Hadoop列式存储引擎Parquet/ORC和snappy压缩
相对于传统的行式存储格式,列式存储引擎具有更高的压缩比,更少的IO操作而备受青睐。列式存储缺点:在column数很多,每次操作大部分列的时候,cpu压力突增,而且增加处理时长。优点:在cloumn数很多,每次操作若干列的场景,列式存储的性价比,性能更高。
在很多大数据的应用场景下面,数据量很大、单列数据字段很多;比如电信行业,
具有一定规则的数据,字段很多,但是每次查询仅仅针对其中少数的几个字段,这个时候列式存储是极佳的选择。目前在大数据开源实现中,有多种列式存储实现,最早hive支持的rcfile,到后面的ORC,parquet; 不同的SQL-on-Hadoop解决方案,对不同的列式存储做
过不同的优化:
- Impala推荐使用parquet格式,不支持ORC,Rcfile - Hive 0.x版本推荐使用rcfile - PrestoDB推荐使用ORC - Spark支持ORC,Parquet,Rcfile Apache Parquet
源自于google Dremel系统(可下载论文参阅),Parquet相当于Google Dremel中的数据存储引擎,而Apache顶级开源项目Drill正是Dremel的开源实现。Apache Parquet 最初的设计动机是存储嵌套式数据,比如Protocolbuffer,thrift,json等,将这类数据存储成列式格式,以方便对其高效压缩和编码,且使用更少的IO操作取出需要的数据,这也是Parquet相比于ORC的优势,它能够透明地将Protobuf和thrift类型的数据进行列式存储,在Protobuf和thrift被广泛使用的今天,与parquet进行集成,是一件非容易和自然的事情。 除了上述优势外,相比于ORC, Parquet没有太多其他可圈可点的地方,比如它不支持update操作(数据写成后不可修改),不支持ACID等。
Apache ORC
ORC(OptimizedRC File)存储源自于RC(RecordColumnar File)这种存储格式,RC是一种列式存储引擎,对schema演化(修改schema需要重新生成数据)支持较差,而ORC是对RC改进,但它仍对schema演化支持较差,主要是在压缩编码,查询性能方面做了优化。RC/ORC最初是在Hive中得到使用,最后发展势头不错,独立成一个单独的项目。Hive 1.x版本对事务和update操作的支持,便是基于ORC实现的(其他存储格式暂不支持)。ORC发展到今天,已经具备一些非常高级的feature,比如支持update操作,支持ACID,支持struct,array复杂类型。你可以使用复杂类型构建一个类似于parquet的嵌套式数据架构,但当层数非常多时,写起来非常麻烦和复杂,而parquet提供的schema表达方式更容易表示出多级嵌套的数据类型。
Parquet与ORC
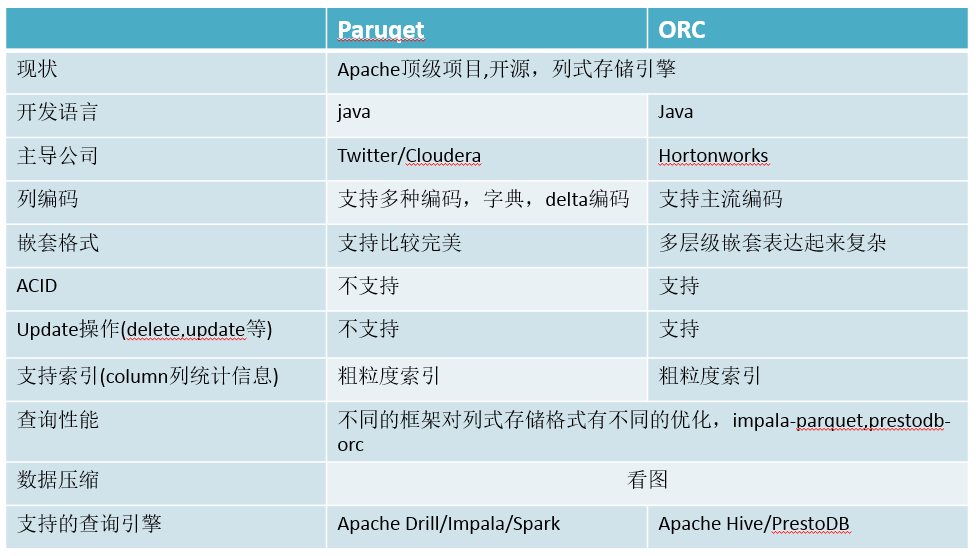
注意:如果用比较大量的数据转换列式存储格式,对服务器压力是非常大的,时间换空
间,权衡之.不同的SQL-on-Hadoop框架生成的列式存储格式消耗时间也不一致,由于
Spark底层是多线程,目前生成各种列式存储效率最高,其他框架Impala高于PrestoDB.
