机器学习助力神经科学的高维数据分析,两者如何相互激励与促进
引言:神经科学家正在生产庞大规模的数据组,其复杂性堪比真实世界中的分类任务。机器学习已经大大帮助了数据分析,但是,其准确性经常不如人类进行的数据分析。本文中,作者讨论了受神经科学启发的机器学习所面临的挑战以及希望。
当有机体在环境中行动时,有机体大脑负责处理高维感官数据。因此,从事大脑研究的神经科学家需要处理极其复杂的高维数据集,这给分析工作带来不小的挑战。一个最明显的例子,在高分辨率神经联接组学(connectomics)这个新领域中, 3D 电子显微镜(EM)数据集正突破拍字节(PB)大关。
冷知识:connectomics(联接组学)是近年来一系列生命科学研究中「xx组学」的一支,譬如就有大家很熟悉的基因组学。意识从何而来?思维和智能是如何出现的?这些终极问题都蕴藏在大脑里面。联接组学是一个对大脑进行的逆向工程研究,希望研究明白大脑是怎么被建造的,而后就可以再建模拟的「大脑」,人工智能也许会因此而真正实现。
分析这些数据是个很大的挑战,而且只有使用机器学习技术,才能实现对这些数据集的重构(reconstruction)。功能成像或行为跟踪数据也需要实质性自动分析,构建其它机器学习算法可以处理的实例。这一观点不仅阐明了机器学习帮助神经科学家的方式,也说明了在许多相关背景中,我们为何仍然设计不出与人类数据分析一样强大的算法。文章最后,我对揭秘感官大脑皮层的专门算法进行了讨论,最终,这将给我们提供有关生物算法的洞见(这是目前所缺乏的),进而启迪下一代高性能机器学习。
高维数据分类
门牌号或鸟类的分类等日常任务,对人类来说,不过小菜一碟,但在概念上却让人印象深刻;将一张图片识别为「鸟」或「蝇」意味着需要将大量可能的图像(在彩色 92×92 像素图像的情况下需要 10^66583 张)压缩到几十个分类中(见图 1A)。我们可以将这些图像描述作高维数据(high-dimensional data):92×92 像素中的每一个像素都可以独立变化,因此,这些数据所表现出来的维度(92×92=8,464)是相当高的。另一方面,分类的结果往往只有 1 维(1D,在数字的情况下是 10 个可能分类[0,1,2,…]中的一个)。因此,分类(classification)意味着发现巨大的可能数据实例空间中的结构。
