微博推荐静态数据存储方案: lushan
- 数据的更新频次较低, 如一天或者一周更新一次
- 数据更新时采用全量替换的方式
- 数据规模较大
- 数据内容符合key-value的形式(这条非必需)
以下语录出自lushan创始人@taohui同学
"当时做错过的微博有几种推荐方法推荐的结果,我希望能一次获取到。当时需要部署多个测试服务,以对比测试不同算法的效果,我不想每个算法都搭建一个服务。考虑到这是一个比较基础的服务,为了让自己以后少一些维护,所以写了这样一个可以挂载多个库,只需要把新的数据放到对应目录下即可。并且采用memcached协议,可以直接采用memcached客户端的服务"
可以看出, lushan的诞生也是脱胎于具体需求, 之后才抽象为一个具有通用性的离线数据存储server, 随着业务的发展, 陆续接入了亲密度, 关注关系等数据的存储.目前, 我们在两个机房各部署了一套lushan集群, 每个集群有6台服务器, 承载的访问量每天有12亿左右, 加载的数据包括:错过的微博,二度关系,兴趣协同,粉丝相似度,亲密度,用户分组,关注关系,用户特征等. 存储的数据量总共有2T多, 下面这张图展示了一台线上lushan服务器加载的数据及其在某个时刻的状态

接下来, 我们就对整个lushan的实现机制进行一次一探到底
Table of Contents
- 1 lushan特点概述
- 2 整体架构图
- 3 通信模型部分
- 3.1 网络通信模型比较
- 3.2 libevent
- 3.3 lushan
- 4 db部分
- 4.1 索引结构
- 4.2 db结构(hdict结构体)
- 4.3 hdb结构
- 4.4 加载索引文件和数据文件
- 4.5 替换db
- 4.6 关闭db
- 4.7 查找数据
- 5 监听程序对lushan server的控制
- 5.1 总体
- 5.2 init
- 5.3 start
- 5.4 load
- 6 压力测试
- 7 展望
1 lushan特点概述
lushan主要用来存储推荐引擎的离线静态数据. 它可以在一个实例(端口)上挂载多个库, 在挂库时不用重启实例, 可以实现动态挂库的特性. 通信模型是基于libevent的事件驱动机制, 实现了IO多路复用, 解决了c10k问题. 在协议上支持mc协议, 客户端有一个mc实例, 即可以与lushan进行交互. 本文主要从通信模型部分与db部分两个方面来剖析lushan的运行机制
2 整体架构图
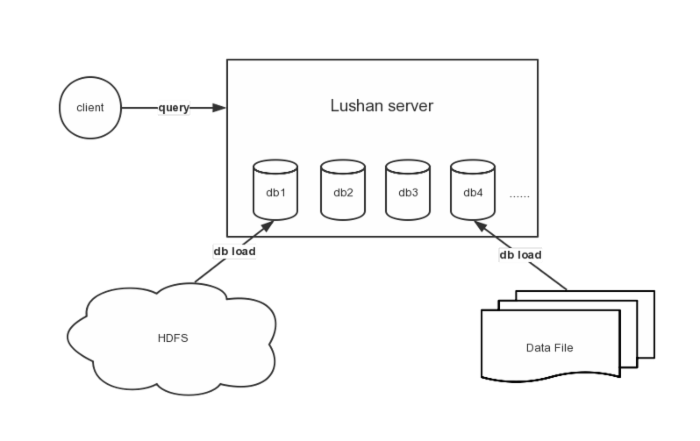
下图展示lushan如何与外界进行交互, 由client, lushan server, source data(可以是HDFS, 也可以是Data File)三部分组成, 给出了查询和挂库的示例
3 通信模型部分
3.1 网络通信模型比较
基本的socket编程是阻塞/同步的, 每个操作除非已经完成或者出错才会返回, 这样对于每一个请求, 要使用一个线程或者单独的进程去处理, 系统资源没法支撑大量的请求(所谓c10k problem), 例如内存:默认情况下每个线程需要占用2~8M的栈空间.
posix定义了可以使用异步的select系统调用, 但是因为其采用了轮询的方式来判断某个fd是否变成active, 效率不高[O(n)], 连接数一多, 也还是撑不住.
