LIME:一种解释机器学习模型的方法
原文链接: LIME - Local Interpretable Model-Agnostic Explanations
译者:赵屹华 审校:刘翔宇
责编:周建丁(投稿请联系zhoujd@csdn.net)
在本文中,我们将介绍一种方法,用来解释 这篇论文 中的任何一种分类器的预测结果,并且用 开源包 来实现。
动机:我们为什么要理解预测结果?
机器学习如今是非常火的一个话题。随着计算机在围棋等游戏中击败人类专家,许多人不禁要问机器是否也能胜任司机的工作,甚至是取代医生?
现在很多前沿的机器学习模型还是一个黑盒,几乎无法去感知它的内部工作状态。这就给我们带来了可信度的问题:我该相信那个模型的某个预测结果是正确的吗?或者说我该相信那个模型的预测结果普遍都是合理的吗?围棋游戏的赌注还是小事,如果让计算机取代医生可算一件大事了,或者让计算机判断我是不是恐怖分子嫌疑人(《疑犯追踪》)。更通俗的来说,如果一家公司正准备替换上一套基于机器学习的系统,它就要确保机器学习模型的工作状态是良好的。
从直观上看,解释每次独立预测背后的基本原理能使我们更容易信任或是不信任预测结果,乃至分类器本身。即使我们无法理解模型在所有情况下的表现,却有可能理解(大多数情况都是如此)它在某些特定情况下的行为。
最后,说一下准确性。如果你有机器学习的经验,我敢说你正在想的是:“我当然知道模型在真实情况下能取得不错的效果,因为在交叉验证中已经得到了很高的准确率!当99%的情况下模型都能准确预测时,我为啥还要去理解它的预测结果呢?”任何一位在现实问题中(不是在静态的数据集上)使用过机器学习方法的人都能证明,交叉验证的准确率很具有误导性。有时候预测数据会不小心混入训练数据中。有时候你收集数据的方法会引入现实中不存在的相关性,而模型却能捕捉到。其它许多棘手的问题都会影响我们评判模型性能,即使是使用 A/B测试 。我不是不让你测试准确率,而是准确率不应该是你的唯一标准。
Lime:一些例子
你真的相信你的新闻数据集的分类器吗?
首先,我们给一个文本分类的例子。著名的新闻数据集( 20 newsgroups dataset)是一个标尺,在多篇文章中被用来比较不同的模型。我们选取两个难以区分的类别,选取标准是它们有着许多重合的词语:基督教(Christianity)和无神论(Atheism)。训练一个有着500棵树的随机森林,我们在测试集上得到92.4%的准确率,高的惊人了。如果准确率是唯一的衡量标准,我们肯定会相信这个算法。
下图是测试集中任意一个案例的解释,由 lime包 生成。
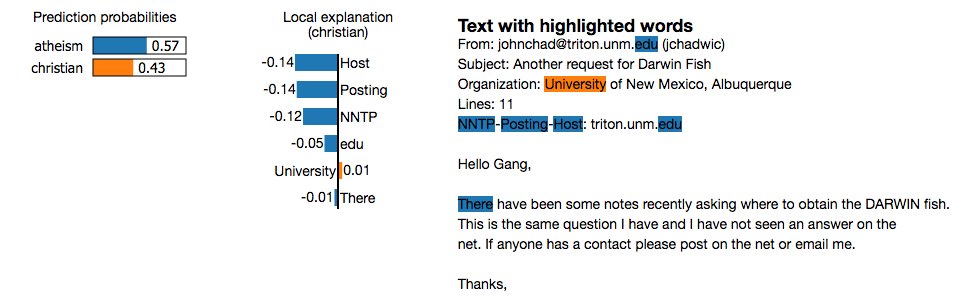
这是分类器预测结果正确但是原因错误的一个例子。仔细观察就会发现单词“Posting”(邮件抬头的一部分)在21.6%的训练数据中出现过,仅有两次是属于“基督教”类别。在测试集里也是一样,它在20%的样本中出现过,也仅有两次属于“基督教”类别。数据集的这种分布状态使得问题比现实状况简单得多,分类器是无法区分基督教和无神论两个类别的。这一点准确率或者原始数据上是很难观察到的,但是如果有预测的解释则很容易发现。一旦你明白了模型真正的工作原理,此类洞察能力就显得很平常了,模型的泛化能力也更强了。
进一步看看其解释能力如何:这是一个非常稀疏的线性模型(只有6维特征)。尽管底层的分类器是复杂的随机森林,在这个例子里它几乎就是个线性模型。基本可以确定,如果我们从例子中删除“Host”和“NNTP”两个单词,预测为“atheism”的概率值将会是0.57-0.14-0.12=0.31。
由深度神经网络解释预测结果
下图来自我们的论文,我们在一些任意的图像上解释Google的 Inception neural network。在本例中,我们解释图像中类别最确定的那部分。这里,图像中的是木吉他,分类器却预测为电吉他。解释部分阐述了为何两者被混淆了:它们的指板很相似。lime包目前暂时还无法实现图像分类器的解释,我们正在开发中。

