Twitter开源分布式高性能日志复制服务
日前,Twitter 在 Github 上基于 Apache 2 许可证协议开源了其日志服务 DistributedLog(DL)。DL 是一个高性能的日志复制服务,提供了持久化、复制以及强一致性的功能,这对于构建可靠的分布式系统都是至关重要的,如复制状态机(replicated-state-machines)、通用的发布/订阅系统、分布式数据库以及分布式队列。
DistributedLog 会分类维护记录的序列(sequences of records),并将其称为 Log(又叫做 Log Stream),将记录写入到 DL Log 的进程称之为 Writer,从 Log 中读取并处理记录的进程称之为 Reader。因此,它整体的软件栈如下所示:

具体来讲,它包含如下几个组成部分:
Log
Log 是有序的、不可变的日志记录(log record),它的数据结构如下所示:
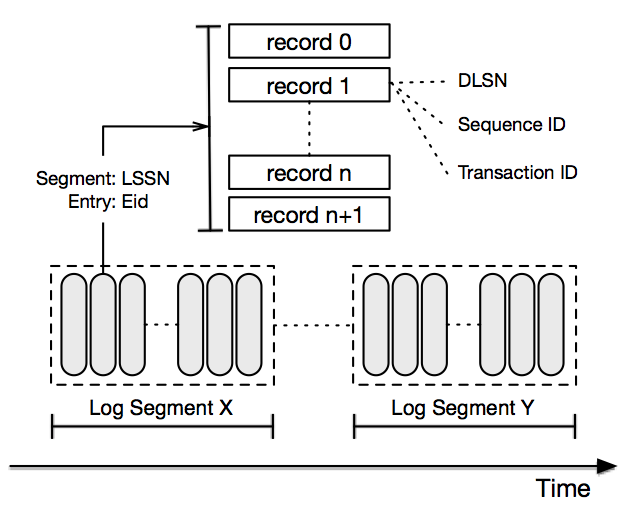
日志记录
每条日志记录都是一个字节序列。日志记录会按照序列写入到日志流中,并且会分配一个名为 DLSN(分布式序列号,DistributedLog Sequence Number)的唯一序列号。除了 DLSN 以外,应用程序还可以在构建日志记录的时候设置自己的序列号,应用程序所定义的序列号称为 TransactionID(txid)。不管是 DLSN 还是 TransactionID 都能用来定位 Reader,使其从特定的日志记录开始读取。
Log 分段(Log Segments)
Log 会被分解为 Log 分段,每个分段中包含了其记录的子集。Log 分段是分布式的,应该放到 Log 分段存储中(如 BookKeeper)。DistributedLog 会基于配置好的策略来轮询每个 Log 分段,要么是可配置的时间段(如每两个小时),要么是可配置的最大规模(如每 128MB)。所以 Log 的数据将会分为同等大小的 Log 分段,并且均匀分布到 Log 分段存储节点上。这样,Log 的存储就不会局限于单台服务器的限制,同时,能够在集群中分散读取的流量。
Log 的数据可以永远保存,直到应用程序显式地将其截断,也可以在一个可配置的时间段内保存。对于构建复制状态机来说,显式截断会非常有用,如分布式数据库。在数据何时能够截断这一点上,它们往往有着严格的控制。基于时间保留 Log 对于实时分析的场景更为有用,它们只关心一定时间内的数据。
命名空间
属于同一组织的 Log 流通常会归类在同一个命名空间(namespace)下,并据此进行管理。DL 的命名空间基本上就是用来定位 Log 流在何处的。应用程序可以在某个命名空间下创建和删除流,也能将某个流截断到给定的序列号上(DLSN 或 TransactionID 均可以)。
Writer
Writer 会将数据写入到它们所选择的 Log 中。所有的记录都会按照顺序添加到 Log 之中。序列号是由 Writer 所负责的,这就意味着对于某个 Log,在给定的时间点上,只能有一个激活的 Writer。当出现网络分区(network partition),导致两个 Writer 试图往同一个 Log 进行写入的时候,DL 会保证其正确性,这是通过 Log 分段存储的屏障(fencing)来实现的。
Writer 由名为 Write Proxy 的服务层来提供和管理,Write Proxy 用来接受大量客户端的 fan-in 写入。
Reader
Reader 会从它们所选择的 Log 中读取记录,这会在一个给定的位置开始。这个给定的位置可以是 DLSN,也可以是 TransactionID。Reader 将会严格按照 Log 的顺序读取记录。在同一个 Log 中,不同的 Reader 可以在不同的起始位置读取记录。
与其他的订阅/发布系统不同,DistributedLog 并不会记录/管理 Reader 的位置,它将跟踪的任务留给了应用程序本身,因为不同的应用在跟踪和协调位置上可能会有不同的需求,很难用一种方式就将这些需求全部解决。在应用程序层面,借助各种存储(如 ZooKeeper、FileSystem 或 Key/Value 存储)能够很容易地跟踪 Reader 的位置。
Log 记录可以缓存在名为 Read Proxy 的服务层中,从而应对大量 Reader 的读取。
Fan-in 与 Fan-out
DistributedLog 的核心支持单 Writer、多 Reader 的语义。服务层构建在 DistributedLog Core 之上,支持大量的 Writer 和 Reader。服务层包含 Write Proxy 和 Read Proxy,Write Proxy 管理 Log 的 Writer,并且在机器宕机时,能够对它们进行故障恢复。它能够从众多来源聚集 Writer,允许不必关心 Log 的所有权(又称为 Fan-in)。Read Proxy 通过将记录放到缓存中,优化了 Reader 的读取路径,以应对成百上千的 Reader 读取同一个 Log 流的状况。
作为一个日志服务,DistributedLog 的优势可以总结为:
- 高性能:面对大量的并发日志时,在可持久化的 Writer 上 DL 能够提供毫秒级的延迟,同时还能应对上千客户端每秒大量的读取和写入操作。
- 持久化和一致性:消息会持久化到磁盘上,并且以副本的形式存储多份,从而避免丢失。通过严格的顺序,保证 Writer 和 Reader 之间的一致性。
- 各种工作负载:DL 支持各种负载,包括延迟敏感的在线事务处理(OLTP)应用(如分布式数据库的 WAL 和基于内存的复制状态机)、实时的流提取和计算以及分析处理。
- 多租户:针对实际的工作负载,DL 的设计是I/O隔离的,从而支持多租户的大规模日志。
- 分层架构:DL 有一个现代化的分层设计,它将有状态的存储层与无状态的服务提供层进行了分离,能够使存储的扩展独立于 CPU 和内存,因此支持大规模的写入 fan-in 和读取 fan-out。
关于 DistributedLog 的概要架构、详细设计以及使用过程,可以参考其 Github 上的文档。
正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](http://www.liuhaihua.cn/img/qrcode_gzh.jpg)

