Hadoop Raid-实战经验总结
分布式文件系统用于解决海量数据存储的问题,腾讯大数据采用 HDFS ( Hadoop分布式文件系统)作为数据存储的基础设施,并在其上构建如 Hive 、 HBase 、Spark 等计算服务。
HDFS 块存储采用三副本策略来保证数据可靠性,随着数据量的不断增长,三副本策略为可靠性牺牲的存储空间也越来越大。如何在不降低数据可靠性的基础上,进一步降低存储空间成本,成为腾讯大数据迫切需要解决的问题。
我们对 facebook 版本的 hadoop raid 分析发现,还有很多细节需要优化改进,本文就 hadoop raid 存在的问题进行探讨,并对一些可以改进的地方给出思路。
首先介绍一下 hadoop raid 的原理和架构:
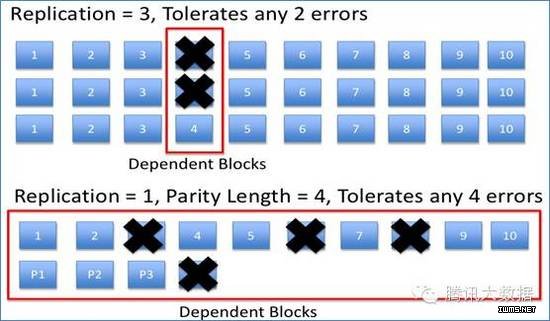
原理分析
HDFS Raid 以文件为单位计算校验,并将计算出来的校验 block 存储为一个 HDFS文件。 HDFS Raid 支持 XOR 和 RS 两种编码方式,其中 XOR 以位异或生成校验信息;而 RS 又称里所码,即 Reed-solomon codes ,是一种纠错能力很强的信道编码,被广泛应用在 CD 、 DVD 和蓝光光盘的数据纠错当中。
HDFS 为每个 block 创建 3 个副本,可以容忍 2 个 block 丢失,因此存储空间为数据量的 3 倍。而采用 RS 编码,如按条带( Stripe length )和校验块( Parity block )个数比例为 10,4 计算,则只需要 1.4 倍的存储开销,就可以容忍同一条带内任意 4 个block 丢失,即存储量可以节省 16/30 。
Hadoop Raid 架构

DRFS
l DRFS :应用 Raid 方案后的 HDFS
l RaidNode :根据配置路径,对需要 Raid 的文件( source file ),从 HDFS DataNode 中读取对应的数据块,计算出校验块文件( parity file ,所有校验块组成一个 HDFS 文件),并将 parity file 存储在 HDFS 中; RaidNode 周期性的检查源文件及校验块文件对应的 block 数据是否丢失,如有丢失,则重新计算以恢复丢失的 block
l Raid File System :提供访问 DRFS 的 HDFS 客户端,其在 HDFS Client 接口上进行封装,当读取已丢失或损坏的 block 时,通过对应的校验块计算恢复的 block 数据返回给应用,恢复过程对应用是透明的
l RaidShell : DRFS 管理工具,可手工触发生成 parity file 、恢复丢失 block 等
问题与优化
l 问题 1 集群压力增加
集群压力增加表现为 NameNode 元数据增多、访问量增加、 Raid 和数据恢复时集群网络及 IO 负载增加几个方面,具体如下:
其一, raid 过程中会生成校验文件以及目录结构,导致元数据增加。如下图所示,对于每一个原始文件,都会在目标目录生成一个对应的检验文件,造成元数据量double 。由于校验文件读操作远大于删除等更新操作,解决方案为对校验文件做 har打包,将目录打包成一个 har 文件,以节省元数据量。
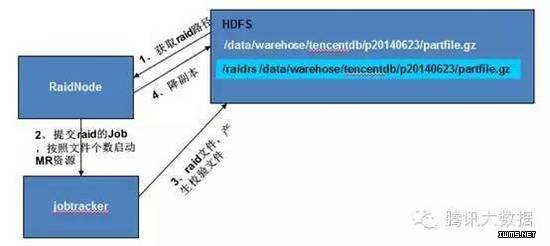
其二, RaidNode 周期性的访问 NameNode ,查询哪些文件需要做 raid 、是否存在废弃的 parity file (源文件被删除,则对应的 parity file 已经无效了,需要清理掉)、是否存在 Missing Block 等,这些操作都对 NameNode 产生一定压力。解决方案为调整RaidNode 访问 NameNode 的频率,控制在可接受的范围。
其三,做 Raid 生成校验文件及恢复丢失的 block 时,需要读取相同 stripe 的多个block 数据,导致集群内网络及 IO 负载增加。解决方案为选择空闲时段进行操作,减少对现网生产环境的影响。
其四, Raid 完成后,源文件 block 副本数减少, job 本地化概率减小,同时增加了网络流量和 job 的执行时间。为减少影响,只对访问频率较低的冷数据做 Raid ,而冷数据的判定,则需要从数据生成时间、访问时间、访问次数综合考虑。
l 问题 2 集群性能下降
性能下降则包括块删除速度变慢、读取频繁移动的块速度变慢,具体如下:
其一, NameNode 应用 Raid 块放置策略,删除 block 需要考虑相同 stripe 的其他block 的位置情况,以保证同一 DataNode 上不会存储该 stripe 的多个 block ,避免由于该 DataNode 故障缺失过多的块,造成数据无法恢复的风险。另外,在集群启动时, NameNode 要重建元数据信息,同时对比 block 的实际副本数和配置值,用以删除和增加 block ;由于 Raid 块放置策略的引入,每个 block 的增加和删除都需要考虑相同 stripe 的其他 block 位置信息,这一过程非常耗时,导致 NameNode 启动变慢很多。
解决方案是,在启动时使用默认的块放置策略,保持启动过程同原有流程相同,待启动完成,再修改为 Raid 块放置策略,动态刷新到 NameNode 生效。

