PyOdps DataFrame来临,数据分析从未如此简单!
PyOdps正式发布 DataFrame框架 (此处应掌声经久不息),有了它,就像卷福有了花生,比翼双飞,哦不,如虎添翼。
快过年了,大家一定没心情看长篇大论的分析文章。作为介绍PyOdps DataFrame的开篇文章,我只说说其用起来爽的地方。其余的部分,从使用、问题到实现原理,我会分文章细说。
如果你不知道什么是 ODPS ,ODPS是阿里云旗下的大数据计算服务。如果不知道是DataFrame什么,它是存在于pandas和R里的数据结构,你可以把它当做是表结构。如果想快速浏览PyOdps DataFrame能做什么,可以看我们的 快速开始文档 。
让我们开始吧。
强类型支持
In [4]: from odps.df import DataFrame In [5]: iris = DataFrame(o.get_table('pyodps_iris')) In [6]: iris.dtypes Out[6]: odps.Schema { sepallength float64 sepalwidth float64 petallength float64 petalwidth float64 name string } In [7]: iris.field_not_exist --------------------------------------------------------------------------- AttributeError Traceback (most recent call last) in () ----> 1 iris.field_not_exist /Users/chine/Workspace/pyodps/odps/df/expr/expressions.pyc in __getattr__(self, attr) 510 return self[attr] 511 --> 512 raise e 513 514 def output_type(self): AttributeError: 'DataFrame' object has no attribute 'field_not_exist' 如果取存在的字段,自然是没问题啦。
In [11]: iris.sepalwidth.head(5) |==========================================| 1 / 1 (100.00%) 0s Out[11]: sepalwidth 0 3.5 1 3.0 2 3.2 3 3.1 4 3.6
有些方法,比如说取平均数,非数字肯定是不能调用的咯。
In [12]: iris['name'].mean() --------------------------------------------------------------------------- AttributeError Traceback (most recent call last) in () ----> 1 iris['name'].mean() /Users/chine/Workspace/pyodps/odps/df/expr/expressions.pyc in __getattribute__(self, attr) 171 if new_attr in self._get_attr('_args'): 172 return self._get_arg(new_attr) --> 173 raise e 174 175 def _defunc(self, field): AttributeError: 'Column' object has no attribute 'mean' 数字类型的字段则可以调用。
In [10]: iris.sepalwidth.mean() |==========================================| 1 / 1 (100.00%) 27s 3.0540000000000007
操作数据如此简单
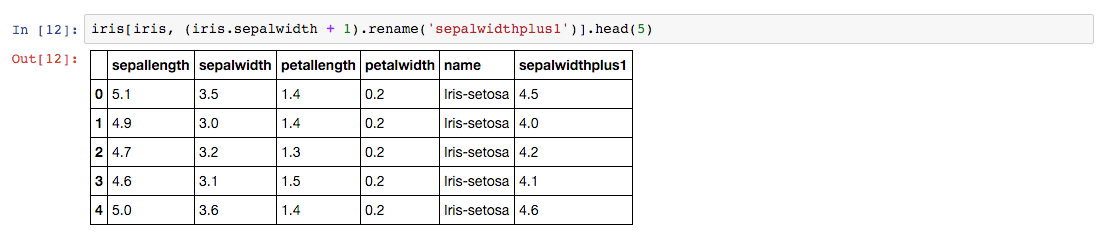
我们常常需要select一个表字段,但是只是不需要一个字段,却需要写一堆SQL。在DataFrame API里,调用 exclude 方法就行了。
In [13]: iris.exclude('name').head(5) |==========================================| 1 / 1 (100.00%) 0s Out[13]: sepallength sepalwidth petallength petalwidth 0 5.1 3.5 1.4 0.2 1 4.9 3.0 1.4 0.2 2 4.7 3.2 1.3 0.2 3 4.6 3.1 1.5 0.2 4 5.0 3.6 1.4 0.2 使用DataFrame写出来的代码,天然有Python的特点,清晰易懂。某些快捷API,能使得操作更加简单。
