殷鹏翔:51信用卡的日志分析变迁史和技术细节
编者按: 51 信用卡管家是国内信用卡管理第一品牌。自 12 年创业开始,至 14年开始的“瞬时贷”上线,15年完成p2p金融信贷服务。51 信用卡的 CTO 殷鹏翔在 UPYUN Open Talk “移动时代互联网金融的架构趋势”主题线下沙龙中,分享了 51 信用卡的日志分析演变过程:
一、 日志变迁过程
1. 12 年初创期,用户数量在 50 万以内,处于原始数据积累期。日志分析主要用来关注每天新增用户、新增邮箱总数。整个系统完全同步处理数据库,只有业务处理、业务展示两个简单的层级结构。
2. 规模性增长期,用户量到达 200 万,日志慢慢开始转向为运营和产品服务。在运营层面,关注转化率(邮箱转化率,设备新增数等);产品层面,基于点击量判断产品功能、系统流程的好坏,以及关注系统稳定性(应用层故障指标,同步报警等)。在这个阶段,数据处理的方式也由同步处理转变成异步处理。
3. 高度增长期,当用户量达到 500 万时,业务耦合性高。为了避免资源浪费,创建了统一的数据分析接口,将所有日志全部汇总到一个数据统计分析平台,各业务线复用数据处理平台。
二、日志变迁中技术细节

在引入日志分析前,最早的方式是 DB Select Count 的形式,整个系统采用同步处理的方式,一台 Nginx 做前端,两台 DB,两台 Sever,简单处理数据,展示结果。

最初采用同步日志结构,所有东西都保存 Queue 里面,有一个线程扫描 Queue。当时访问量较少,用了六台机器,完全用 JVM 内存保存瞬时数据,使用线程池保证异步数据处理。问题是并发峰值、井喷访问的时候,线程池过大就很容易导致内存溢出,线程死锁也比较严重,导致 JVM 崩溃,内存里面的数据就全部丢失了。在数据量初步增长期,可以接受,但一旦达到一定规模后就完全无法承担。数据还有高峰低谷期的差别,需要以高峰期的资源配置保证整个系统的正常运行,因此加到了 20 个 JVM 存放数据。当日志量成倍增加的时候,明显感觉到当前的架构遇到了性能瓶颈,这时我们考虑到需要采用异步流程。
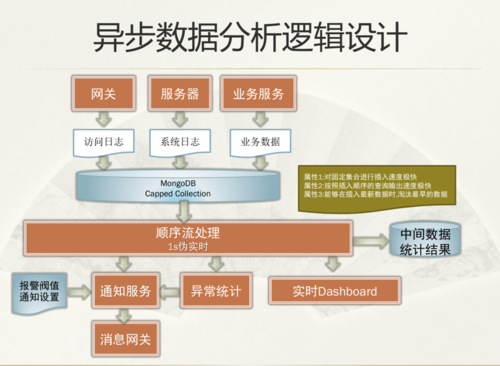
在日志收集过程中,我们增加了一个 MongoDB Capped Collection 模块。Capped Collection 的好处是有一个固定的结合点,比如说保存 10G、50G 的集合,先写入到 Capped Collection 中。它的性能很高,顺序插入速度很快,插入的时候每个数据有一份 Object ID。在插入最新数据的时候,淘汰最早的数据。所有的数据都是暂存MongoDB 里面,一旦这个数据超过了 50G,前面的数据会摘掉,这样可以排除前面的异常数据。最后根据一秒伪实时,保证数据都是顺序的处理。因为 Object ID 不同的机器收集的数据不是完全顺序的,系统允许一秒钟的伪实时算法,能够抛弃一秒钟的数据。

现在用 Fluentd 的方式收集日志,通过 Fluentd 实时采集到 Dashbroad,放到 MongoDB 的 Capped Collection 中。第二个就是 Log4j Append,Append 主要是采集系统应用层的数据,还有一些实时数据(比如页面的点击数)。部分行为日志会将实时数据采集到 MongoDB 的 Capped Collection。接下来是 Schedule,线程定时扫描收集到得日志进行分析统计,在同一个 Schedule 里面会存三份数据,一份存到 Result 作为统计结果,一份数据存到 HDFS,主要作为离线的数据预演,还有一份保存到 SolrCloud。 SolrCloud 最早是把它作为一个搜索引擎,也是为了一些预演,在 SolrCloud 上面做了一些定制,可以做很多维度的统计。在这个系统里面,SolrCloud 主要用来实时查数据、统计数据和验证数据。
在 2014 年的五六月份,我们开始行为数据的收集。在移动互联网领域,一般都会使用第三方工具来做数据统计,但统计结果不够详尽,无法很好地满足我们的业务需求。行为日志主要就是统计产品各个方面的日志,包括各个 UI 界面上的点击数、渠道转化率,用于控制成本和产品迭代。这些东西在当时没有更全面的数据来支撑,而且我们风控团队希望有更多的基础数据支撑风控结果验证。