其二, RaidNode 周期性的扫描原始文件和检验文件,如发现同一 DataNode 上存储该 stripe 内的过多 block ,则将超出来的 block 迁移到其他 DataNode 上。RaidNode 的检查周期默认值为 10 分钟,然而块移动过程 NameNode 并不会及时清掉 block 同移出 DataNode 的映射关系,而要等到下次 DataNode 块上报,块上报的周期比较长,一般 2 个小时。这样在下次块上报之前, NameNode 中 block 映射的DataNode 会不断累积,直至遍布整个集群。客户端读取这个 block 数据就会因很多DataNode 上并不存在块文件而重试,导致性能下降。解决方案为调整 RaidNode 扫描周期,要大于 DataNode 的块上报周期,期间 NameNode 来修正 block 和 DataNode的映射关系。

l 问题 3 数据安全性问题
表现在 rebalance 不理解 raid 概念:
Rebalance 不理解 raid 的条带的概念,将 block 在集群中重新移动后,可能会导致相同 stripe 的多个 block 保存在相同的 DataNode 上,存在丢块的风险。解决方案为NameNode 增加 RPC 接口,查询 block 所属文件,进而结合 raid 块放置策略,将stripe 的多个 block 分散得更散。
l 问题 4 Raid 过程 Job 数据倾斜
RaidNode 提交 job 对多个源文件做 raid ,理想效果如图 (a) ,多个文件平均分配到每个 map 中 raid 操作,但执行过程中发现大部分 map 迅速完成,统计读取记录为 0,而另外少部分 map 执行时间较长。
分析流程发现, RaidNode 采用同 distcp 相同的方式,先将需要 raid 的文件列表,以 SequenceFile 格式写入 HDFS ,且每 10 个文件写入一次 SYNC 标识,分片时再将每个文件构造成 FileSplit 作为分片单元; map 读取输入使用SequenceFileRecordReader ,以 SYNC 标识为起止位置。以 (b) 图为例, map1 的起止位置跨越了 SYNC1 ,因读取的数据为 SYNC1 和 SYNC2 之间的 10 个文件列表,而其它 map 的起止位置在同一 SYNC 区间内,则读取数据为 0 ,这就是 job 倾斜的原因。
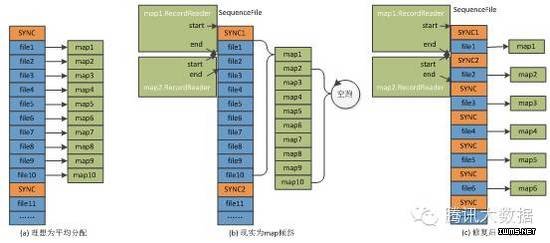
解决方案为每个文件后面都写入一次 SYNC 标识,多个文件就会平均分配到 map 中执行。而 SYNC 标识占用 20 个字节,且只在 job 执行结束 SequenceFile 就会清理掉,存储代价微乎其微。

正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](http://www.liuhaihua.cn/img/qrcode_gzh.jpg)