参考阅读: 深度神经网络的灰色区域:可解释性问题
Lime:我们是如何进行解释
Lime是Local Interpretable Model-Agnostic Explanations的缩写。名字的每一部分反映了我们进行解释的意图。 Local 指的是局部保真——也就是说我们希望解释能够真实地反映分类器在被预测样本上的行为。这个解释要求是可以理解的( interpretable )——即能够被人类读懂。Lime能够解释任何模型,而不需要进行模型适配,所以是与模型无关的( model-agnostic )。
现在我们来俯瞰一下lime的工作原理。若想了解更多细节,请查阅我们论文的 预印版 。
首先来说一说 可解释性 。有些分类器使用的用户完全无法理解的表征方式(如词向量)。Lime用可以被理解的表征方式(比如用单词)来解释这些分类器,即使它不是分类器真正在使用的方式。另外,lime考虑了人类的局限性:解释内容不会过长。目前,我们的工具包支持稀疏线性模型的解释,我们正在开发支持其它表征方式。
为了做到 与模型无关 ,lime不会深入模型内部。为了搞清楚哪一部分输入对预测结果产生贡献,我们将输入值在其周围做微小的扰动,观察模型的预测行为。然后我们根据这些扰动的数据点距离原始数据的距离分配权重,基于它们学习得到一个可解释的模型和预测结果。举个例子,如果我们要解释“我讨厌这部电影”这句话的预测结果,我们将打乱这个句子,对“我讨厌电影”、“我这部电影”、“我电影”、“我讨厌”等句子进行预测。即使起初的分类器使用了更多的词语,但是我们可以合理的预期例子中只有“讨厌”这个词相关。注意,如果分类器用到了一些不可解释的表达方式,比如词向量,此方法依旧可行:我们只需用词向量来打乱句子,不过最后的解释还是会落到诸如“讨厌”或“电影”的词。
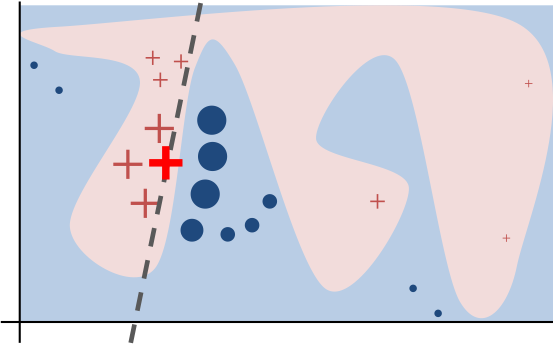
这个过程的演示图如下。原始模型的决策函数用蓝/粉背景表示,显然是非线性的。亮红色的叉叉表示被解释的样本(称为X)。我们在X周围采样,按照它们到X的距离赋予权重(这里权重的意思是尺寸)。我们用原始模型预测这些扰动过的样本,然后学习一个线性模型(虚线)在X附近很好地近似模型。注意,这个解释只在X附近成立,对全局无效。
结论
我希望已经能让你明白了理解预测器单独的预测结果的重要性。有了解释,你能有更多的信息来决策是否信任预测结果,或是整个模型,以及提供思路来改进模型效果。
代码和论文的链接
如果你对深入理解lime的工作原理和曾经做过的验证性实验感兴趣,请查看论文的 预打印版 。
如果你想对文本分类器使用lime,请下载我们的 python工具包 。安装命令如下:
pip install lime
工具包的使用很简单。它特别容易解释scikit-learn的分类器。在github页面我们还放了一些教程,比如 这个 ,来自scikit-learn的例子。
2016年4月22日-23日,由CSDN重磅打造的 SDCC 2016数据库&架构技术峰会 将在深圳举行,目前18位讲师和议题已全部确认。两场峰会大牛讲师来自百度、腾讯、阿里、京东、小米、唯品会、滴滴出行、携程等知名互联网公司,共同探讨高可用/高并发/高稳定/高流量的系统架构设计、秒杀系统架构、搜索架构、中小企业架构之道、数据平台系统演进历程和技术剖析、传统数据库与分布式数据库选型/备份/恢复原理及优化实践、大数据应用实战等领域的热点话题与技术。【目前限时6折,点击这里抢票】
正文到此结束
热门推荐










相关文章

近期评论
-
你这基本没有更新呀,最近文章显示还是2019年的文章。不符合要求哈
-
关键词:慕云博客 链接:https://www.lilun.me 描述:分享原创文字的个人博客
-
-
-
可以提供一下源码吗
-
不是商业站,鸡娃学习笔记
-
-
-
-
听他们说很厉害的样子
Loading...
![[HBLOG]公众号](http://www.liuhaihua.cn/img/qrcode_gzh.jpg)