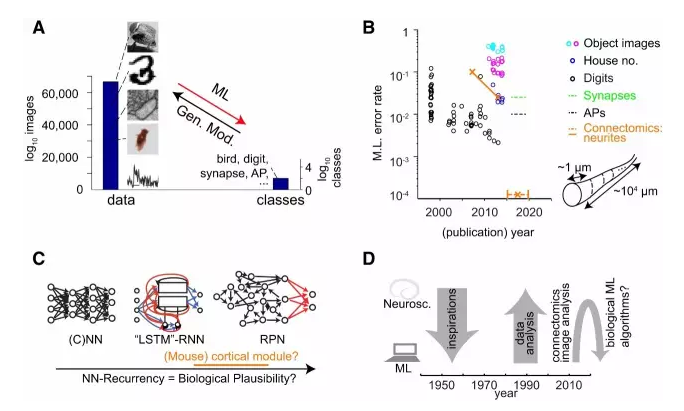
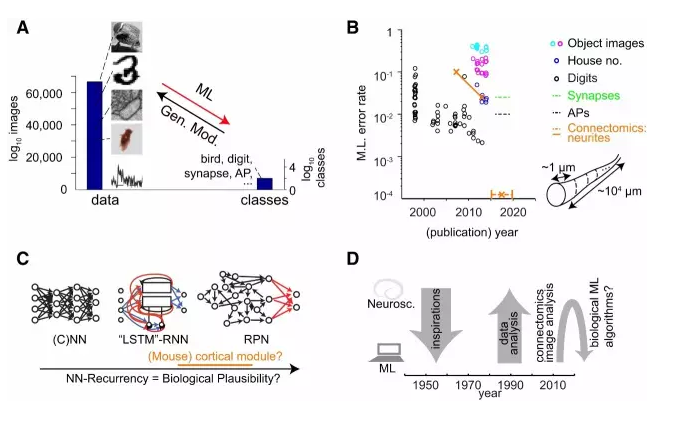
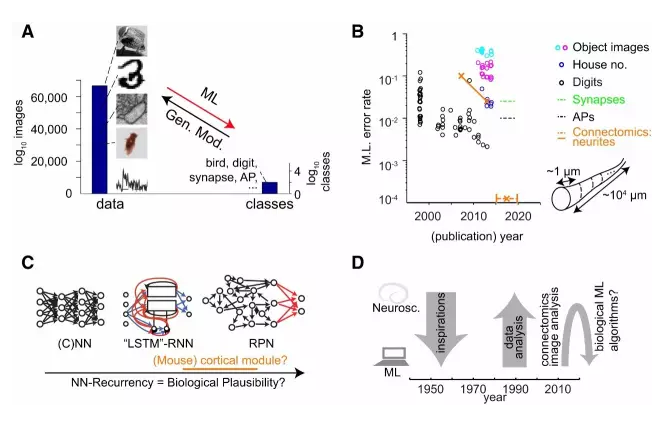
图1:用于真实世界和神经科学数据分析的机器学习
(A) 一个典型图像分析设置中的构象空间(conformation space):对比 24 位色彩深度 92×92 像素的可能图像的数量与潜在的对象分类的数量。样本图像来自 STL-10 基准数据集、MNIST 数据集(LeCun et al., 1998)、联接组学的电子显微镜数据、苍蝇运动的行为追踪软件(Kabra et al., 2013),以及由双光子显微镜在大鼠活的新皮层中记录的细胞内钙离子的瞬变现象。机器学习(ML)的目的是优化数据到分类的转换,而生成模型(Gen. Mod.)则是试图从潜在的分类中再现图像的生成。
(B) 从http://yann.lecun.com/exdb/mnist/和http://rodrigob.github.io/are_we_there_yet/build/编制的基准数据集(STL-10(Coates et al., 2011)、CIFAR-10、MNIST、SVHN)中的机器学习分类错误,加上已实现的(实线)和所需的(虚线)神经科学机器学习错误率。
(C) 生物学启发的机器学习分类器的类型。前馈网络(左)最初提出时是作为两层感知器(Rosenblatt, 1958),后来发展成了「深度」网络(如 , Hinton et al., 2006, LeCun et al., 1998)。带有特殊复发性规则的循环递归架构让他们可以有效地训练机器(中,LSTM 网络;Hochreiter and Schmidhuber, 1997)和被看作是回声状态、随机池(RPN)或液态机-RNN 的全循环递归网络(右,如 Maass et al., 2002)。我们目前还不清楚真正的哺乳动物大脑皮层网络中是否使用和执行了其中的任何架构。
(D) 机器学习和神经科学互相启发的简单时间轴:在生物计算器件(biological computing devices)的技巧方面,神经科学能指导机器学习吗?
