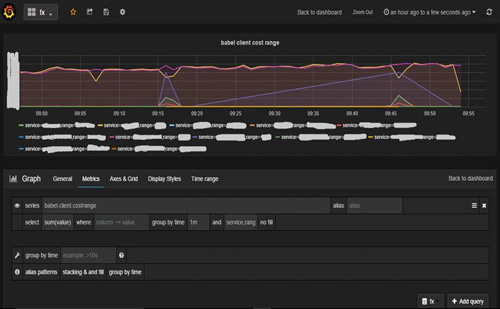
1.grafana默认的分组显示(group by)只支持一个tag,这种使用场景比较有限。为了让其能支持多个版本,我们在两个版本上都修改了它的前端JS代码,如下图所示,修改后的版本可以 显示多个tag组合的数据情况 (这里是我们的rpc统计中,所有服务的延时范围统计)。
2.grafana不支持聚合嵌套,所以像distinct count这样的功能无法实现,这个也通过修改前端代码解决。

3.grafana可以建多个metrics进行比较查看,但永远显示的都是最新的数据,不方便做同环比比较。我们 通过proxy来返回一段时间前的数据 ,来达到这个目的。
4.Uptime检测https的网页会有证书错误的问题,需要 手动在代码里禁用相应的环境变量 。
接着,谈报警
光有监控是不够的,因为这么多的数据和报表,无法通过人肉的方式跟踪,所以在收集到这么多数据之后,需要有自动化的报警系统来进行进一步的分析和处理。为此,我们基于收集到的海量数据,开发了一个轻量级的报警系统,包括报警系统的完整架构如下图所示:
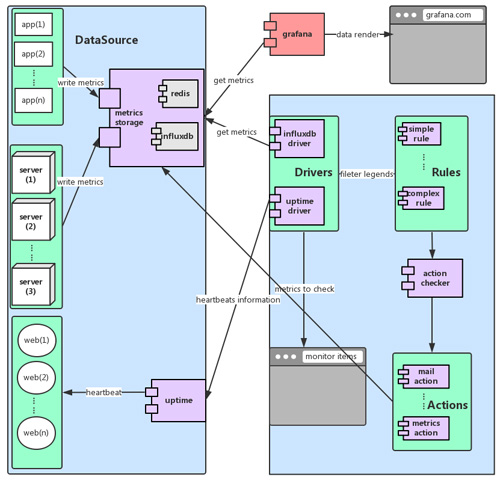
这套系统主要由DataSource,Drivers,Rules,Actions等几部分组成:
1.DataSource和相应的Driver对应了不同的监控数据来源。
2.rules表示我们的一些报警规则。
3.actions是规则命中后的触发动作。
DataSource和Driver
data source表示不同的数据来源,每种数据来源都由相应的driver来获取,并抽象成统一的数据格式(我们采用了类时间序列的格式),这样可以把数据抽取系统和规则引擎完全解耦,减少开发复杂度。目前,我们的datasource,包括:
◆tsdb中的metrics数据。
◆这是最主要的数据来源,通过获取存储在redis/influxdb中的metrics数据,我们可以对海量的监控指标进行详尽的分析。
◆grafana面板可以生成influxdb dsl,我们的报警系统直接支持利用此DSL进行报警,这样使用者在grafana面板上配置好监控项后,可以很方便的进行相应的报警。
◆通过上文描述的metrics proxy可以获取metrics的历史数据,方便做同环比检测。
◆uptime的数据。uptime可以对各个url进行监控,通过获取其数据可以进行网站存活性报警。
◆其他数据。还有其他类型的数据,比如collectd等,也可以方便的集成到报警系统中来。
Rules
从各种data source定期的获得统一格式的监控数据后,下一步就是通过报警规则进行数据检查了,来验证数据是否超出了预设的阀值。报警规则向来是个复杂的问题,需要满足各种各样的需求。为此,我们在开发规则引擎时,比较重视减少开发的复杂程度。目前我们的规则,有以下两类:
1. 单数据源简单规则 。简单规则通过对每次最新的监控数据进行阈值比较,来获得报警。比如:
(1)上下限阈值比较。这种是最简单的,定义好上限和下限,就可以发现异常值。
(2)数据存活性比较。当发现某一监控项的数据存在(或消失)时,即报警,用来检查错误指标(或存活指标)。
2. 单数据源组合规则 。简单规则产生的报警有可能非常多,我们可以通过对简单规则产生的结果进行进一步的处理,来减少报警量。比如:
(1)多次报警。当简单规则触发的内部报警在一段时间内超过一定的次数时,才进行真正的报警。
(2)报警cooldown。当同一报警不停出现时,此规则会进行相应的抑制。
(3)断崖式报警。当监控数据出现断崖式特征时,才进行报警。
3. 多数据源组合规则 。有时候,单一的数据源还不够,需要对多个数据源进行计算后获得。比如:
(1)同环比报警。对同一监控项可以拉取不同时间段的两条数据,就可以进行相应的报警。
(2)组合运算报警。比如说nginx 2xx状态比例的监控,可以通过对2xx次数和总访问次数的计算来获取。
这里只是举例描述了一些规则类型,实际系统中会有更多的类型。
Actions
在获得报警数据后,需要促发一些行为,来完成整个自动化。
1.最常用的报警动作就是发邮件了,通过对每一类报警制定不同的监控人,可以使相关人员第一时间获悉系统异常。
2.微信报警,邮件的补充。
3.规则引擎产生的数据可以进一步写回metrics系统,作第二轮的监控报警。比如前文描述的2xx比例(类似的还有各种比例等)。在这种情况下,报警系统相当于一个定时的自动化引擎,来做一些定期的数据处理,方便我们做更好的监控和报表。实际上,这个规则引擎会成为我们后期自动化任务引擎的基础。
有了这套系统,目前我们的运营监控基本实现了自动化。系统故障时会有相应的报警邮件来通知,这样开发人员可以集中精力在新功能的研发上。
数字化运营
实际上,整套报警监控系统不但帮助我们去维护网站/系统的稳定性,提高自动化程度,还能提升我们的数字化运营能力,最大限度的提升整个公司的效率。
1. 简单报表 。grafana这种可视化工具可以解决大部分初期的报表需求,免掉了初期BI人员的投入。
2. 定期报表 。我们利用报警系统,做了简单的修改,可以对一些监控项,在每天凌晨进行强制报警(数据采集选取1天,报警显示详细数据),这样每天早晨都可以收到过去一天的统计报表。由于复用了现有的系统,省掉了相关报表功能的开发。
小结
本文是我们在过去的大半年中,在监控报警上做的一些实践探索。事实上,在后面的日子里,还需要进行更多、更复杂的工作:
1.接收其他来源的数据,同时大力完善公司内部的监控体系。
2.完善分布式log机制,方便排障和更细粒度的监控。
3.将报警监控系统和生产的业务发布系统打通,来实现弹性扩容和自动容灾的可能性。
关于作者

吕梦琪,上海岂安信息科技公司bigsec框架研发负责人,主导底层框架系统和Java服务端的研发工作。她擅长Java研发、分布式系统、监控系统以及各类开源项目的引入和改造。
正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](http://www.liuhaihua.cn/img/qrcode_gzh.jpg)