于是各系统分别提出了基于异步/callback的系统调用, 例如Linux的epoll, BSD的kqueue, Windows的IOCP.由于在内核层面做了支持, 所以可以用O(1)的效率查找到active的fd.
基本上, libevent就是对这些高效IO的封装, 提供统一的API, 简化开发.
3.2 libevent
lushan的通信模型是基于libevent这个开源的事件驱动网络库的, 因此能进行高效的通信服务. 这一小节先介绍libevent的基本原理, 在此基础上才能更好的理解整个lushan的通信流程.
为了实际处理每个请求, libevent库提供一种事件机制, 它作为底层网络后端的包装器.事件系统让连接添加处理函数变得非常简便, 同时降低了底层I/O复杂性, 这是libevent系统的核心.
创建libevent服务器的基本方法是, 注册当发生某一操作(比如接受来自客户端的连接)时应该执行的函数, 然后调用主事件循环event_dispatch().
执行过程的控制现在由libevent系统处理.
注册事件和将调用的函数之后, 事件系统开始自治.
在应用程序运行时, 可以在事件队列中添加(注册)或删除(取消注册)事件.
事件注册非常方便, 可以通过它添加新事件以处理新打开的连接, 从而构建灵活的网络处理系统.
结构体event和event_base是libevent的两个核心数据结构, 前者代表一个事件对象, 后者代表整个事件处理框架.
libevent通过event对象将将IO事件, 信号事件, 定时器事件进行封装, 从而统一处理, 这也是libevent的精妙所在.
libevent主循环函数不断检测注册事件, 如果有事件发生, 则将其放入就绪链表, 并调用事件的回调函数, 完成业务逻辑处理
libevent支持的事件
IO事件: EV_READ EV_WRITE 定时事件: EV_TIMEOUT 信号事件: EV_SIGNAL 辅助选项: EV_PERSIST 表明这是一个永久事件
libevent的关键函数
event_set()创建新的事件结构 event_add()在事件队列中添加事件 event_dispatch()启动事件队列系统
绑定到event的回调函数原型
typedef void(* event_callback_fn)(evutil_socket_t sockfd, short event_type, void *arg)
3.3 lushan
lushan在启动时第一步就是进行初始化, 包括配置信息的初始化, 统计信息的初始化, freeconns的初始化.
配置信息是settings这个结构体, 通过对命令行参数的解析完成(命令行参数又来自于配置文件)结构体的填充. 该结构体主要存储ip, 端口, 线程数, 最大连接数, 超时时间等属性, 对应于lushan server这个维度

统计信息是stats这个结构体, 该结构体的各项初始化时都赋值为0或NULL. 该结构体主要存储当前连接数, 查询总数, 查询命中/未命中数, 启动时间等属性, 对应于db这个维度

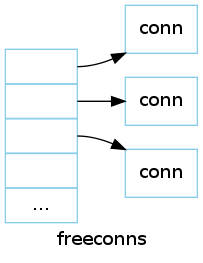
freeconns是一个初始大小为200的动态数组, 它用来保存已经free的conn, 这样在以后需要conn的时候不用重新新建一个conn, 从该数组中取一个即可, 节省了新建conn带来的开销. 数组中的元素是一个指向conn的指针
完成基本属性的初始化后, 就开始建立socket连接, 得到一个监听sfd. 该过程通过标准socket的socket(), bind(), listen()函数完成, 注意在这里并没有进行accept.
创建完socket连接后, 进行REQ队列和RSP队列的初始化. 这两个队列的数据结构一样, 是一个有头指针和尾指针的单向链表, 各包括一个队列锁和条件变量, 条件变量用来进行线程间通讯. 这里REQ队列弹出元素是阻塞式的, RSP队列弹出元素是非阻塞式的


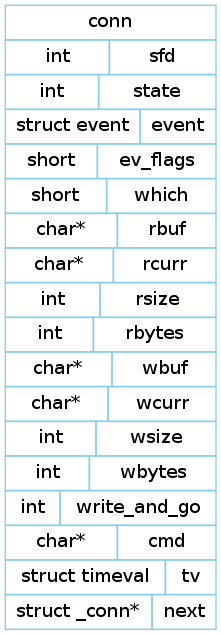
可以看到, REQ/RSP队列里存储的是一个个指向conn的指针, conn的结构体如下图所示, 它存储了conn当前的状态, 还有关键是存储了一个event结构体, 这样每个conn就对应一个事件变量, 用来监听发生在fd或者POSIX信号量上的事件. 同时还存储了一块读缓冲区和写缓冲区.
