MySQL订单分库分表多维度查询
MySQL分库分表,一般只能按照一个维度进行查询.
以订单表为例, 按照用户ID mod 64 分成 64个数据库.
按照用户的维度查询很快,因为最终的查询落在一台服务器上.
但是如果按照商户的维度查询,则代价非常高.
需要查询全部64台服务器.
在分页的情况下,更加恶化.
比如某个商户查询第10页的数据(按照订单的创建时间).需要在每台数据库服务器上查询前100条数据,程序收到 64*100 条数据,然后按照订单的创建时间排序,截取排名90-100号的10条记录返回,然后抛弃其余的6390条记录.如果查询的是第100页,第1000页,则对数据库IO,网络,中间件CPU,都是不小的压力.
分库分表之后,为了应对多维度查询,很多情况下会引入冗余.
比如两个集群,一个按照用户ID分库分表,另外一个按照商户ID分库分表.
这样多维度查询的时候,各查各的.
但是有几个问题,一样不好解决.
比如,
每扩展一个维度,就需要引入一个集群.
集群间的数据,如何保证一致性.
冗余占用大量磁盘空间.
从朋友那里看到的订单表结构.做冗余会占用大量的磁盘空间.
可以试试用表代替索引的方法.
1.分库分表
2.最终一致性
3.用表代替索引的功能
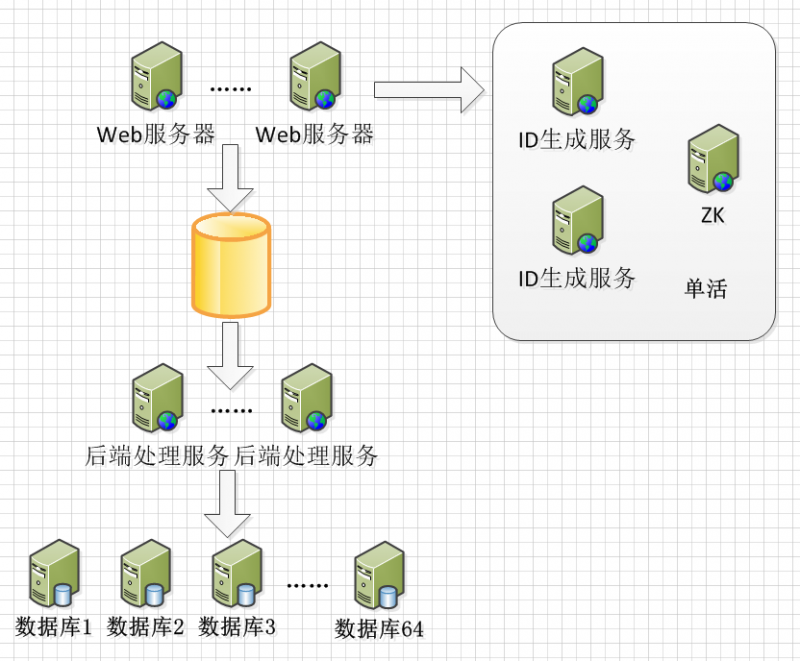
首先,还是基于分库分表.订单表按照用户ID mod 64 分到不同的服务器上(按照查询最多的维度分)。
数据库服务器1 的数据库名称为 db_1
数据库服务器2 的数据库名称为 db_2
...
以db_1为例,创建如下表
1.订单表
TS_ORDER_1 分区表,每个月一个分区.
2.事务表
create table tran_log_1(
tran_id bigint primary key,
param varchar(2000)
);
分区表,每个月一个分区.
3.消息表
create table msg_log_1(
tran_id bigint,
shardKey varchar(20) not null,
primary key(tran_id,shardKey)
);
分区表,每个月一个分区.
4.维度索引表
create table shard_shop_1(
id bigint primary key auto_increment,
shopid int,
ts timestamp,
state int,
dbid int,
orderid bigint,
index(shopid,ts,state)
);
分区表,每个月一个分区.
关于使用事务表,消息表实现分库分表最终一致性请参考
http://blog.itpub.net/29254281/viewspace-1819422/
关于集群主键生成服务请参考
http://blog.itpub.net/29254281/viewspace-1811711/
订单创建的流程
Web服务器接收到用户订单,首先通过RPC获取一个事务ID(tran_id).
用事务ID mod 64 找到数据库服务器,
将事务ID,参数写入tran_log 表,
然后将事务ID,参数写入消息队列.
如果写入消息队列成功,则提交事务.否则回滚事务.
此时就可以返回用户界面.
后端处理服务收到消息队列的信息,首先查询tran_log 表,是否存在这个事务ID,如果不存在则不予处理.
然后将队列的消息,分为两个维度分别处理,一个是用户维度,一个是商户维度.
作为用户维度,
先根据用户ID mod 64 找到最终落地的数据库,查询那个数据库的消息表msg_log,在用户维度,是否存在这个事务ID,如果存在,则不予处理.
(select count(*) from msg_log_XX where shardKey='订单创建:用户维度' and tran_id=?)
