深入解析Bloom Filter(中)
本篇将介绍:
- d-left hashing
- d-left counting bloom filter
在上篇文章,我们介绍了Standard Bloom Filter(SBF)和Counting Bloom Filter(CBF)。简单回顾下,我们大概思路和历程是:为了解决允许false positive下的membership问题,我们设计了哈希表算法,由于它所需空间巨大,我们引入bitmap方法;因为它false positive possibility太大,我们引入了SBF,它使用多个独立的、均匀分布的哈希函数。而SBF的一个缺点是不支持删除操作,为了能够删除,我们引入了CBF,然而,CBF存在一个问题。
什么问题呢?那就是空间利用率不高。这可以通过简单的数学计算知道大概:
考察某个位置,该位置的计数器counter的值$/xi$
$P(/xi = c) /approx /binom{mk}{c} {(/frac{1}{n})}^{c}({1-/frac{1}{n}})^{mk-c} = B(km,/frac{1}{n})$
若二项分布B(n,p)里n很大,p很小时,二项分布的极限近似分布是泊松分布$P(/lambda=k) = /frac{/lambda^k}{k!}{e}^{-/lambda}$,其中$/lambda=np=/frac{km}{n}$,并结合$k = /frac{n}{m}ln2$,可以得到,counter的期望值为:
$E(/xi) = /lambda = np = ln2 /approx 0.7$
即大量的counter的值都是0,空间效率不高。
在介绍新的Bloom Filter之前,我们一起先看看什么是所谓的d-left hashing。
d-left hashing
在d-left hashing中,我们有d张哈希子表(序号分别为1,2,…d,并且假设是从左到右),每张子表都包含B个bucket,每个bucket都包含w个cell,每个cell可以存放一个元素。
为了插入一个元素x,我们:
1,首先通过一个哈希函数hf,得到x的哈希函数值value = hf(x)
2,通过value,得到d个位置(每个位置对应每张子表),表示为:
(1,$B_1$) , (2,$B_2$),… (d,$B_d$)
其中(i,$B_i$)表示第i张子表,Bucket的index为$B_i$。
那么,到底插入哪张表呢?d-left hashing选择$B_i$中负载最小(已经存放的元素最少)的位置。注意,这里说的是bucket的负载,不是子表的负载。如果有多个子表对应的位置负载都是最小,那么选择最左边(序号最小)的子表插入。
为了查找该元素,我们需要检查d个位置,wd个cell(元素)。
d-left counting bloom filter
在基于d-left hashing的CBF中,我们有d张哈希子表(序号分别为1,2,…d,并且假设是从左到右),每张子表都包含B个bucket,每个bucket都包含w个cell,每个cell可以存放一个counter和一个fingerprint。
为了插入一个元素x,我们:
1,首先通过一个哈希函数hf,得到x的哈希函数值value = hf(x)
2,通过value,得到d个位置(每个位置对应每张子表)和对应的fingerprint,表示为d个位置向量:
(1,$B_1$,$fp_1$) , (2,$B_2$,$fp_2$),… (d,$B_d$,$fp_d$)
