Cadvisor源码分析_part2
storage模块从逻辑上讲相对比较基本,但同时又是很重要的一块,因为上层搜集到的数据,如果想要分析,首先需要存储起来,而存储的操作都要通过这一层来实现进一步的处理。
Storage Component分析
storage部分主要有两个功能
- 把从宿主机上搜集出来的数据存储在内存中,每隔一段时间,还需要把内存中的数据更新一次。
- 把数据推送到 storage backend中,就像前面分析的那样,比如把数据发送到elastic search或者influxdb的backend中。
先大致分析下涉及到的package: ./cache ./storage ./info 几个package。
./info
./info 中的内容比较直接,是各种metrics的实际struct构成,大致看下其中的文件,可以了解到cadvisor从 machine 与 container 两个角度对资源进行描述,目前使用的资源描述结构都是v1版本,这里仅仅是说明一下,用到的时候再针对性地具体查看。
./storage
./storage package通过提供storagedriver接口(定义在storage.go中)对外暴露服务,其中的几个函数定义的比较直接:AddStats 将信息添加到对应的后端中;Close 停止存储后端的操作,不同后端的具体实现方式可能有区别;New 生成对应的StorageDriver,具体不同的实现分别在./storage下的几个不同的文件夹中,目前有bigquery,elasticsearch,indluxdb,redis几种backend实现。还可以直接将结果输出到标准输出(默认输出)或者将结果发送个某个daemon(通过host:port生成net.Conn之后把数据写进去),具体使用的时候,可以对应着某一个实现进行进一步分析。
type StorageDriver interface { AddStats(ref info.ContainerReference, stats *info.ContainerStats) error // Close will clear the state of the storage driver. The elements // stored in the underlying storage may or may not be deleted depending // on the implementation of the storage driver. Close() error}storage部分的启动参数被放在common_flags.go文件中,可以具体查看,每一部分的backend的相关参启动参数被放在每一部分具体实现的package中,相关参数比较多也比较零碎,可以在有需要的时候针对性地查看。
./cache
这部分做了许多重要操作,最上层是cache接口:
type Cache interface { // 将ContainerStats通过ContainerReference更新到对应的存储位置中 AddStats(ref info.ContainerReference, stats *info.ContainerStats) error // 通过containerName找到指定的container并且从cache中移除其信息 RemoveContainer(containerName string) error // 读取出最近的 stats 返回结果是一个ContainerStats数组 numStats表示返回的stats的个数 若stats<0 返回全部 RecentStats(containerName string, numStats int) ([]*info.ContainerStats, error) // 清除缓存中的数据 Close() error}有必要大致浏览下containerstats即cadvisor搜集回来的到底是容器的哪些信息,具体每个指标的含义这里不作为重点介绍:
type ContainerStats struct { // 这个stats被搜集到的时间点 Timestamp time.Time `json:"timestamp"` Cpu CpuStats `json:"cpu,omitempty"` DiskIo DiskIoStats `json:"diskio,omitempty"` Memory MemoryStats `json:"memory,omitempty"` Network NetworkStats `json:"network,omitempty"` // 文件系统的数据 Filesystem []FsStats `json:"filesystem,omitempty"` // Task load 的状态信息 TaskStats LoadStats `json:"task_stats,omitempty"` //自定义的一些指标 CustomMetrics map[string][]MetricVal `json:"custom_metrics,omitempty"`}再看下AddStats中的第一个参数,containerReference的信息,相当于是一个容器的元信息,在map中扮演一个index的角色,通过这个信息来定位容器:
type ContainerReference struct { // 容器的绝对路径 在机器上这个路径应该是唯一的 Name string `json:"name"` // 容器的别名 在同一个namespace下面这个路径应该是唯一的 Aliases []string `json:"aliases,omitempty"` // 这个容器所在的namespace的名称 Namespace string `json:"namespace,omitempty"`}通过以上的分析,其实cache这块的结构比比较清晰了,输入是什么,输出是什么,具体进行了哪些操作。下面是这部分的结构图:
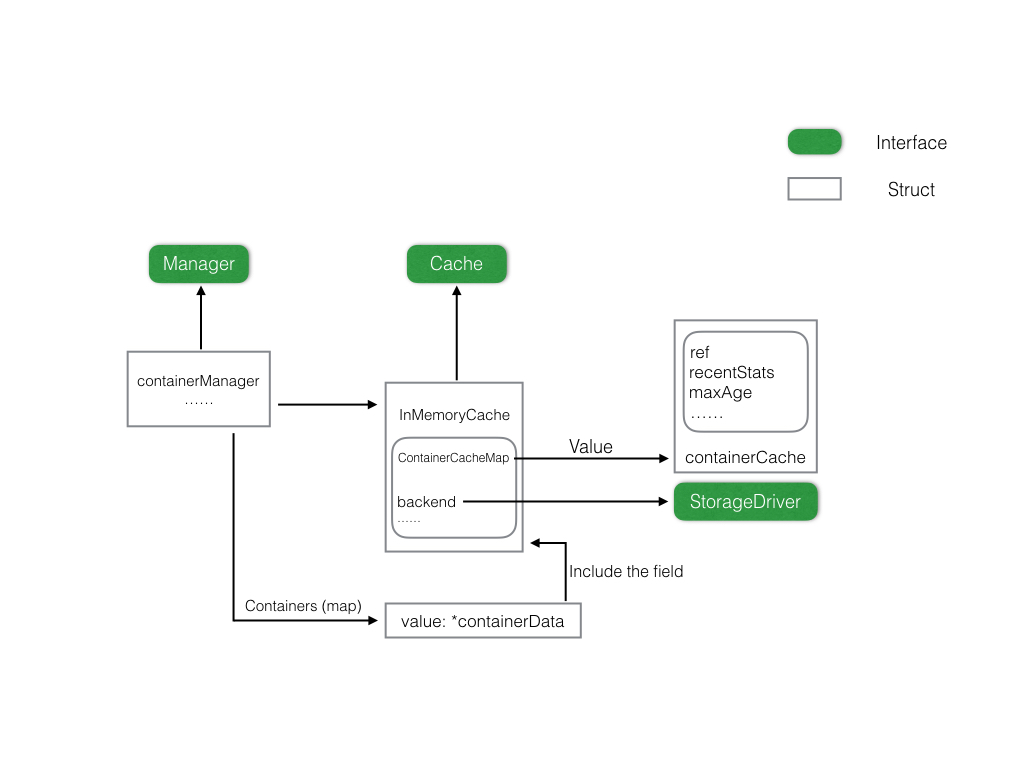
inMemoryCache对cache interface的具体实现
在memory.go文件中,有两个struct即 inMemoryCache 以及 containerCache 其中。
inMemoryCache是上面所介绍的Cache接口的一个具体实现,其中包含了一个 containerCacheMap map[string]*containerCache 字段,可以看到,这个map的value值是文件中定义的另一个结构 containerCache 。这个结构用于执行具体的存储操作,同时也是内存中存放数据的最根本的地方(实质上是一个interface{}组成的slice,具体在utils中实现即utils.TimedStore),就是上图中的 recentStats *utils.TimedStore 字段。
inMemoryCache 中还有一个字段是 backend storage.StorageDriver 这个是存储后端的实际内容,表示要将什么样的数据放到存储后端,比如influxdb,就像前面所介绍的那样。
下面看下inMemoryCache所实现的AddStats操作,逻辑比较简单:
- 新生成一个containerCache 用于将stats数据存放在内存中,每个containerCache还包含一个有效期,后面会用到这个有效期。根据传进来的ref参数找到容器的名字,在
containerCacheMap中进行检索 - 若不存在,则生成新的containercache对象
- 执行backend的AddStats操作,将stats数据推送到后端数据库
- 执行containercache的AddStats操作,将stats数据存储在本地内存中
在代码实现上,检索containercache是否存在并生成新对象的操作是用goroutine并行处理的。
再进一步,看下containerCache的AddStats操作:
- 首先考虑当前元素加入进来是否超过了buffer限制的最大长度(生成buffer的时候里面带一个maxitem的字段,默认的是-1即没有限制)若是添加了限制,就会循环使用内存资源,这样会覆盖掉旧的数据,占用的空间会减少。
- append操作,把新得到的数据放在slice后面。
- 对slice进行排序,排序的规则是按时间先后排序,最近发生的会放在最前面。
- 进行截取操作,更新slice去掉过期数据。
这里细说下更新过期数据的操作,比如当前时间是t,数据过期时间是d,由于slice中存储的是这个容器在某个时间序列上的数据,在这个序列中,如果数据存入的时间是在t-d之前,那么这些数据都属于过期数据。首先通过sort.Search操作找到临界点之后的第一个index,之后进行截取操作 self.buffer = self.buffer[index:] 这一部分代码相对灵活一些,但是也不难理解。
在看下inMemoryCache的其他操作:
RecentStats主要是返回在某段时间之内,某个容器的stats信息,主要实现思路就是根据起止时间确定sclice中的startindex以及endindex之后将数据返回。
Removecontainer主要是从containerCacheMap中移除存储某个容器的slice。
Close操作会将containerCacheMap中的内容清空,即清空了当前存储在内存中的数据。
contanerData字段
查看源码,可以看到manager中有一个containers的字段 containers: make(map[namespacedContainerName]*containerData) ,这是一个map,其中的value值为指向containerData的指针。
根据map的定义也可以看出来,这个结构的主要功能是提供对container的实际操作,也就是被cadvisor识别过来的container都需要在这里注册一下,当然其中还包含相关的handler等等,注意每个containerData中都持有一个对manager的InMemoryCache的指针,这个InMemoryCache实际上是被所有的containerData实例共享的。具体对于InMemoryCache中内容的实际操作也是通过一个个的containerData实例进行的。
containers这个字段的key值也是namespacedContainerName,其value值是*containerData,这个结构的实际作用是对容器进行实际的处理和信息搜集、存储等操作,可以看到其中包含的各种handler,功能上来讲,应该是属于manager的范围,由于这个结构实际上也比较重要,这里就是提一下,具体的相关细节在manager相关的部分进行介绍。
总结
根据前面的架构图可以看到这一部分各个组件的具体关系,在part1中也提到,在生成containerManager的时候要把inMemoryCache对象传入进去,之后存储manager就会通过inMemoryCache来对存储相关的操作进行进一步的控制。
参考资料
关于选择influxdb还是elasticsearch?
https://discuss.elastic.co/t/elk-vs-grafana-influxdb/1686/15
正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](http://www.liuhaihua.cn/img/qrcode_gzh.jpg)