如果不存在,则开启一个事务
插入订单表,我觉得可以用tran_id直接作为订单的ID,
并且插入消息表 insert msg_log_XX(tran_id,shardKey) values(?,'订单创建:用户维度');
提交事务,commit.
作为商户维度,
则根据商户ID mod 64 找到最终的数据库,和用户维度的数据库,可能不是同一台服务器.
同样,也是先查询落地数据库的消息表,
(select count(*) from msg_log_XXX where shardKey='订单创建:商户维度' and tran_id=?)
如果不存在记录,则开启事务,
插入维度索引表,
insert into shard_shop_XXX(shopid,ts,state,dbid,orderid) values(......)
shopid,ts,state 商户ID,订单时间,订单状态都是根据订单的原始信息.
dbid 指的是 根据用户维度(主维度),订单数据所在的数据库ID,
orderid 指的是 在用户维度(主维度),订单表的主键.
插入消息表,insert msg_log_XX(tran_id,shardKey) values(?,'订单创建:商户维度');
最后提交.
这样,作为商户维度查询的时候,先根据商户的ID mod 64 找到 维度索引表,获取该商户的订单信息
select * from shard_shop_1 where shopid=? and state=2 order by ts limit 300,10;
获取的信息可能如下
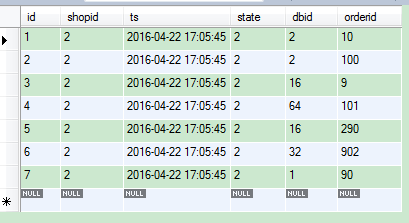
可以看到,符合条件的订单信息,分别来自 服务器1,2,16,32,64
获取了这部分信息,就可以直接去这些服务器上取数据,并且是主键查询,速度很快.
每隔一段时间,由后台程序,查看 tran_log和msg_log,如果发现有缺失的数据,则进行事务补偿.
扩展的时候,则新增维度索引表即可.
因为所有的表,都是按月的分区表,可以将过去的冷数据,在一个服务器集中存放,这个实例就同时存放64个数据库.毕竟都是冷数据,访问量很小.
能分还要能合.比如:


以订单表为例, 按照用户ID mod 64 分成 64个数据库.
按照用户的维度查询很快,因为最终的查询落在一台服务器上.
但是如果按照商户的维度查询,则代价非常高.
需要查询全部64台服务器.
在分页的情况下,更加恶化.
比如某个商户查询第10页的数据(按照订单的创建时间).需要在每台数据库服务器上查询前100条数据,程序收到 64*100 条数据,然后按照订单的创建时间排序,截取排名90-100号的10条记录返回,然后抛弃其余的6390条记录.如果查询的是第100页,第1000页,则对数据库IO,网络,中间件CPU,都是不小的压力.
分库分表之后,为了应对多维度查询,很多情况下会引入冗余.
比如两个集群,一个按照用户ID分库分表,另外一个按照商户ID分库分表.
这样多维度查询的时候,各查各的.
但是有几个问题,一样不好解决.
比如,
每扩展一个维度,就需要引入一个集群.
集群间的数据,如何保证一致性.
冗余占用大量磁盘空间.
从朋友那里看到的订单表结构.做冗余会占用大量的磁盘空间.
- create table TS_ORDER
- (
- ORDER_ID NUMBER(8) not null,
- SN VARCHAR2(50),
- MEMBER_ID NUMBER(8),
- STATUS NUMBER(2),
- PAY_STATUS NUMBER(2),
- SHIP_STATUS NUMBER(2),
- SHIPPING_ID NUMBER(8),
- SHIPPING_TYPE VARCHAR2(255),
- SHIPPING_AREA VARCHAR2(255),
- PAYMENT_ID NUMBER(8),
- PAYMENT_NAME VARCHAR2(50),
- PAYMENT_TYPE VARCHAR2(50),
- PAYMONEY NUMBER(20,2),
- CREATE_TIME NUMBER(20) not null,
- SHIP_NAME VARCHAR2(255),
- SHIP_ADDR VARCHAR2(255),
- SHIP_ZIP VARCHAR2(20),
- SHIP_EMAIL VARCHAR2(50),
- SHIP_MOBILE VARCHAR2(50),
- SHIP_TEL VARCHAR2(50),
- SHIP_DAY VARCHAR2(255),
- SHIP_TIME VARCHAR2(255),
- IS_PROTECT VARCHAR2(1),
- PROTECT_PRICE NUMBER(20,2),
- GOODS_AMOUNT NUMBER(20,2),
- SHIPPING_AMOUNT NUMBER(20,2),
- ORDER_AMOUNT NUMBER(20,2),
- WEIGHT NUMBER(20,2),
- GOODS_NUM NUMBER(8),
- GAINEDPOINT NUMBER(11) default 0,
- CONSUMEPOINT NUMBER(11) default 0,
- DISABLED VARCHAR2(1),
- DISCOUNT NUMBER(20,2),
- IMPORTED NUMBER(2) default 0,
- PIMPORTED NUMBER(2) default 0,
- COMPLETE_TIME NUMBER(11) default 0,
- CANCEL_REASON VARCHAR2(255),
- SIGNING_TIME NUMBER(11),
- THE_SIGN VARCHAR2(255),
- ALLOCATION_TIME NUMBER(11),
- SHIP_PROVINCEID NUMBER(11),
- SHIP_CITYID NUMBER(11),
- SHIP_REGIONID NUMBER(11),
- SALE_CMPL NUMBER(2),
- SALE_CMPL_TIME NUMBER(11),
- DEPOTID NUMBER(11),
- ADMIN_REMARK VARCHAR2(1000),
- COMPANY_CODE VARCHAR2(32),
- PARENT_SN VARCHAR2(50),
- REMARK VARCHAR2(100),
- GOODS CLOB,
- ORIGINAL_AMOUNT NUMBER(20,2),
- IS_ONLINE CHAR(1),
- IS_COMMENTED CHAR(1) default 0,
- ORDER_FLAG CHAR(1) default 1
- )
可以试试用表代替索引的方法.
