PacificVis 2016 前瞻
PacificVis是可视化领域三大盛会之一,每年会接收来自全世界上百篇高级别文章的投稿。经过审稿委员会创的同行评审,遴选出30余篇高质量可视化前沿文章,每年吸引了百余位可视化前沿研究学者和工业界高级研究人员热情参与和积极交流。作为以亚太区域为主要承办国家和地区的可视化盛事,PacificVis是国内可视化研究人员交流和分享的重要平台。每年北京大学,浙江大学,清华大学,中南大学等高校数十位可视化研究人员的参与,极大促进了国内可视化的研究与发展。
PacificVis创始于2008年,第一届会议在日本的京都举办。次年,在北京大学袁晓如研究员的大力推动和北京大学信息科学技术学院的支持下,第二届PacificVis在北京大学成功举办。此次会议将可视化这一新鲜前沿的研究领域带入中国大陆,引领了之后可视化研究与可视化思想在学术和工业界的发展。
之后的几年里,PacificVis依次在中国台北,中国香港,韩国开城,澳大利亚悉尼,日本横滨和中国浙江举办。每年北京大学可视化与可视分析研究小组都会派出多名学生参加,进行学习交流。通过此平台,培养学生广阔的国际视野。
每年PacificVis接收来自世界数十个国家近百篇论文的投稿,最终接收30篇左右的高质量文章,并会推选3-5篇文章到IEEE顶级期刊TVCG。具体的论文接收情况,可见下图:

图1 PacificVis论文接收情况
北京大学可视化与可视分析小组自2009年起,每年都会有多篇文章被收录,论文覆盖了体可视化、流场可视化、交通可视分析、社交媒体可视分析等众多研究领域。除此之外,每年还会有多篇会议展报提交并被接收。会议展报主要用于介绍实验室最新研究动态和进展。其中,2013年北京大学本科生任东昊提交的“Visualization Assembly Line: Sketch-Based Multidimensional Data Visualization Construction and Online Collaboration”被推选为会议最佳展报。
今年,第9届PacificVis在祖国宝岛台湾再次召开。北京大学可视化与可视分析研究组共有三篇会议论文和四篇展报被接收,创历年之最。下面是三片会议论文的简要介绍。
第一篇文章是一个关于集合模拟数据的可视分析框架——EnsembleGraph。这篇文章旨在帮助科学家了解模拟成员的相似性关系在时空中分布和演化。我们按照成员之间相似程度为出发点,从集合模拟数据中捕捉具有高相似度的时空地点,并用图的形式来展示:节点代表时空中具有高相似度的区域,节点之间的连边表示相邻时刻区域发生重叠。结合多视图交互的界面(如图1所示),用户可以直接对集合模拟数据进行快速浏览,并选择区域来比较其内集合模拟成员的分布情况。我们把EnsembleGraph工具应用在了两组真实世界数据上:臭氧与污染排放影响实验集合模拟数据,以及一组流体力学实验集合模拟数据。该工具能帮助用户直接发现具有相近成员行为的区域,从相似性角度来分析复杂集合模拟数据,这是以往手动选取地点的方法所不可能做到的。

在第二篇文章中,我们运用了高阶的访问转移的思想,在计算访问依赖关系时结合场线的数据访问历史信息。不同于已有的基于一阶访问依赖的方法,在我们的方法中,对下一步可能访问的数据块的预测不仅与当前的数据块有关,还建立在已访问的若干数据块序列上。我们通过一个数据预处理过程,在每一个数据块同时正向和反向追踪迹线,并将得到的正向迹线所记录的数据访问作为下一步可能的数据块访问信息,反向迹线所记录的数据访问作为历史访问信息,然后计算出经过这些历史数据块后可能到达下一个数据块的概率,以此构建每一个数据块的高阶访问依赖关系。预处理完毕后,我们将高阶的数据访问依赖运用到并行的粒子追踪中,并使用了高阶的数据预取来提高迹线的计算效率。我们将这种方法分别应用到了全域均匀撒种的全局分析和区域撒种的局部分析中,实验证明这种方法可以很大程度上提高预取数据的使用率,相比于基于一阶访问依赖的方法可以获得更高的场线计算效率。

图3 高阶访问依赖的计算
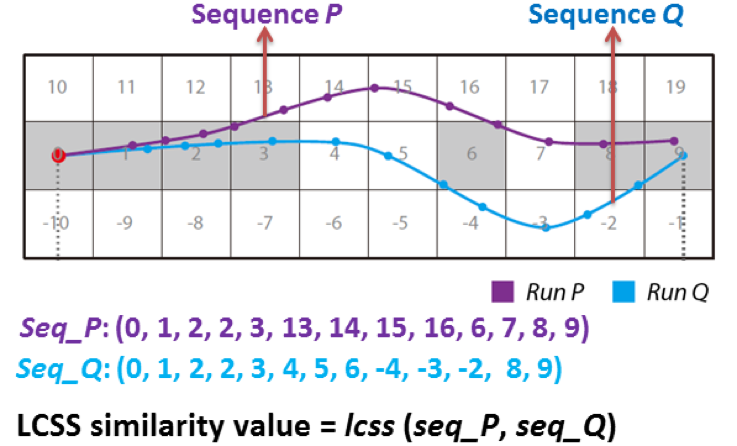
在第三篇文章中,我们提出了一种基于最长公共子序列(LCSS)的新的集合模拟向量场(vector field ensembles)度量方法。首先在每个集合向量场(不同的模拟成员)中进行迹线追踪,得到集合迹线(ensemble pathlines)。其次,对数据进行分块处理,并给每个数据块赋予全局唯一索引值。将所有集合迹线经过的数据块的索引值按时间步组成LCSS序列码,作为LCSS算法的输入,如图2所示。再次,使用LCSS算法度量集合迹线之间的距离,主要是计算集合迹线共同通过的块的个数,该距离作为集合迹线之间的不确定性。最后,将所有集合迹线的不确定性可视化出来并进行分析。经过评估,我们发现我们的LCSS方法对异常值(outlier),数据缺失(data missing)以及时间步采样率(time step)都比较鲁棒。
北京大学袁晓如研究员和梁婕博士将带领11位研究生同学,于2016年4月18日前往中国台北参与会议。届时,参与人员将对会议动态作详细记录,并对有关论文作评述,欢迎关注北京大学可视化博客,微博(@北京大学可视化研究组)和微信公众号(VisualAnalytics),获取最新消息。
正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](http://www.liuhaihua.cn/img/qrcode_gzh.jpg)