完成请求/响应队列的初始化后, 接着初始化一个管道, 管道的两端一端用来接收fd, 另一端用来发送fd, 它们启到信号通知的作用, 这个过程会在后面有所反映.
继续初始化hdb, 同时通过对lushan.init文件的解析, 加载hdb_path目录下的数据, 完成对数据库的初始化加载
同时新建一个hdb_mgr线程, 用来处理hdb的close_list里的数据
接下来再新建num_threads个worker线程(配置文件中默认是4个), 这里就是传说中的工作线程进入worker函数来一探究竟. 该函数的主体部分是一个无限循环, 做了下面几件事:
- 阻塞式的从REQ队列取conn
- 处理conn里的各种cmd, 比方说有stats, open, close, randomkey, info, get等都在这里.
处理时将conn相应的wbuff填充, wbuff是用来回显给客户端用的 - 将填充好后的conn塞入RSP队列
- 往管道的notify_send_fd端写一个字符的内容, 启一个信号的作用, 用来进行事件通知, (通知RSP队列取conn)
再写前后要进行一个加解锁的操作
接下来进入libevent的部分, 从这里开始将lushan作为一个server启动, 进行client的监听, 对相应的事件作出响应.
首先初始化event_init, 然后event_set创建一个通知事件, 该通知事件的回调函数是notify_handler, 当有读事件时触发, 在管道读时进行响应.
接着将该通知事件注册到event_base上, 并添加到事件队列中.
说一下notify_handler这个回调函数, 它做了下面几件事:
- 读notify_receive_fd, 起到通过管道进行事件响应的作用(这里如果读到的不是1个字符的内容, 说明读有问题)
- 非阻塞的从RSP队列里取conn
- 将取出的conn交给drive_machine函数处理
drive_machine其实就是一个状态机, 主要进行状态转换的功能, 对conn的不同状态作出不同的处理(lushan有4个状态, mc有好多个)
- 当conn处于conn_listening状态时
在这里才真正的进行accept, 得到一个sfd后设置为O_NONBLOCK, 接着调用conn_new - 当conn处于conn_read状态时
通过调用try_read_command和try_read_network, 来处理conn里rbuff留存的数据, 能处理命令的直接处理(如quit, stop, version), 不能处理命令赋值给c->cmd后, 将conn塞给REQ队列, 之后调用update_event更新事件为读事件 - 当conn处于conn_write状态时
调用系统函数write, 真正在客户端显示结果就在这一步
当write出现EAGAIN或EWOULDBLOCK错误时, 意味着当前没有数据可写, 需要调用update_event更新事件为写事件
这一步完成后设置conn的状态为conn_closing - 当conn处于conn_closing状态时
直接调用conn_close函数, 这里并不真正释放conn, 而只是把指向conn的指针放到freeconns数组里, 当需要新的conn时, 先从freeconns数组里取, 这样避免了每次新建conn时都要进行内存分配以及相应释放时的开销
对状态机里用到的event_handler和conn_new两个函数做一下说明
event_handler, 另一个回调函数, 它的主要作用就是当有事件发生时, 就调用drive_machine处理相应的conn和notify_handler回调函数不同的是, 它的conn是在事件注册时通过参数传递得到的, 而notfiy_handler的conn是从RSP队列里得到的
conn_new函数, 顾名思义, 就是新建conn, 如果freeconns数组里有conn, 则直接从里面取一个使用, 没有的话则需要重新分配一块内存来生成. 在这个函数里还有比较重要的一个功能就是创建并注册读写事件, 通过回调函数event_handler来进行响应.
