一个关于执行计划的小问题测试
最近有朋友在微信公众号后台留言提了一个问题,问题如下:
执行计划中,并列的两条操作比如并列的两条table access full,上层没有关联操作比如hash join,这是什么意思?
这个问题一下子看起来就比较清晰了。
为了简单复现这个问题,在本地做了一个小测试。
为了达到同样的表结构,我创建了同样的表。
create table by_fs as select object_id zd_fs, object_name kecheng from all_objects where rownum<11;
create table xs_xf as select object_id zd_fs, object_name kecheng from all_objects where rownum<20;
然后启用trace,得到的执行计划情况如下:
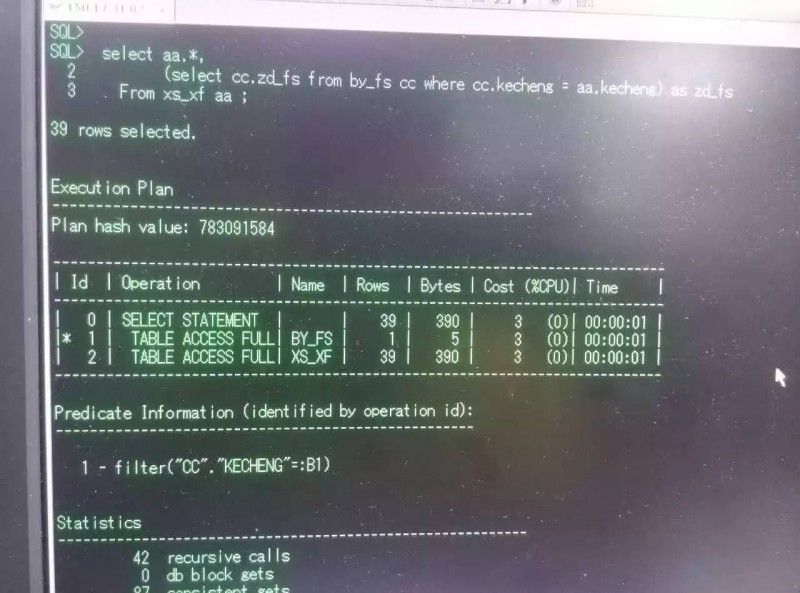
可以看到是可以复现这个朋友的问题的。这个时候从执行计划来入手,看到对于表XS_XF走了全表扫描,对于其中的数据在表BY_FS中通过全表扫描进行匹配。
整个执行计划的关键可以看到谓词信息:
Predicate Information (identified by operation id):
---------------------------------------------------
1 - filter("CC"."KECHENG"=:B1)
在by_fs中,会把外层xs_xf的查询结果通过绑定变量的方式传入,感觉其实和表关联的方式应该是一样的情况。
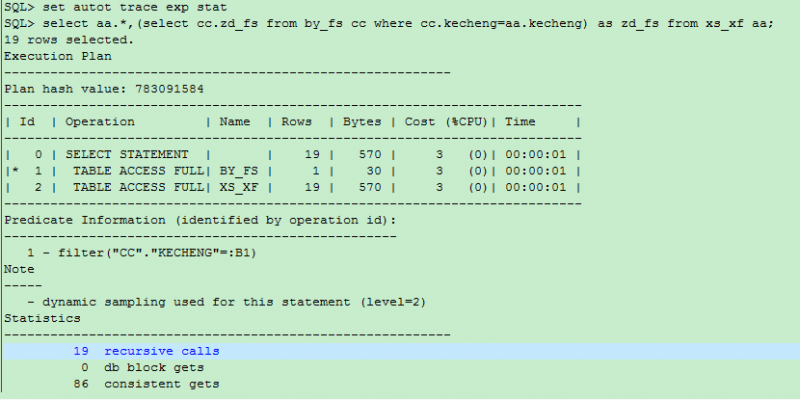
而如果改为表连接的场景,可以轻松实现。改写为下面的形式继续查看。

这个时候可以看到对这两个表还是走了全表扫描,表连接为hash join的方式,可以看到一致性读也确实低了不少。
这个地方为什么看到的是hash join,还是通过谓词信息来看。
Predicate Information (identified by operation id):
---------------------------------------------------
1 - access("CC"."KECHENG"="AA"."KECHENG")
目前两个表还是没有任何索引的,但是通过谓词信息可以看到access的字样,可见是在数据库内部做了这一层的映射,把两个表的数据通过hash算法进行映射。
我们接着创建索引。
create index ind_xs_xf on xs_xf(kecheng);
create index ind_by_fs on by_fs(kecheng);
还是使用最开始的sql
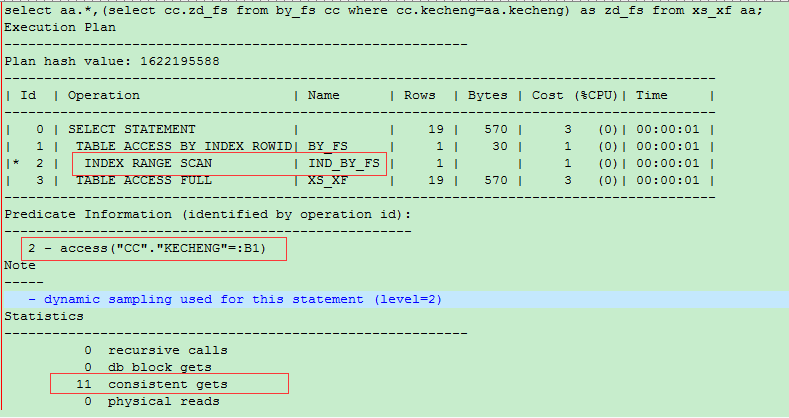
可以看到CBO还是做了很合理的选择,对于xs_xf还是使用全表扫描,对于返回的结果集,是通过绑定变量的方式传入子查询。
我们更近一步,来看看修改为表关联的方式,执行计划的变化。

