Spark——共享变量
Spark执行不少操作时都依赖于 闭包函数 的调用,此时如果闭包函数使用到了外部变量驱动程序在使用行动操作时传递到集群中各worker节点任务时就会进行一系列操作:
1、驱动程序使将闭包中使用变量封装成对象,驱动程序序列化对象,传给worker节点任务;
2、worker节点任务接收到对象,执行闭包函数;
由于使用外部变量势必会通过网络、序列化、反序列化,如外部变量过大或过多使用外部变量将会影响Spark程序的性能;
Spark提供了两种类型的 共享变量(Shared Variables) :广播变量(Broadcast Variables)、累加器(Accumulators );
广播变量(Broadcast Variables)
Spark提供的 广播变量 可以解决闭包函数引用外部大变量引起的性能问题;广播变量将只读变量缓存在每个worker节点中,Spark使用了高效广播算法分发变量从而提高通信性能;如直接在闭包函数中使用外部 变量该变量会缓存在每个任务(jobTask)中如果多个任务同时使用了一个大变量势必会影响到程序性能;
广播变量:每个worker节点中缓存一个副本,通过高效广播算法提高传输效率,广播变量是只读的;
Spark Scala Api与Java Api默认使用了Jdk自带序列化库,通过使用第三方或使用自定义的序列化库还可以进一步提高广播变量的性能;
广播变量使用示例:
val sc = SparkContext(""); val eigenValue = sc.bradcast(loadEigenValue()) val eigen = computer.map{x => val temp = eigenValue.value ... ... } 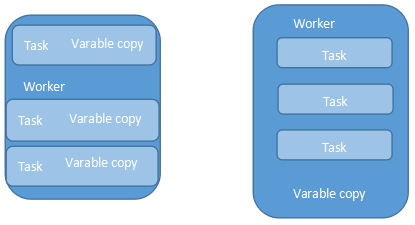
左节点不使用广播变量,右使用广播变量
累加器(Accumulators)
累加器可以使得worker节点中指定的值聚合到驱动程序中,如统计Spark程序执行过程中的事件总数等;
val sc = new SparkContext(...) val file = sc.textFile("xxx.txt") val eventCount = sc.accumulator(0,"EventAccumulator") //累加器初始值为0 val formatEvent = file.flatMap(line => { if(line.contains("error")){ eventCount +=1 } }) formatEvent.saveAsTextFile("eventData.txt") println("error event count : " + eventCount); 在使用 累加器(Accumulators) 时需要注意,只有在 行动操作 中才会触发累加器,也就是说上述代码中由于flatMap()为 转换操作 因为Spark惰性特征所以只用当saveAsTextFile() 执行时累加器才会被触发;累加器只有在驱动程序中才可访问,worker节点中的任务不可访问累加器中的值;
Spark原生支持了数字类型的的累加器如:Int、Double、Long、Float等;此外Spark还支持自定义累加器用户可以通过继承AccumulableParam特征来实现自定义的累加器此外Spark还提供了accumulableCollection()累加集合用于;创建累加器时可以使用名字也可以不是用名字,当使用了名字时在Spark UI中可看到当中程序中定义的累加器, 广播变量存储级别为MEMORY_AND_DISK;
正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](http://www.liuhaihua.cn/img/qrcode_gzh.jpg)