其中位置向量(i,$B_i$,$fp_i$)表示第i张子表,Bucket的index为$B_i$,fingerprint为$fp_i$。
3,通过d-left hashing将x插入,如果插入的位置(i,$B_i$,$fp_i$)上已经有cell的fingerprint等于$fp_i$,那么只需要将它的counter++即可。
举个栗子,假设某时刻,我们有:

2张子表(d=2),每张子表有6个bucket(B=6),每个bucket包括3个cell(w=3),每个cell可以存放一个counter(4位表示,最大值为16)和fingerprint(6位表示)。
假如我们要插入元素x,我们对它进行hash,得到两个位置向量:
(1, 1, 010100)和(2, 2, 010101)
$d_1$子表中index为1的bucket的负载,要小于$d_2$子表中index为2的bucket的负载,因此,我们选择插入$d_1$中,如下:
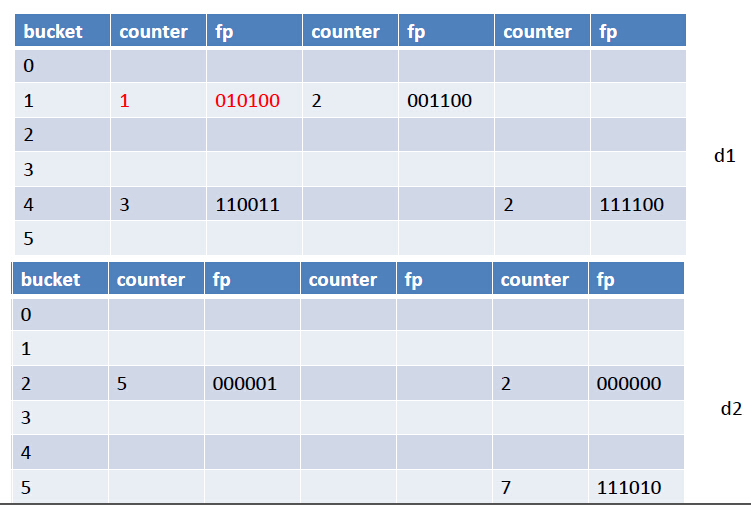
如果得到的位置向量分别是(1, 1, 001100)和(2, 2, 010101)呢?那么,还是插入到$d_1$中index为1的bucket中,但是只需要将第二个cell里的counter++即可,如下图:
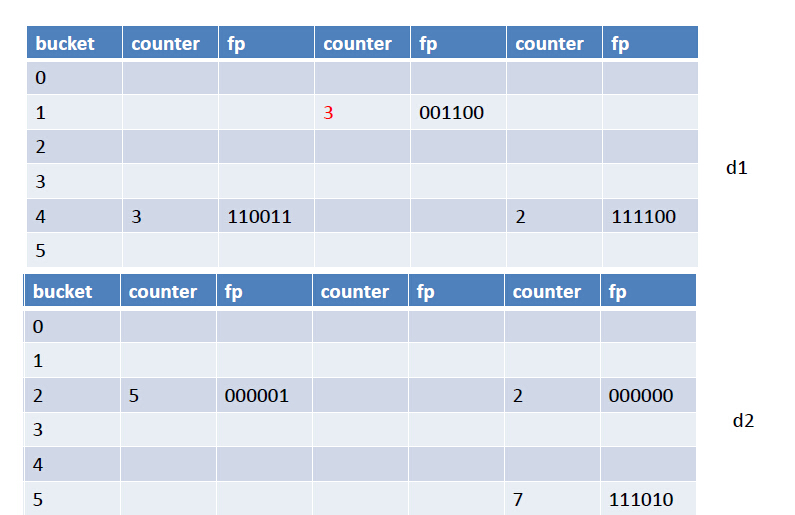
看起来很完美,但是这种方案在删除时会有问题。比如说,还是刚才的例子,我们欲插入x和y。分别得到x和y的位置向量们:
x: (1, 1, 010100)和(2, 2, 010101)
y: (1, 1, 010100)和(2, 4, 111111)
根据d-left hashing,x被插入到$d_1$中index为1的bucket中;y被插入到$d_2$中index为4的bucket中。好,这没问题。如果现在要删除y呢?我们需要检查两个位置,$d_1$中的index为1的bucket,以及$d_2$中index为4的bucket,要删哪个?fp都是010100啊。这就出现问题。
什么时候会出现这种问题?当以下条件满足时:
1,两个元素的有公共【重合】的位置向量。位置向量相同,表示同一个子表,同一个bucket,以及相同的fingerprint。
2,其中一个元素被插入了公共位置向量对应的位置,另外一个元素没有。
3,欲删除未使用公共位置向量的元素(比如说上例中的y)
为了解决这个问题,作者做了两点改进:
I 引入d轮随机置换。
置换,即一一映射。假设置换为P,输入为a和b,那么将满足:
如果a = b,那么P(a) = P(b)
如果a != b ,那么P(a) != P(b)
以及它们的逆否命题
如果P(a) != P(b),那么a != b
如果P(a) = P(b),那么a = b
为了插入x,我们首先通过一个哈希函数hf,计算它的哈希函数值value = hf(x)。然后,我们对value进行d轮随机置换,得到d个位置向量:
$P_1(value) = (1, B_1, fp_1)$
$P_2(value) = (2, B_2, fp_2)$
……
$P_d(value) = (d, B_d, fp_d)$
这里面有一个小问题:如果要插入的元素x和y不等,那么它们的置换可能相等吗?当然可能。因为x和y虽然不等,但是它们的hash value可能相等,这样它们的置换结果即位置向量可能相同。
别忘了,我们是对x和y的hash value进行置换,不是对x和y进行置换。
网上流传很广的 这篇 文章的解释是错误的,小心!!!