这种结果就好比下面的形式。
select kecheng,zd_fs from by_fs order by kecheng;
select * from xs_xf order by kecheng;
针对本例,是对by_fs做了全表扫描,对数据进行了排序,然后根据kecheng对结果集进行了匹配和关联,最后把结果集输出。
因为merge-sort join确实使用情况会相对比较少,在数据库中是存在一个隐含参数来控制的。
NAME VALUE ISDEFAULT ISMOD ISADJ
------------------------------------------ --------- ---------- -----
_optimizer_sortmerge_join_enabled TRUE TRUE FALSE FALSE
当然也可以通过Hint /*+use_merge(cc,aa)来进行控制和管理。
当然更多的信息没有进行挖掘,不过从我的直观感受来看,第一个查询的效果和表关联的场景还是很类似的。而且通过CBO来做出的最终判定来看,差别很明显,但是效果基本是一致的。
执行计划中,并列的两条操作比如并列的两条table access full,上层没有关联操作比如hash join,这是什么意思?
但是两张表在sql中是有等值连接的,为什么执行计划没有提现连接方式呢?
然后他过了一会附了一张操作截图。
然后他过了一会附了一张操作截图。
这个问题一下子看起来就比较清晰了。
为了简单复现这个问题,在本地做了一个小测试。
为了达到同样的表结构,我创建了同样的表。
create table by_fs as select object_id zd_fs, object_name kecheng from all_objects where rownum<11;
create table xs_xf as select object_id zd_fs, object_name kecheng from all_objects where rownum<20;
然后启用trace,得到的执行计划情况如下:
可以看到是可以复现这个朋友的问题的。这个时候从执行计划来入手,看到对于表XS_XF走了全表扫描,对于其中的数据在表BY_FS中通过全表扫描进行匹配。
整个执行计划的关键可以看到谓词信息:
Predicate Information (identified by operation id):
---------------------------------------------------
1 - filter("CC"."KECHENG"=:B1)
在by_fs中,会把外层xs_xf的查询结果通过绑定变量的方式传入,感觉其实和表关联的方式应该是一样的情况。
而如果改为表连接的场景,可以轻松实现。改写为下面的形式继续查看。
这个时候可以看到对这两个表还是走了全表扫描,表连接为hash join的方式,可以看到一致性读也确实低了不少。
这个地方为什么看到的是hash join,还是通过谓词信息来看。
Predicate Information (identified by operation id):
---------------------------------------------------
1 - access("CC"."KECHENG"="AA"."KECHENG")
目前两个表还是没有任何索引的,但是通过谓词信息可以看到access的字样,可见是在数据库内部做了这一层的映射,把两个表的数据通过hash算法进行映射。
我们接着创建索引。
create index ind_xs_xf on xs_xf(kecheng);
create index ind_by_fs on by_fs(kecheng);
还是使用最开始的sql
可以看到CBO还是做了很合理的选择,对于xs_xf还是使用全表扫描,对于返回的结果集,是通过绑定变量的方式传入子查询。
我们更近一步,来看看修改为表关联的方式,执行计划的变化。
这种结果就好比下面的形式。
select kecheng,zd_fs from by_fs order by kecheng;
select * from xs_xf order by kecheng;
针对本例,是对by_fs做了全表扫描,对数据进行了排序,然后根据kecheng对结果集进行了匹配和关联,最后把结果集输出。
因为merge-sort join确实使用情况会相对比较少,在数据库中是存在一个隐含参数来控制的。
NAME VALUE ISDEFAULT ISMOD ISADJ
------------------------------------------ --------- ---------- -----
_optimizer_sortmerge_join_enabled TRUE TRUE FALSE FALSE
当然也可以通过Hint /*+use_merge(cc,aa)来进行控制和管理。
当然更多的信息没有进行挖掘,不过从我的直观感受来看,第一个查询的效果和表关联的场景还是很类似的。而且通过CBO来做出的最终判定来看,差别很明显,但是效果基本是一致的。
正文到此结束
- 本文标签: IHS git 数据库 IDE Select DDL IOS IBM awk nfs 数据 DOM src kk tab ip Ipo UI UDP lib ACE rpm SVN tar map TCP ftp http 测试 db sql NFV 参数 W3C ssl db2 CDN apr FIT value ECS zip cvs DNS cat 管理 key ask 微信公众号 rmi cmd js O2O NSA XML VPN CRM
- 版权声明: 本文为互联网转载文章,出处已在文章中说明(部分除外)。如果侵权,请联系本站长删除,谢谢。
- 本文海报: 生成海报一 生成海报二
热门推荐










相关文章






Loading...
![[HBLOG]公众号](http://www.liuhaihua.cn/img/qrcode_gzh.jpg)

