python模拟登录博客园并爬取用户粉丝数
1.模拟登录博客园
我们用chrome监控登录界面,选到network那一栏。 点击登录后发现信息里面并没有我们想要的登录时post的信息。 但是可以发现在点击的一瞬间是有一个这个文件的,

但是切换页面之后就没有了, 手快一点按ctrl+e可以捕获到....用一些抓包工具应该也可以, 但是我还不太会。
然后点击signin那个文件, 可以看到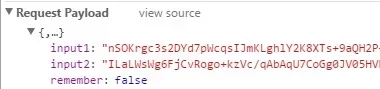
这样我们想要的登录信息就有了。
data = { 'input1':'你获得的input1', 'input2':'你获得的input2', 'remember':'false' }然后登录就好
url = 'http://passport.cnblogs.com/user/signin' requests.post(url, data = data, headers = headers) # headers里面是cookie, user-agent, accept和refer2. 爬取用户的粉丝数量
大概思想就是bfs, 用一个队列, 从我出发,先将我自己加入队列。 找到我的关注者, 然后将我的关注者加入队列, 然后不断循环。期间用了set来判重, 因为可能有很多人关注了同一个人的情况。
爬一个人的关注者的时候, 如果一个人关注的人很多, 那么就是很多页来显示。 发现一页可以显示45个他关注的人, 所以页数就是他关注的人数/45然后向上取整, 用ceil函数就可以。
#baseUrl = 'http://home.cnblogs.com/u/id/' def getUrls(baseUrl, page_num): ret = [] for page in range(1, page_num+1): url = baseUrl+str(page) wb_data = req.get(url, headers = headers) soup = BeautifulSoup(wb_data.text, 'lxml') urls = soup.select('#main ul .avatar_name a') for item in urls: ret.append(item) return ret这样就可以将他的关注者的主页链接全都加入到一个列表里面。
代码写的超级丑并且没写异常捕获..我在bfs的时候加了一个cnt来控制抓取的人数, 不加的话就是将所有信息抓完才停, 实在有点慢...
from bs4 import BeautifulSoup import requests import queue import math req = requests.Session() s = set() data = { 'input1': 'input1', 'input2': 'input2', 'remember':'false' } headers = { 'User-Agent' : 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/49.0.2623.112 Safari/537.36', 'Referer':'http://home.cnblogs.com/u/yohaha/followers/', 'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8', 'Cookie':'__gads=ID=242d857f42405107:T=1461752712:S=ALNI_MYx-fX1RCbXzt0qM78IcU2PYuuw2A; _gat=1; .CNBlogsCookie=44310FE3A99973E1AF1BF7C7D716262617D36C9AAC9BB954269053FE51E2C9A1DDE06EA53089E7F03298E1C36C2CF89FDF71A6165725AED17040D66EA2AFD6430A627C12B187CD6F23E7635F914AC15BD6D0FD2C; _ga=GA1.2.8402864.1461752940' } def getUrls(baseUrl, page_num): ret = [] for page in range(1, page_num+1): url = baseUrl+str(page) wb_data = req.get(url, headers = headers) soup = BeautifulSoup(wb_data.text, 'lxml') urls = soup.select('#main ul .avatar_name a') for item in urls: ret.append(item) return ret def login(): url = 'http://passport.cnblogs.com/user/signin' requests.post(url, data = data, headers = headers) def crawer(): baseUrl = 'http://home.cnblogs.com' q = queue.Queue() q.put('http://home.cnblogs.com/u/yohaha/') s.add('http://home.cnblogs.com/u/yohaha/') cnt = 0 l = [] login() while not q.empty() and cnt < 100: url = q.get() cnt = cnt + 1 wb_data = req.get(url, headers = headers) soup = BeautifulSoup(wb_data.text, 'lxml') name = str(soup.select('#user_profile_block > table > tbody > tr > td > div > h1')[0].get_text()) name = name.strip('/r/n/t/t/t/t/t/t/t') num = int(soup.select('#follower_count')[0].get_text()) #粉丝的数量 page_num = math.ceil(int(soup.select('#following_count')[0].get_text())/45) #关注的人的页数 data = { 'name': name, 'followersNum': num, 'url': url } l.append(data) url = baseUrl+soup.select('.data_left #following_count ')[0].get('href') urls = getUrls(url, page_num) for url in urls: newUrl = baseUrl+url.get('href') if newUrl not in s: #判重 q.put(newUrl) s.add(newUrl) return l l = crawer() l = sorted(l, key = lambda x:x['followersNum'], reverse = True) for info in l: print(info)正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](http://www.liuhaihua.cn/img/qrcode_gzh.jpg)