II 插入修正
当得到d个位置向量后,和上面介绍的过程稍微不同:我们首先需要根据d个位置向量,从第1个子表开始,对每个子表$d_i$,去对应的位置$B_i$处查找是否有cell中的fp等于$fp_i$,如果有,我们把相应的counter++,插入动作完成,不用再继续检查后续子表了。
否则,当所有d个子表都没有对应的$fp_i$时,我们运用d-left hashing,插入x。
综合运用这两点,我们知道上面所说的删除时的问题已经不存在了。
假如欲插入x和y,分别对它们的hash value进行d轮(这里d=2)随机置换后,有没有可能得到如下的位置向量?
x: (1, 1, 010100)和(2, 2, 010101)
y: (1, 1, 010100)和(2, 4, 010111)
不可能。
注意到,x和y的第一个位置向量(对应第一张子表)完全相同(bucket index相同,fp也相同),也就是
$P_1(hf(x)) = P_1(hf(y))$
那么可以推出hf(x) = hf(y),也就是x和y的哈希函数值相等,那么对于任何的i都有$P_i(hf(x)) = P_i(hf(y))$。
因此:
如果hf(x) = hf(y),那么$P_i(hf(x)) /eq P_i(hf(y))$ (i=1,2,3…d),假如先插入x后插入y。插入y的时候,会更新counter。后续删除x或者y都不存在上述问题。
如果hf(x) != hf(y),那么那么$P_i(hf(x)) /neq P_i(hf(y))$ (i=1,2,3…d),那么x和y没有公共的位置向量。后续删除x或者y都不存在上述问题。
附录
如何随机置换
作者提供了一个简单的函数:
$P_i(value) = (a * value ) mod 2^B$
其中value的范围是[0, $2^B$],a是随机的一个奇数。
数学分析
首先,如果z是false positive,那么它的哈希函数值会和集合S中的某个元素的哈希函数值相等。也就是
hf(z) = hf(e) 其中 $e/in S$
这是因为,如果z是false positive,那么
$p_i(hf(z)) = p_i(hf(e))$
根据置换的性质,可得hf(z) = hf(e)
因此,false positive possibility为
$P = 1 - (1 - /frac{1}{B}*/frac{1}{2^r})^m$
根据伯努利公式,当x很小时,$(1+x)^a /approx 1 + ax$,所以
$P /approx 1 - (1 - m * /frac{1}{B} * /frac{1}{2^r}) /approx /frac{m}{B*2^r}$
那么d-left CBF的false positive和空间利用情况如何?我们下面简单分析一下:
比较嘛,肯定是相同的空间利用,比较谁的false positive possibility小;相同的false positive possibility下,谁所需空间少。
在CBF中,假设counter需要c位(上次我们分析过,c取4足矣),那么所需的空间是cn。结合$k = /frac{n}{m}ln2$,false positive possibility大约为$(0.6185)^{/frac{n}{m}}$。
在d-left CBF中,我们选择d=4,B=$/frac{m}{24}$,w=8(平均负载为6,这样$4 * /frac{m}{24} * 6 = m$),counter占用2位,fingerprint占用r位。那么它的空间占用为
$4 * /frac{m}{24} * 8 * (2+r) = /frac{4m(r+2)}{3}$
而false positive possibility的大概为 $/frac{m}{B*2^r} = 24 * /frac{1}{2^r}$ (别忘了,B=$/frac{m}{24}$ )
通过计算不难发现,当空间占用相等时,d-left CBF的false positive possibility是CBF的百分之一;当false positive possibility相等时,d-left CBF所需空间是CBF的一半。
感谢
特别感谢 汪立 大神参与讨论。
正文到此结束
热门推荐










相关文章

近期评论
-
你这基本没有更新呀,最近文章显示还是2019年的文章。不符合要求哈
-
关键词:慕云博客 链接:https://www.lilun.me 描述:分享原创文字的个人博客
-
-
-
可以提供一下源码吗
-
不是商业站,鸡娃学习笔记
-
-
-
-
听他们说很厉害的样子
Loading...
![[HBLOG]公众号](http://www.liuhaihua.cn/img/qrcode_gzh.jpg)