1.分库分表
2.最终一致性
3.用表代替索引的功能
首先,还是基于分库分表.订单表按照用户ID mod 64 分到不同的服务器上(按照查询最多的维度分)。
数据库服务器1 的数据库名称为 db_1
数据库服务器2 的数据库名称为 db_2
...
以db_1为例,创建如下表
1.订单表
TS_ORDER_1 分区表,每个月一个分区.
2.事务表
create table tran_log_1(
tran_id bigint primary key,
param varchar(2000)
);
分区表,每个月一个分区.
3.消息表
create table msg_log_1(
tran_id bigint,
shardKey varchar(20) not null,
primary key(tran_id,shardKey)
);
分区表,每个月一个分区.
4.维度索引表
create table shard_shop_1(
id bigint primary key auto_increment,
shopid int,
ts timestamp,
state int,
dbid int,
orderid bigint,
index(shopid,ts,state)
);
分区表,每个月一个分区.
关于使用事务表,消息表实现分库分表最终一致性请参考
http://blog.itpub.net/29254281/viewspace-1819422/
关于集群主键生成服务请参考
http://blog.itpub.net/29254281/viewspace-1811711/
订单创建的流程
Web服务器接收到用户订单,首先通过RPC获取一个事务ID(tran_id).
用事务ID mod 64 找到数据库服务器,
将事务ID,参数写入tran_log 表,
然后将事务ID,参数写入消息队列.
如果写入消息队列成功,则提交事务.否则回滚事务.
此时就可以返回用户界面.
后端处理服务收到消息队列的信息,首先查询tran_log 表,是否存在这个事务ID,如果不存在则不予处理.
然后将队列的消息,分为两个维度分别处理,一个是用户维度,一个是商户维度.
作为用户维度,
先根据用户ID mod 64 找到最终落地的数据库,查询那个数据库的消息表msg_log,在用户维度,是否存在这个事务ID,如果存在,则不予处理.
(select count(*) from msg_log_XX where shardKey='订单创建:用户维度' and tran_id=?)
如果不存在,则开启一个事务
插入订单表,我觉得可以用tran_id直接作为订单的ID,
并且插入消息表 insert msg_log_XX(tran_id,shardKey) values(?,'订单创建:用户维度');
提交事务,commit.
作为商户维度,
则根据商户ID mod 64 找到最终的数据库,和用户维度的数据库,可能不是同一台服务器.
同样,也是先查询落地数据库的消息表,
(select count(*) from msg_log_XXX where shardKey='订单创建:商户维度' and tran_id=?)
如果不存在记录,则开启事务,
插入维度索引表,
insert into shard_shop_XXX(shopid,ts,state,dbid,orderid) values(......)
shopid,ts,state 商户ID,订单时间,订单状态都是根据订单的原始信息.
dbid 指的是 根据用户维度(主维度),订单数据所在的数据库ID,
orderid 指的是 在用户维度(主维度),订单表的主键.
插入消息表,insert msg_log_XX(tran_id,shardKey) values(?,'订单创建:商户维度');
最后提交.
这样,作为商户维度查询的时候,先根据商户的ID mod 64 找到 维度索引表,获取该商户的订单信息
select * from shard_shop_1 where shopid=? and state=2 order by ts limit 300,10;
获取的信息可能如下
可以看到,符合条件的订单信息,分别来自 服务器1,2,16,32,64
获取了这部分信息,就可以直接去这些服务器上取数据,并且是主键查询,速度很快.
每隔一段时间,由后台程序,查看 tran_log和msg_log,如果发现有缺失的数据,则进行事务补偿.
扩展的时候,则新增维度索引表即可.
因为所有的表,都是按月的分区表,可以将过去的冷数据,在一个服务器集中存放,这个实例就同时存放64个数据库.毕竟都是冷数据,访问量很小.
能分还要能合.比如:
正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](http://www.liuhaihua.cn/img/qrcode_gzh.jpg)

