海量数据实时计算利器Tec
引子
在刚刚过去的2015年双11大促中,搜索事业部的实时计算和在线学习系统Pora经受住了前所未有的双11巨量用户行为消息的冲击,在流入实时消息量持续超过300w/s,甚至峰值飙升至501w/s的压力下始终保持了端到端秒级实时效果,助力相关的搜索和推荐实时业务取得了很好的效果。
Pora如何能在如此巨大的压力下不延迟?除了其在业务层面所做的种种优化以及集群层面的有力支持外,与其核心层Tec的设计实现是分不开的。
另一条完全不同的战线上,AliExpress(AE)搜索的离线数据库Dump业务在双11期间实现了从几小时批量到秒级实时的历史性飞跃,同时做到了全量增量一体化。得益于离线实时化,AE算法在双11中也取得了惊艳的效果。
与Pora相同的是,AE的离线新架构中也采用了Tec进行实时计算。
什么是Tec?
Tec是针对海量流式数据实时计算场景的一套高效的轻量级实时计算框架,支持快速开发高吞吐、低延迟的实时应用。
Tec名称取自于潮汐发电领域的Tidal Energy Converter(TEC),寓意其最适合的应用场景是在海量的流式数据驱动下作实时计算产出高价值的数据。

这里的实时计算具体逻辑可以依据应用需要灵活定制,可以是对流式输入数据进行的简单加工处理,也可以是基于输入数据和其它已有数据的复杂加工处理。无论何种场景,Tec都会尽可能快速地完成所有逻辑的处理以保证实时,这对于海量数据实时业务中经常需要关联查询或更新相关数据的复杂场景特别有用。
在实时基础上,Tec还作了大量封装和抽象,具备很强的通用性,从而使得开发各种实时应用可以很简单。
历史
Tec脱胎于Pora。
从2013年开始第一代Pora系统的研发后,期间经历海量数据和复杂实时业务场景的千锤百炼之后,终于到2014年形成了高性能的第二代Pora系统,其核心层部分已对实时数据的处理过程作了相当程度的优化,这一系统在14年的双11大促中初试身手即通过其实时性能帮助算法取得了实时流量调控的很好效果。
我们在14年中的时候已经意识到Pora的核心层完全可以复用于更普遍的流式计算场景,解决更多业务的实时性问题,于是在14年双11之后立刻启动了相关的工作,将Pora核心层代码剥离出来,将其作了更深层的抽象和改进后,形成了现在的Tec。
目前Tec除了应用于类似Pora的实时日志处理场景,也广泛用于搜索Dump中心的其它实时场景。
特点
Tec具备以下鲜明特点。
- 低延迟
Tec内部的In-Memory DAG实时计算框架通过尽可能地将DAG节点并行处理,可最大程度加快数据处理过程,从而缩短总体端到端数据处理延迟。
- 高吞吐
除了低延迟带来的吞吐保障外,Tec支持多线程并发处理,每个线程相互独立,通过内部的DAG批量处理输入数据,从而可进一步提高整体吞吐。
- 海量数据处理
Tec原生支持HBase作为海量数据存储并在使用方式上进行了大量抽象和优化,方便应用使用,并确保支持快速的高并发随机读写。
- 易嵌入
通过使用Tec提供的API,开发人员可以很方便地将Tec嵌入到自己的程序中用于数据处理。
- 跨平台
由于易嵌入的特点,Tec可以嵌入多种计算平台的分布式应用中(比如iStream和MapReduce),同时复用代码逻辑。
- 易监控
Tec自带了众多Metric并允许使用方扩充,可方便实时或事后观察系统运行情况,统计运行数据;同时Tec也提供Trace API,支持跟踪单条数据处理的详细过程。
- 少开发
Tec抽象出了通用的存储、数据结构和常用数据处理逻辑,可复用于众多业务场景,开发人员只需开发少量较特殊的业务逻辑;同时Tec支持和鼓励使用配置代替代码,从而使得业务开发维护可以进一步简化为配置工作。
- 可定制
Tec采用松耦合的设计,对通用的存储、数据结构和处理逻辑无法满足的场景,用户可遵循Tec的接口灵活扩展定制。
- 通用
Tec适用于任何流式计算场景,特别适合海量流式数据的实时处理。