客户端的每一个操作我们都会记录到行为日志中,再通过一定的压缩规则,上传到日志服务器中。使用 Hadoop 做离线分析,通过客户端的实时记录预测下一个时间段的交易量。实时数据是通过业务网关主要是 HDBS 的方式上传到服务器上面。
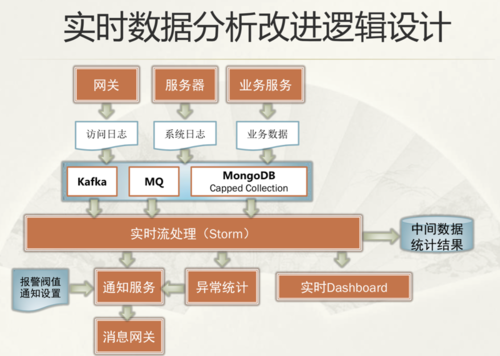
2014 下半年的时候,数据量井喷导致延迟加大,增加业务线需要修改代码、扩展性差,以及 Mongo 本身分布式能力不够、单点风险大,MongoDB方式在 15 年无法支撑现有的数据分析和处理的实时性,我们引入了 Storm。
之前的日志系统不能进行数据分级处理,会因某一数据过大,而影响所有分析延迟。比如说由于邮件收集数据过大,瞬时贷的日志会同期往后延迟,这样的话任何一笔业务都是在计算以前的数据。这是整个实时数据分析的改进逻辑,我们将网关数据和前端服务器的日志分开处理。现在打算在业务数据采用 Kafka,访问数据延用 MongoDB 的方式,系统日志和其余重要的业务数据走 MQ,能保证不同的业务场景使用不同的流处理,分级处理。

现阶段基于日志的分析,行为日志、业务服务日志、系统日志和网络日志都会经过日志分析,也会有中间统计结果。中间统计结果数据会出运营报表、访问量统计、系统监控、服务监控以及产品跟踪,中间结果 ETL、消费行为、风控和授信评分,及其他终端业务产品做数据支撑,用户数据进入金融产品。在金融产品逐步增多的过程中,整个 ETL 过程变成最耗时、耗资源的部分。下一步在就是把 ETL 作为整体的数据分析平台,基于Hadoop HDFS,包括 map reduce 和 Storm 结合做一个分析平台。

目前各业务线都要特定的 ETL 目标,上线一个新功能,需要遍历数据库,重新编写获取元数据。这种情况下,各业务线会用到 90% 相同的数据处理结果,比如用户访问频次、用户注册地、用户账单分析结果,便会造成资源浪费和入口不统一。因此,需要搭建一个数据平台——提供统一数据接口、统一分析、标准化 IPO 模式,实现 ETL 逻辑。
处理 ETL 目标不一样,逻辑也不一样,这需要不同的处理过程,和不同的存储框架。为实现日志分析平台化,将日志分为实时和离线两种形式,足以确保所有数据都经过实时流或离线处理。
实时流处理访问日志,用于判断服务器有无被攻击、后端服务器是否出现异常,以及地区访问量、业务收入等数据。
Hive 异步离线分析用于分析用户行为日志。行为日志存储在手机上,在面临用户低频率启动应用的情况下,系统半个小时做一次异步离线处理。在这个过程中,最关键的是,用户的消费数据会根据 ETL目标,进行 Map Reduce 处理或其他处理,采用数据结构较丰富的 Redis 做输出。最后会将数据结果输出到 SAS 中聚合和相关性分析,得到相关性模型。这就是整个数据分析平台化的过程。
我们下一步的目标是引入规则引擎,因为整个统计过程中,包括计算都是一个规则,如果所有的规则都做好了,这种算法是完全规则化的。引入引擎之后我们应用层的开发量就比较少了,但定制量比较多,业务人员和运营人员就可以配置规则进行数据统计分析。(责编/钱曙光)
 作者:2002年~2004年一直从事HIS系统开发实施,2005~2007年信雅达主要从事金融系统研发, 2007后进入互联网和移动互联网创业,房途网、快的、51信用卡。
作者:2002年~2004年一直从事HIS系统开发实施,2005~2007年信雅达主要从事金融系统研发, 2007后进入互联网和移动互联网创业,房途网、快的、51信用卡。
UPYUN Open Talk是 UPYUN 发起主办的行业技术沙龙,旨在以邀请各行各业优秀的企业技术负责人分享介绍自己工作过程中的技术架构经验的方式,推动整个移动互联网时代的企业员工的个人技术成长,从“人”这个关键点的个人成长提升去帮助推动企业的快速成长。
【约稿倡议书】 这几年,云计算成为了助力企业转型的核心驱动力,不但让企业的 IT 基础架构管理焕然一新,还为企业带来了更加智慧的运算方式。与此同时,云计算还引领着行业的变革,改变着人们的生活方式。虽然云计算处在快速的发展当中,但从起步、研发、应用、推广等各个环节上来说,在中国的发展时间都比较晚,其中存在的问题诸多,可谓是机遇与挑战共存。为了推动云计算技术发展、更好的服务行业参与者 , CSDN云计算频道 特在此面向 云服务提供商 、初创企业和个人等征集稿件,诚邀企业的实干家们来谈谈你们的技术实战,以及进行案例分享, 也欢迎就某个热点话题或技术来分享你的观点 。
投稿+咨询请致邮:qianshg@csdn.net。
正文到此结束
热门推荐










相关文章

近期评论
-
你这基本没有更新呀,最近文章显示还是2019年的文章。不符合要求哈
-
关键词:慕云博客 链接:https://www.lilun.me 描述:分享原创文字的个人博客
-
-
-
可以提供一下源码吗
-
不是商业站,鸡娃学习笔记
-
-
-
-
听他们说很厉害的样子
Loading...
![[HBLOG]公众号](http://www.liuhaihua.cn/img/qrcode_gzh.jpg)

