Twitter的监控技术概览(下)
【编者的话】Twitter的监控团队为其内部工程团队提供了全栈的库和多个服务。而其监控技术也为网站发展提供了很好的支持。近日,Twitter的高级技术经理Anthony Asta就在 官方博客中发文 分享了Twitter的监控技术的概况,希望读者可以从中有所收获。
这是有关Twitter的监控工程的系列文章的第二部。在这篇文章中,我们讨论可视化、警告、分布式追踪系统、日志聚合/分析平台、利用率以及学习到的教训。
可视化
虽然收集和存储数据非常重要,数据对我们工程师而言仍然没有任何意义,除非它被可视化呈现使得工程师能够马上识别出其中的关联。工程师使用CQL查询语言来在一个浏览器内绘制时间序列数据的图表。在一个监控产品中,一个图标是最基本也是肯本性的可视化单元。图表通常称会被嵌入或组织进仪表盘中,但它也可以进行特殊创建,以在执行一个部署或诊断事故的时候能够快速分享信息。此外,工程师可以使用的还包括一个创建仪表盘所使用的命令行工具、可重用监控组件的库以及一个自动化所用的API。
我们通过统一可视化和警告的配置改善了用户监控数据的认知模型。警告只是应用于与可视化和诊断所使用的相同的时间序列数据的预测。由于所有相关的数据都在一个地方,这使得工程师们可以更加容易的解释服务的状态。
(点击放大图像)
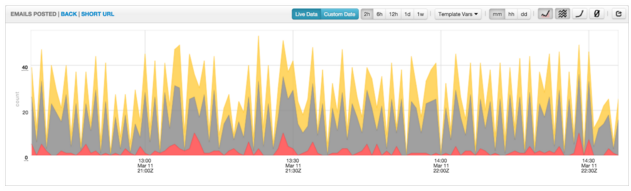
仪表盘和图表携带了很多工具来帮助工程师深入了解他们所包含的量度。它们可以利用栈来改变数据的排列和表示方式,填充选项;它们可以在线性和log图表尺度间切换;它们还可以选择不同的时间粒度(每分钟、每小时或每天)。此外,当数据进入流水线或潜回历史数据时,工程师还可以选择近乎实时的查看。在不同的办公室,这些仪表盘就出现在大屏幕或一个工程师的显示器上。Twitter的工程师就生活在这些仪表盘中。
(点击放大图像)
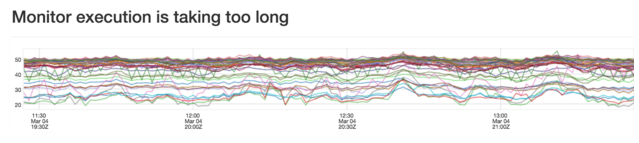
在可视化的用例的,每个仪表盘可以包含上百个图表,而每个图表又可能包含上千个数据点。为了满足所需的浏览器图表性能,我们开发了一个内部使用的的图表库。
警告
当服务降级或损坏时,我们的警告系统将情况告诉给工程师。为了使用警告,工程师在量度上设置了条件。当这些条件满足时,我们提醒工程师。
据评估,警告系统每分钟处理超过25000个警告。考虑到可扩展性和在节点失效时失效备援的冗余性,警告评估被划分到不同的盒子中。
尽管我们之前的系统能够很好的服务Twitter,我们还是迁移到了一个新的分布式警告系统中。这带来的额外好处有:
- 在区域失效时的跨数据中心的警告失效备援
- 在节点失效时的警告评估
- 警告执行隔离,使得一个错的警告并不会影响其他的警告
- 无影响的部署,使得用户不会损失可视能力
- 用于警告和可视化配置的统一对象模型
可视化服务允许工程师与警告系统进行交互,并为查看警告状态、参考运行手册以及暂停警告等行动提供了一个UI。
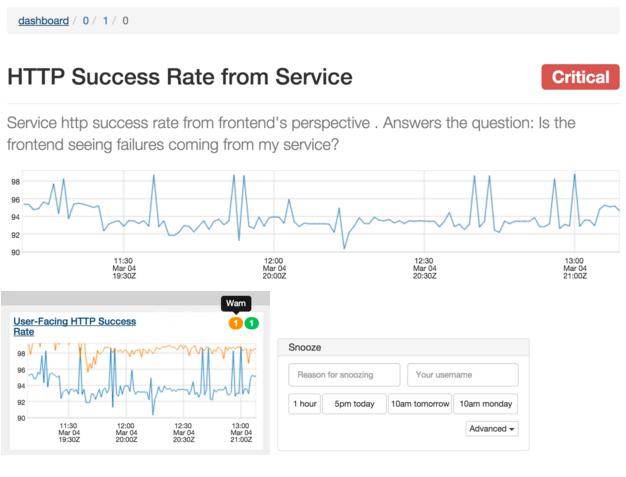
动态配置