定位
Tec定位于底层流式计算平台和数据存储之上,业务层之下,通过嵌入到底层流式计算平台的处理进程中运行。处在这个位置,Tec可以隔离业务和底层系统,通过底层计算平台接入数据,通过自身高度优化后的实时计算实现保证业务实际运行时具备高吞吐和低延迟的能力,通过暴露少量接口给业务层大幅降低业务开发成本。
由此带来的另外一个好处是,业务可以在不同底层计算平台(比如MapReduce和iStream)间复用相同代码,这对某些既需要批处理又需要实时流程的业务(比如搜索批次全量和实时增量)来说意味着可以只需要维护一套代码,同时也降低了未来可能的底层平台切换成本。
目前Tec使用的底层系统和支持的上层业务如下图所示。

业务层表示不同业务场景可以基于Tec定制自身特定的平台框架,比如Pora和Dump领域各种完全不同的业务平台。
计算平台部分目前原生支持iStream和MapReduce,分别对应long-running流式计算和批次流式计算场景。后者听上去有点奇怪,但实际上很多批次任务特别是Map Only任务在处理数据时大多是逐条处理的,其本质还是流式处理,因而完全可以使用Tec。至于其它目前未支持的流式计算平台,理论上Tec也都可以很容易地嵌入其中。
针对海量数据,HBase既可以提供存储支持,又可以提供快速随机读写,从而使得对海量数据流的各种实时的复杂关联计算成为可能,Tec因此选择它作为原生支持的数据存储进行了抽象封装和大量的优化使用,使应用开发可以低门槛高效率的使用HBase。HBase之上,HQueue是Tec目前配合iStream使用时在上下游应用间可能需要重新分发数据时默认支持的一种基于HBase的队列实现,OpenTsdb则用于存储Tec的Metric历史数据以便监控应用运行状况。
DAG实时计算框架
基本概念
- Container
嵌入式场景下不同流式计算平台中Tec的载体,比如对应IStream的IStreamContainer、对应MapReduce的MapContainer/ReduceContainer。
- TecWorker
每个Container实例内部通过实例化一个TecWorker对象将Tec嵌入其内部,将数据交由TecWorker处理。
- TecThread
一个TecWorker内部可以有多个TecThread线程,各自独立地并发处理输入数据。
- Dispatching
TecWorker将数据交由某个TecThread的过程称为Dispatching,对应的实现类称为Dispatcher。
- 数据源
每个输入数据对象都有一个自己所属数据源的标记。
- DAG处理链
允许对每个数据源配置处理链,处理链包含多个节点,节点间按数据处理流程彼此依赖形成一个DAG。
TecThread内部对每个数据源维护一个内存中的DAG处理链,输入数据会触发对应数据源的DAG处理链上每个节点依次执行,直到所有节点都执行完毕后认为该输入数据处理完毕。
- Executor
DAG处理链上的每个节点称为一个Executor,表示该节点负责的具体数据处理逻辑。
基本数据流
Container(对应MapReduce是Mapper/Reducer的Task进程,对应iStream是Role的Worker进程)获取输入数据,交由内部的TecWorker。
TecWorker将数据通过Dispatching机制实时转发至缓冲区。
各个TecThread以不停循环的方式,异步地从缓冲区内获取最新一批数据,驱动内部的DAG处理链,DAG上各个节点(称为Executor)负责实现各个不同的具体处理逻辑,按照彼此依赖关系顺序或并行的执行,完成对一批数据的处理。
DAG处理链
针对每一种输入数据,将总的处理流程细分为一些更小的节点,每个节点实现对应的Executor Java接口中的如下3个方法。
- init
void init(String initParam)