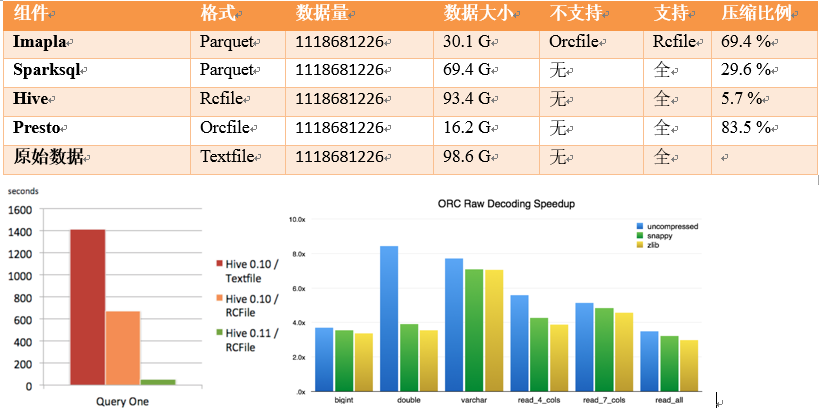
看图

hbase && snappy
hbase选择Snappy压缩,Hbase做为大数据数据库,兼顾列式存储的开源数据库,NoSQL典型
代表,提供面向列式检索高效反应的场景,基于kv可高度压缩,为了提供CRUD操作,要求结果最终一致性,而update,delete操作需要在hbase存储数据region拆分过程来达到删除数据目的,也就是region:split &&compact;如果入hbase数据量太大,每天几个T数据,
每个region超过100g会自动做region拆分,导致占用大量集群IO,使得集群其他框架比如spark,Impala,PrestoDB效率低下;这个时候为Hbase选择基于列族的高度压缩算法尤为重要,减少数据量大小,降低IO操作,通过预建立region,严格控制region大小=1g左右,关闭自动region split&&compact操作,在一个合理的时间手动做split && compact,降低集群
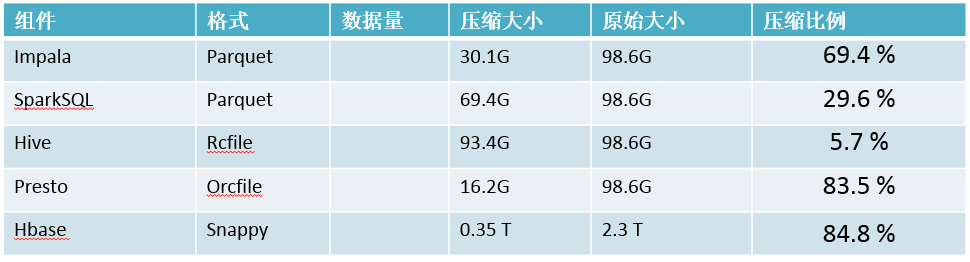
IO压力,而snappy即是最佳选择,如图:
- Hadoop压缩算法选择:
- mapreduce.map.output.compress.codec
- mapreduce.output.fileoutputformat.compress.codec
- mapreduce.output.fileoutputformat.compress.type
- org.apache.hadoop.io.compress.DefaultCodec
- org.apache.hadoop.io.compress.SnappyCodec [最佳选择]
- org.apache.hadoop.io.compress.BZip2Codec /GzipCodec【GzipCodec压缩最高,但是时间上比较耗时】
总结
随着Hadoop技术在各行各业深入使用,而且Hadoop在数据仓库,大规模数据分析型场景
的应用,选择一个合理的列式存储格式和高效的压缩算法尤为重要。列式存储目前也逐渐被应用于各种产品线,比如twitter,facebook已经将大部分数据格式转换为parquet,ORC
等列式存储格式,所占用空间和查询时间减少约35%。Parquet && ORC文件格式的压缩功能
显著降低了使用的磁盘空间,以及执行查询和其他操作所花的时间。
参考:
https://code.facebook.com/posts/229861827208629/scaling-the-facebook-data-warehouse-to-300-pb/
https://cwiki.apache.org/confluence/display/Hive/LanguageManual+ORC
https://github.com/Parquet原创文章,转载请注明: 转载自whoami的博客
本博客的文章集合: http://www.itweet.cn/archives/
正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](http://www.liuhaihua.cn/img/qrcode_gzh.jpg)