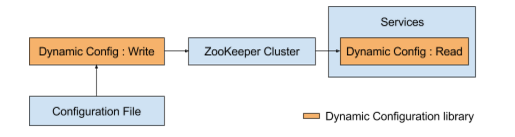
随着我们的系统变得越来越复杂,我们需要一个轻量级的机制来将配置变化配置到大量的服务器中,使得我们能够在不重启服务的情况下快速替换为开发进程的一部分。我们的动态配置库提供了一种部署和升级针对Mesos/Aurora服务及部署在专门机器上的服务的配置的标准方法。该库采用Zookeeper作为配置的信任源。我们使用一个命令行工具来解析配置文件,并在Zookeeper内更新配置数据。依赖该数据的服务会在几秒内收到有关变化的一个通知:
分布式追踪系统(Zipkin)
由于我们团队的工程师数量有限,我们曾想加入日益壮大的、致力于OSS Twitter Zipkin 的Zipkin开源社区来加速我们的开发速度。结果,监控团队决定通过 Open Zipkin项目 来彻底开源Zipkin。从此,我们开始与开源社区合作建立控制和框架模型以保证改变能够被规律性的评阅、合并和发布。这些模型被证明非常好:380个下拉请求已经在8个月内被合并到70个社区推动的版本中。所有的文档和通信也都起源于Open Zipkin社区。未来,Twitter会将来自 Open Zipkin项目 的zipkin版本直接部署到产品环境中。
日志聚合/分析平台
LogLens是一个提供服务日志的索引、检索、可视化以及分析的服务。它的灵感来源于存在于开发者在运行Aurora/Mesos上的服务时的感受中的两个特殊的差距。
- 服务日志的生命与任务被调度到的瞬态资源容器的生命之间的耦合导致了我们在针对日志丢失引起的事故进行分流时的很多不确定。
- 在快速检索构成一个服务的很多组件所产生的所有独特日志时的困难增加了实时事故的反应时间。
Loglens服务的优先级从高到低排序如下:部署的简易性,实时日志的可用性,花销,旧日志的可用性和在有限的开发者投资的情况下可靠操作服务的能力。
客户可以通过一个自助的入口来部署它们的服务。该入口为他们能力和突发头空间有限的服务日志提供了一个索引。日志可以保存在HDFS 7天,一个缓存节点实时服务最近24小时的日志,而更老的日志按需提供。
利用率
随着Twitter和监控技术的发展,服务拥有着希望看到他们对我们平台的使用情况。我们将所有的读写请求保存到了Cuckoo,然后使用它们去计算一个简单的利用率量度——读/写率。这一追踪数据也可以用于我们的发展规划和能力规划中。
我们的数据流水线以天为单位来聚合时间数据,而且我们将输出存储在HDFS和Vertica中。我们的用户可以通过三种不同的方式来访问这些数据。首先,我们会给每个团队发送周期性的使用和利用报告。其次,用户可以利用Tableau将Vertica数据进行可视化,从而允许他们对数据进行深入分析。最后,我们还提供了一个带有详细可执行建议的Utilization API。除了显示基本的利用情况和使用情况的数字,该API还被设计为可帮助用户发觉哪些特定组的量度还没有被使用。
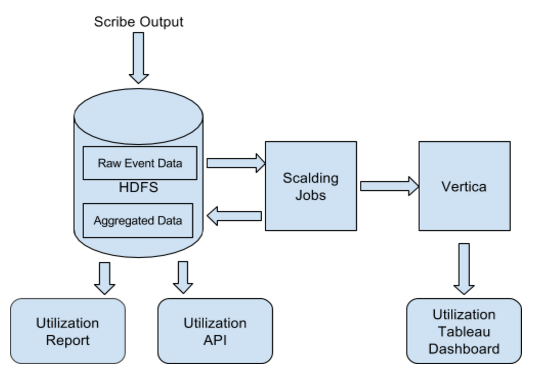