TecThread初始化Executor的时候执行,一个Executor只会被初始化一次。
- execute
Object[] execute(Object... inObjs) 定义了处理数据的具体逻辑,对不同输入数据反复执行该方法。
输入参数Object数组表示来自数据源或上游Executor输出的输入数据。假设该Executor配置了M个输入,则传入数组的长度也为M,其中每个元素分别表示一个输入。
返回值Object数组表示该Executor的输出数据。假设该Executor配置了N个输出,则输出数组长度也为N,其中每个元素分别表示一个输出。
- cleanup
void cleanup()
只在TecThread退出的时候执行一次。
实现各个Executor后需要配置在某个数据源的处理链上,并指定Executor的输入输出关系,通过这种输入输出依赖自动形成了DAG。某个Executor当且仅当其需要的所有输入数据都准备好之后可以执行,这同时意味着某些情形下多个不同Executor可以并行执行。
下图是Pora中的一个简化了的DAG例子。
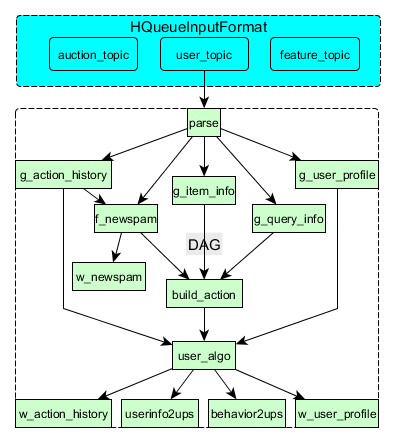
上图中几个g_开头的Executor是典型的访问存储的Executor,通常相比其它Executor慢,因而将这些Executor并行化可以明显缩短DAG总的处理耗时。
DAG中所有的Executor位于相同的进程内,所以其输入输出数据都在同一个JVM heap内,因而可以通过内存直接获取Executor需要的输入数据,不需要再经过任何序列化/反序列化和消息传递过程,既提升了处理效率也使得Executor可处理任意Object数据。
多线程并发
海量数据处理中通常需要访问存储,在这种场景下单线程处理通常总会受制于IO而无法充分利用cpu的计算能力,对此Tec支持多个TecThread并发处理,可更充分地利用cpu从而进一步加大吞吐。
每个TecThread相互独立,内部使用相同拓扑的DAG处理链,处理不同的输入数据。每批输入数据处理完后,TecThread随即从缓冲区中获取新的一批实时输入数据。获取的策略是实时小批量,即以实时性为主兼顾批处理能带来的效率提升。简单说是在不超过batch.max前提下有多少取多少,从而使得缓冲区内的数据能被最快地处理完成。这里采用小批量的方式有助于业务针对批量作优化,比如去重、聚合、批量访问存储等。
Dispatching
引入多线程后,TecWorker需要选择将数据发给哪个TecThread。目前Tec支持以下两种分发策略,两种方式各有利弊。
缺省的RoundRobin方式,好处是每个TecThread收到大体相同数量的数据,没有数据倾斜;坏处是不适合多线程并发修改相同key的业务场景。
FieldDispatching方式,好处是可以将相同key的数据交由同一个TecThread处理,避免多线程并发修改的问题;坏处是有可能因为热点数据造成数据倾斜(针对这种热点Tec会自动识别并优化处理尽可能减轻影响)。
通用数据结构
Executor设计上支持任意Object的处理,但为了尽可能提供通用实现以减轻应用开发成本,Tec提供了FieldMap的通用数据结构。
FieldMap是一个Map实现类,其数据是字段名到字段值的映射,符合大量业务场景数据建模需求。
基于FieldMap Tec可以支持FieldDispatching,确保相同字段值的FieldMap数据被相同TecThread处理。FieldMap也支持序列化/反序列化,以便存储至队列或其它介质。另外,针对FieldMap Tec还提供FieldMatcher,可用来检查FieldMap数据是否符合特定的字段值条件,从而更方便地对数据做过滤。