整个lushan的通信流程可以参考下面的大图…
4 db部分
一个lushan实例(端口)可以加载多个db, 而每个db又由idx索引文件和dat数据文件共同组成. 本节先介绍有关db的一些数据结构, 接着通过介绍加载db, 替换db等操作来理解lushan是怎么作为一个db server而发挥作用的
4.1 索引结构

如图所示, 索引由一个64位的整型key和64位的整型pos组成. 其中key就是key-value结构中需要查询的key, 而pos则包含两部分信息, 它的前40位表示value在dat文件中的偏离值off, 后20位表示value的长度length, 通过off和length来共同定位dat文件中的value. 该索引结构也决定了lushan存储数据的特点, 即一条记录的索引只需16字节, 而它的key是必须是整型, 同时value的长度最多为2^20=1048576(1M)
4.2 db结构(hdict结构体)
一个db由idx索引文件和dat数据文件共同组成, 它的结构体定义如下
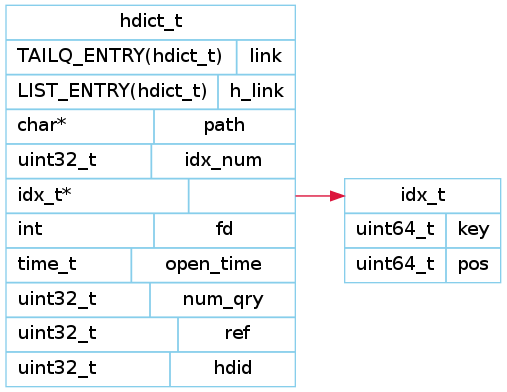
从该结构体可以看出, 每个db实际上是一个由双端链表组成的队列(TAIL QUEUE). 它包括db目录(path), 索引数(idx_num), 索引数组(idx), dat文件的文件描述符(fd), 打开时间(open_time), 查询次数(num_qry), 该db引用数(ref), db编号(hdid)等属性信息. 在这里有两个地方需要注意一下, 第一就是db实际上是一个队列, 另一个就是ref(引用计数)这个值, 它们保证了在换库时两个库都是可用的状态, 并且通过对引用计数的使用来减少了锁的使用
4.3 hdb结构
hdb实际上是整个lushan存储的结构, 它包含了所有的db, 它的结构体如下定义

hdb有一个open_list链表和一个close_list链表, 分别存储已经打开的db和已经关闭的db, 当已经关闭的db中的ref为0时, 才去释放该db, 如果ref不为0, 则说明其还在使用中, 因此不能释放, 来确保在库切换过程中, 同时保持两个库都可用的状态. 同时hdb保存一个有1024个元素的htab数组, 用来存放每个db的队头元素
4.4 加载索引文件和数据文件
该过程其实就是初始化hdict结构体, 首先为hdict结构体分配一块内存, 接着根据外部参数path来找到索引文件idx, 在内存中开辟一块区域将索引文件的所有内容均加载进去(通过fread函数). 完成idx索引文件的加载后, 接着打开dat数据文件, 并将其文件描述符fd存在hdict结构体中
4.5 替换db
首先加载索引文件和数据文件, 完成hdict的初始化. 指定一个db号, 接着遍历open_list链表里的元素, 如果已经打开的db号里没有该db号, 则说明这是一个新建的db, 直接在open_list队尾增加一个hdict, 同时根据db号得到一个哈希值, 在htab的对应槽里插入hdcit的队头.
如果open_list链表里的元素的db号和指定db号相等, 则说明这是一个换库的操作. 从open_list里删掉老的db, 同时把老的db加到clost_list里, 留到以后释放(ref减为0). 接着在open_list队尾增加一个hdict, 同时根据db号得到一个哈希值, 在htab的对应槽里插入hdcit的队头.
4.6 关闭db
关闭db实际上就是删除open_list里的元素, 将它增加到close_list里. 同时有一个控制线程在不断遍历close_list链表, 当发现有db的ref为0时, 则将其从close_list中删除. 这里有一个巧妙的地方就是在删除db时并没有真正进行资源的释放, 而是先把它们存到一个数组里, 当该数组的元素达到一定个数时, 再统一释该数组里的所有元素, 这个操作避免了每次释放资源带来的开销问题.