由于该想法已经发挥作用,这些工具已经允许用户利用两种方法来跨越读和写之间的缝隙——通过仅仅减少他们写的未使用的量度的数量或通过将单独的量度替换为聚合的量度。结果,一些团队已经能够将其量度的数量减少一个量级。
学习到的教训
- 量度收集中的“推”vs“拉”:在我们编写上次博客的时候,我们的所有量度都是从我们的收集代理中“拉”下来的。我们发现了两个问题:
- 没有简单的方法可以区分服务失效和收集代理失效这两种情况。服务响应超时和丢失的收集请求都表现为空的时间序列。
- 我们的收集流水线缺少服务质量隔离。针对各种服务,很难设定一个最优的收集超时的阈值。一个服务的收集时间比较长可以引起使用相同收集代理的其他服务的延迟。
在这种情况下,我们将收集模型从“拉”换为了“推”,增加了我们的服务隔离。每一个宿主上的收集代理只收集运行在该宿主上的服务的量度。此外,除了由服务发出的量度,每一个收集代理分别发送收集的状态追踪量度。
通过这些改变,我们看到了明显的收集可靠性的改善。然而,随着我们转向自助的“推”模型,计划请求的增长情况变得更加困难了。为了解决该问题,我们计划实现服务定额以解决不可预测/没有限制的增长。
- 容错:作为Twitter最关键服务的其中一种,我们需要在即使发生数据中心失效等灾难性故障时,也能够提供高可用的监控服务。为了达到该目标,我们遵循了两个原则:
- 跨DC的冗余:一些最关键的量度发送到不止一个数据中心中进行冗余备份。这使得我们可以对抗单数据中心失效的情况。
- 消除/解耦合对其他库/服务的非必需的依赖:在我们的有些开发过程中,我们有意的移除了对一些广泛使用的Twitter Front End、TFE等内部框架的依赖,以避免这些系统失效引起的宕机事件。在其他情况下,我们使用Manhattan和Zoo专门的集群和实例来将我们的失效和我们所监控服务的失效解耦合开来。
更多信息
想了解更多关于构建Twitter的监控栈所遇到的挑战可以关注以下内容:
- Caitie McCaffrey 的 Twitter Flight 2015 演讲
编后语
《他山之石》是InfoQ中文站新推出的一个专栏,精选来自国内外技术社区和个人博客上的技术文章,让更多的读者朋友受益,本栏目转载的内容都经过原作者授权。文章推荐可以发送邮件到editors@cn.infoq.com。
感谢杜小芳对本文的审校。
给InfoQ中文站投稿或者参与内容翻译工作,请邮件至editors@cn.infoq.com。也欢迎大家通过新浪微博(@InfoQ,@丁晓昀),微信(微信号: InfoQChina )关注我们。
正文到此结束
热门推荐










相关文章

近期评论
-
你这基本没有更新呀,最近文章显示还是2019年的文章。不符合要求哈
-
关键词:慕云博客 链接:https://www.lilun.me 描述:分享原创文字的个人博客
-
-
-
可以提供一下源码吗
-
不是商业站,鸡娃学习笔记
-
-
-
-
听他们说很厉害的样子
Loading...
![[HBLOG]公众号](http://www.liuhaihua.cn/img/qrcode_gzh.jpg)