为了方便后续处理,Tec建议在DAG的第一个Executor中将输入数据转换为FieldMap数据,此类Executor称为InputParser。为此Tec提供了一个抽象类BaseInputParser供其它具体InputParser继承实现,BaseInputParser除定义方法接口外,还附带了实时统计qps和gap metric的功能。如果输入数据本身就是FieldMap类型,则可以直接使用FieldMapParser作为InputParser。
存储抽象
Tec原生支持HBase作为海量数据存储,并针对常用的随机查询模式进行了针对性的封装、抽象和优化,使应用可以高效率低门槛地使用HBase。
Tec首先通过抽象类BaseTable在rowkey sharding、batch访问、HTable创建等方面统一了对hbase的使用,既方便了用户又优化了读写hbase的性能。
在此基础上,Tec更进一步将常用HTable抽象为KVTable,KKVTable和KKTVTable 3种,并提供了通用实现及对应的Executor,从而使得大部分业务不需要再开发任何有关HBase读写的代码。
通用计算逻辑
以FieldMap和HBase抽象为基础,Tec提供了目前目前已知的各种FieldMap操作及HBase读写等通用Executor实现,新业务基于Tec开发时可直接复用这些已有的Executor实现,不需要再开发。
通过这些通用实现,Tec希望新业务开发时可以尽可能地复用各种通用Executor,只在业务确实有特殊逻辑时定制自己的Executor,从而用最少的开发工作实现业务需求。
下图是一个典型的实时业务场景对应的DAG处理链。

其中,parse将输入数据解析为FieldMap,getXXX基于解析结果查询若干hbase表数据,joinXXX将查到的hbase数据合并到FieldMap,modify由业务根据需要对数据进行加工,最后将结果输出回一张hbase表。
图中只有modify Executor需要业务自主实现,其它Executor都已有通用实现可以复用。
高级功能
以上是Tec的基本功能,除此之外Tec还有其它一些高级功能。
热点优化
针对FieldDispatching时可能出现的数据倾斜,Tec实现了相应的自动优化处理功能。对正常范围的数据倾斜,接收数据最多的TecThread将获得更大的缓冲区,以减轻对其它TecThread的影响;对热点数据造成的数据倾斜,Tec可以自动识别出这些热点数据并开辟专用的TecThread进行处理,既可以避免对其它TecThread造成影响,又可以允许业务通过批量去重、聚合等手段加快对热点数据的处理。
LRUKVCache
Tec对hbase等存储的抽象中还支持开启cache,这是一个write-through的LRU kv cache,在TecWorker级别缓存存储中访问最频繁的数据,供TecThread共享使用。LRUKVCache可减少对存储的读取,特别是配合FieldDispatching策略时可以显著减少对主键关联数据的查询,既减少对存储系统的压力,减轻热点数据影响,又可以加快DAG处理速度,进一步缩短延迟。
其它
此外,Tec还有子DAG、异步Executor实现、配合IStream热切换配置等高级功能,这里不再展开。
总结
Tec通过DAG实时计算框架和对存储的优化使用确保低延迟和高吞吐,通过大量的抽象和通用Executor实现大幅度减少应用开发工作量,可极大降低海量数据实时计算应用的开发成本。
正文到此结束
热门推荐









相关文章

近期评论
-
你这基本没有更新呀,最近文章显示还是2019年的文章。不符合要求哈
-
关键词:慕云博客 链接:https://www.lilun.me 描述:分享原创文字的个人博客
-
-
-
可以提供一下源码吗
-
不是商业站,鸡娃学习笔记
-
-
-
-
听他们说很厉害的样子
Loading...
![[HBLOG]公众号](http://www.liuhaihua.cn/img/qrcode_gzh.jpg)