4.7 查找数据
查找数据是通过二分搜索key的值得到的. (这说明了索引文件的key值必须是有序排列的. 当数据来源于hadoop时, 经过reduce操作后, 索引文件天生就是有序的, 当数据不是由hadoop产生时, 如果索引文件没有排序, 则可以调用index_sort子程序使其变为有序). 在内存中找出key对应的pos后获得value的off和length信息, 接着调用pread函数即可从dat数据文件里取得真正的数据
5 监听程序对lushan server的控制
这里的监听程序并不是lushan c代码的一部分, 而是一个shell脚本, 通过它来实现对lushan的首次启动, 同时实现动态挂库的功能
5.1 总体

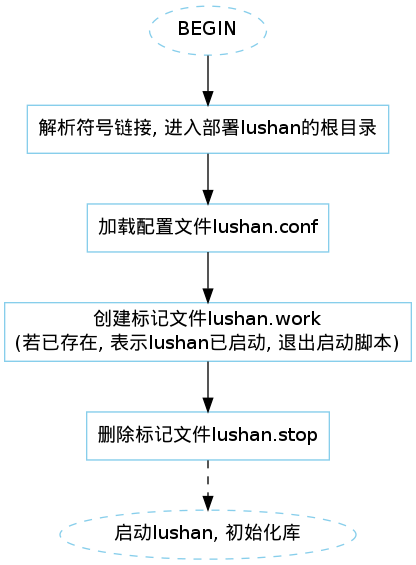
5.2 init
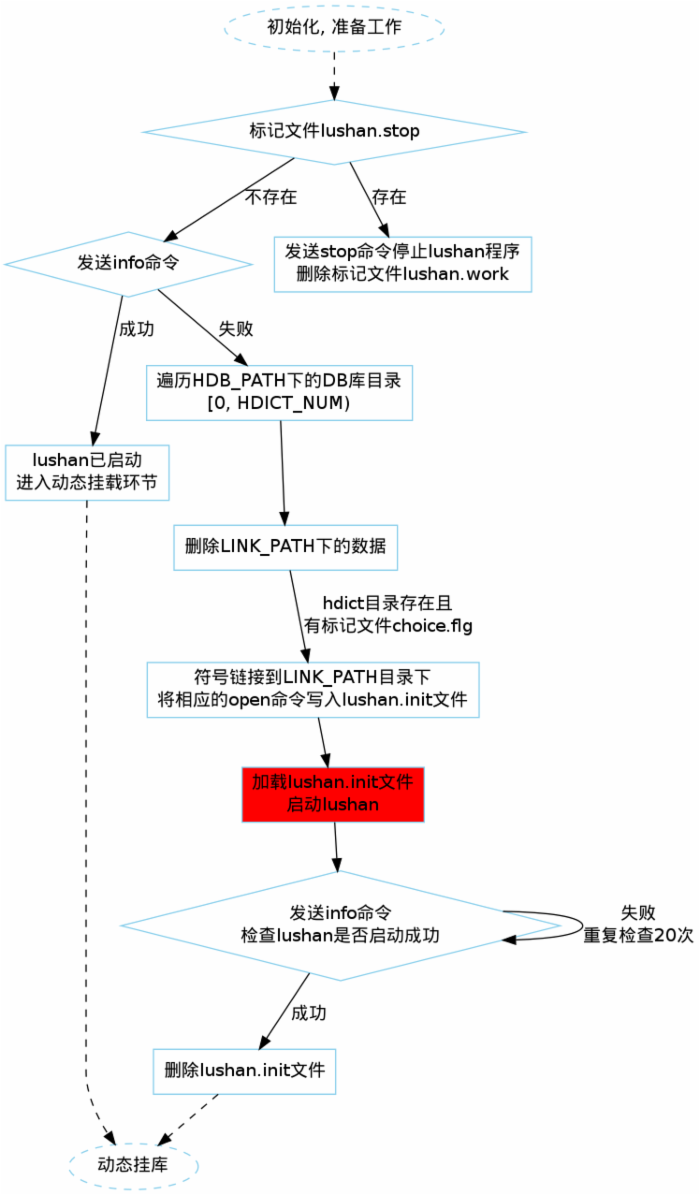
5.3 start
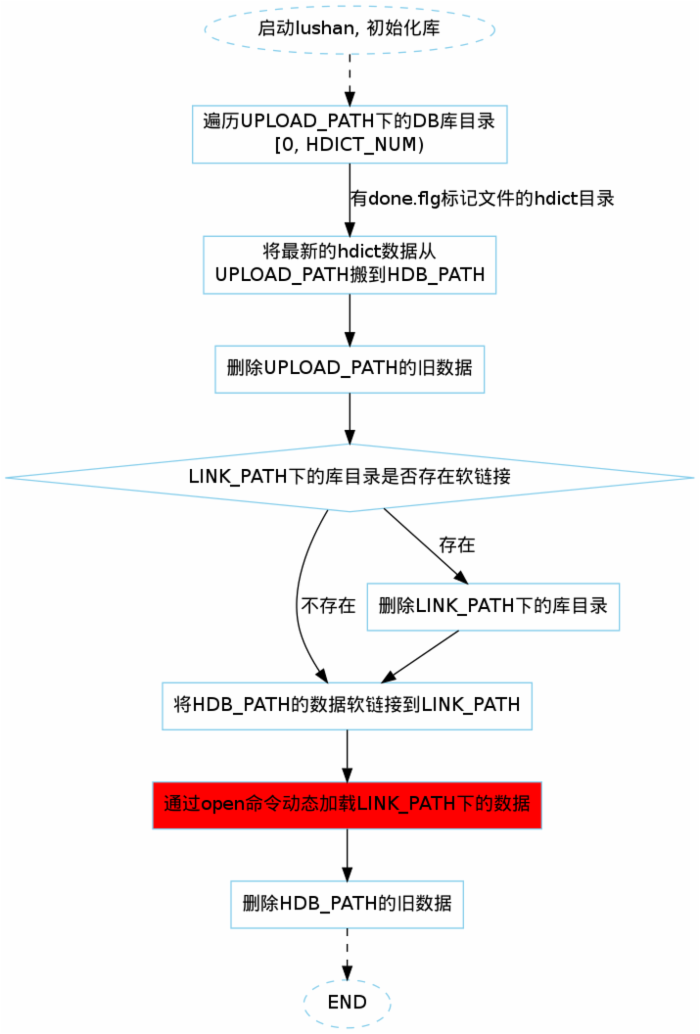
5.4 load
6 压力测试
两台linux主机, 一台作为lushan的服务器, 一台用于连接lushan的客户端
linux: CentOS release 5.4 (Final)
Intel(R) Xeon(R) CPU E5620 @ 2.40GHz (L2 cache: 12M) Quad-Core * 8
24G Memory
从lushan线上数据随机取10W条, 数据的value最小长度8Byte, 最大长度102252Byte, 平均1618Byte.在客户端上用python多进程模拟并发, 启动60个进程, 每个进程10000次请求, 总共60w请求
qps: 9000/s
99.9%的请求小于11ms
await平均在5ms
7 展望
虽然lushan在微博推荐中的静态数据存储方面扮演了重要的角色, 不过还是有很多工作要做. 比如提供一个代理层, 使客户端在取数据时直接访问代理层, 从而忽略数据到底是在线和离线的区别. 比如目前基于整型的key可以扩展为支持字符串的key. 还可以提供其他辅助工具, 使lushan集群在部署时更加高效,便利
正文到此结束
热门推荐










相关文章

近期评论
-
你这基本没有更新呀,最近文章显示还是2019年的文章。不符合要求哈
-
关键词:慕云博客 链接:https://www.lilun.me 描述:分享原创文字的个人博客
-
-
-
可以提供一下源码吗
-
不是商业站,鸡娃学习笔记
-
-
-
-
听他们说很厉害的样子
Loading...
![[HBLOG]公众号](http://www.liuhaihua.cn/img/qrcode_gzh.jpg)