比如我们要取 name 的个数从大到小前10的值分别是多少。
In [16]: iris.groupby('name').agg(count=iris.name.count()).sort('count', ascending=False)[:10] |==========================================| 1 / 1 (100.00%) 37s Out[16]: name count 0 Iris-virginica 50 1 Iris-versicolor 50 2 Iris-setosa 50 直接使用 value_counts 来得更快。
In [17]: iris['name'].value_counts()[:10] |==========================================| 1 / 1 (100.00%) 34s Out[17]: name count 0 Iris-virginica 50 1 Iris-versicolor 50 2 Iris-setosa 50
很多时候,写一个SQL,我们需要检查中间结果的执行,就显得很麻烦,我们常常需要选取中间的SQL来执行,在DataFrame的世界,中间结果赋值一个变量就行了,这都不是事儿。
计算的过程和结果展示
在DataFrame的执行过程中,我们在终端里和IPython notebook里,都会有进度条显示任务的完成情况。结果的输出也会有更好的格式化展现,在IPython notebook里会以HTML表格的形式展现。
绘图集成
DataFrame的计算结果能直接调用plot方法来制作图表,不过绘图需要安装 pandas 和 matplotlib 。
In [21]: iris.plot() |==========================================| 1 / 1 (100.00%) 0s Out[21]: <matplotlib.axes._subplots.AxesSubplot at 0x10feab610>
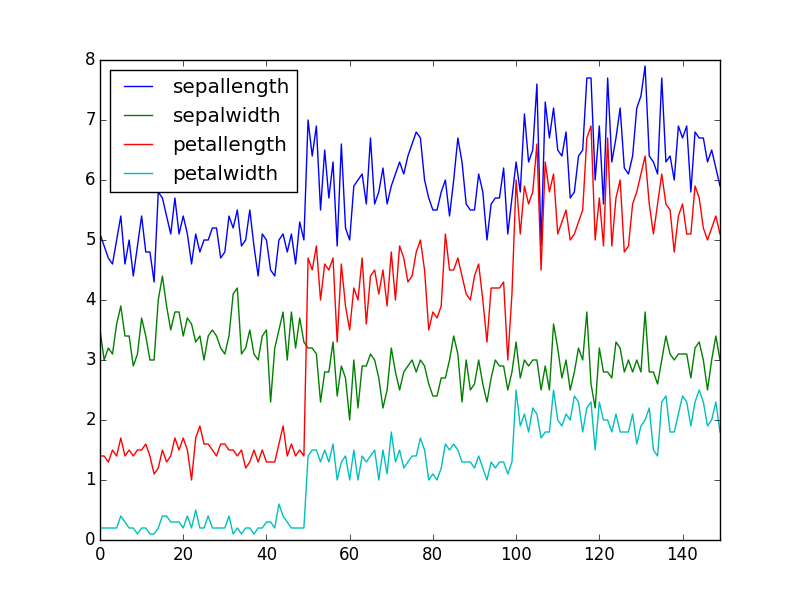
导出数据再用excel画图,这事儿……咳咳,未来我们还会提供更好的可视化展现,比如提供交互式的图表。
自定义函数和Lambda表达式
DataFrame支持map方法,想对一个字段调用自定义函数非常方便。
In [30]: GLOBAL_VAR = 3.2 In [31]: def myfunc(x): if x < GLOBAL_VAR: return 0 else: return 1 In [32]: iris['sepalwidth', iris.sepalwidth.map(myfunc).rename('sepalwidth2')].head(5) |==========================================| 1 / 1 (100.00%) 18s Out[32]: sepalwidth sepalwidth2 0 3.5 1 1 3.0 0 2 3.2 1 3 3.1 0 4 3.6 1 可惜apply和聚合的自定义函数,暂时还不支持,期待吧!
延迟执行
DataFrame API的所有操作并不会立即执行,除非用户显式调用 execute 方法或者一些立即执行的方法。在交互式界面下,打印或者repr对象的时候,内部也会调用 execute 方法,方便用户使用。
执行优化
DataFrame框架在执行前会对整个查询进行优化,比如连续的projection合并。当用户查看原始表(或者选取某个分区)时,会使用tunnel来获取结果。
PyOdps DataFrame的下一步发展
好了,说了这么多,聊一聊我们DataFrame接下来要做的事情,首先,我们会实现多计算后端,包括pandas,当数据量比较小的时候,我们可以使用本地计算,而不需要等待ODPS的调度;其次,DataFrame框架和我们的机器学习部分会有更多的集成,从数据分析,到算法,一气呵成。
PyOdps非常年轻,才短短几个月的时间。我们的整个项目,在GitHub上开源。我个人非常希望大家能参与到开源的建设中来,能提个建议也是极好的。所以,我会写文章详述我们PyOdps的实现原理,希望大家一起把ODPS建设得更好。
github: https://github.com/aliyun/aliyun-odps-python-sdk
文档: http://pyodps.readthedocs.org/zh_CN/latest/
正文到此结束
热门推荐










相关文章

近期评论
-
你这基本没有更新呀,最近文章显示还是2019年的文章。不符合要求哈
-
关键词:慕云博客 链接:https://www.lilun.me 描述:分享原创文字的个人博客
-
-
-
可以提供一下源码吗
-
不是商业站,鸡娃学习笔记
-
-
-
-
听他们说很厉害的样子
Loading...
![[HBLOG]公众号](http://www.liuhaihua.cn/img/qrcode_gzh.jpg)