在神经科学中,随着高通量记录技术的广泛应用,数据分析之难,堪比联接组学中使用 3D 电子显微镜检测突触和神经突等难题。其它的例子包括使用高分辨率摄像追踪苍蝇、鼠、鼠须或胚胎细胞;从大规模电极中分析峰值数据;或从基于钙离子的瞬变现象中检测动作电位。
在所有这些案例中,教会计算机分析,极富价值,不管是为了真实世界中的自动对象识别,还是为了在神经科学实验中增加数据吞吐量以免于过于费时的分析,而这些又会让新的技术(细胞体检测与追踪、联接组学、动物追踪)成为可能。在一些情况中,当专家级神经学家也感到为难时,为了得到一致的结果就需要自动化的分析(例如,在峰值检测、大规模峰值数据、基因序列比较中)。
机器学习
机器怎样才能分析如此高维的数据?一种方法,将高维输入数据转换成更低维输出的过程看作是一个函数,然后配置该函数的参数,再优化这些参数以得到该转换过程的最好近似。这种方法不需要关于图像如何生成的知识(如:鸟来自于鸟的分类)或噪声源如何相关的知识。唯一必要的是标签(label),即分类所属已知的图像样本。然后通过调整(或「学习」)基于这些标签的参数来优化从高维输入向低维输出的转换过程(见图 1A 红色箭头)(所以这种方式被称为训练数据)。鉴于一些实现这种优化的架构启发自神经元网络,而且因为这种参数调整涉及到样本转换的演示,所以这种方法通常被称为「机器学习(machine learning)」。
基于模型的分析和无监督机器学习
另一种用于高维数据分析的方法与上面的方法相反:并不拟合数据到分析的转换,而是尝试从已知的分类或对象中,对数据生成建模(图 1A,黑色箭头)。这需要数据生成和噪声源方面的大量现有的知识,但在理想情况下,它只需要一点点有标签数据,甚至说不需要。在这种方法中,模型包含了代表所关注的分析结果的参数,而且这些参数是为匹配数据而非输出而进行优化的。以细胞内钙瞬变的功能成像数据的分析为例(图 1A)。这些钙瞬变(和关注的分析结果)的来源是体细胞在一定时间点发生的动作电位(AP)。钙离子大量涌入引起动作电位的改变,钙离子和相应蛋白质受体结合,并因此产生了动态衰减——这个转换过程加上成像噪声源是相对好理解的。因此,描述「动作电位-钙的数据转换」的生成模型是受限良好的,并且通过优化动作电位时间点以生成最佳近似于测量数据的数据,就能获得该动作电位时间点作为结果。
这种基于模型的方法基本上不需要标签,而且该模型不是「学到的」,而是被研究者「知道的」。但我们可以将生成模型的参数看作是一个理想代码(完美编码钙瞬变的动作电位时间点)。在这种情况下,这种代码的知识是广义的生物物理学研究的结果,而且如果你感兴趣的是动作电位而非钙动态本身,那么,这种压缩就是完美的。这种所谓的无监督机器学习方法的目标是从数据中「学习」这样的代码。大脑不太可能明确使用了所有相关模型(也许被明确使用的是在基因编码上做了很长时间的代表的运动学模型(kinematic models),但肯定不是关于比如智能手机行为的模型)。对学习这种帮助分类或代表相关参数的相关编码的追求是直接开放的,而且无监督机器学习方法已经被用在了细胞外尖峰检测(如:词典学习)或典型的基准竞争中(结合无监督/监督式分类)。
机器学习分类器有多好?
为了说明机器学习分类器的性能改进,让我们考虑一个来自邮件信封上的手写数字的数据集(MNIST 数据集, LeCun et al., 1998)。这已经在机器学习研究中被用作了精确度提升的关键指标:错误率从 1998 年的大约 1%–2% 下降到了今天的大约 0.2%(即在大约 15 年内降低一个数量级)。尽管 0.2% 的错误率已经非常出色了,但在更复杂的数据集上(图 1B),最好的机器学习方法仍然比人类差大约一个数量级,例如街景数据中的门牌号识别或低分辨率的真实世界图像,这说明在许多真实世界环境中,机器分析仍比不过人类分析。

神经科学中的机器学习分析如何?绘制整个突触网络的雄心刺激了 3D 电子显微镜成像技术的发展,为联接组学产出了大规模的高分辨率图像数据集。人类标注者(包括专家和训练有素的非专业人士)可以如实地分析这些数据,但所有人工分析所耗费的时间,会使更大规模的回路重构变得不可能。图像数据分析上,向前迈出的关键一步是卷积神经网络(CNN)的使用。尽管重构的准确性仍远低于人类的准确性,但是,在第一个局部密集回路重构( locally dense circuit reconstruction)的实现过程中,自动化技术发挥了至关重要的作用:实现过程使用了现有的过滤器和学习过的特征检测器的组合;Helmstaedter et al. (2013)使用了 CNN 和分割程序序列。类似地,在行为追踪方面,机器学习分析已经重新出现,且比单纯基于模型的分析更灵活更通用。
用于联接组学的机器学习
和其它真实世界和神经科学的机器学习挑战相比,事实证明,联接组学是一个尤其艰难的问题(图 1B)。想想神经元连线的重构(图 1B 中的插图):大约每隔 1 μm,分类器(人类或机器)就必须正确地决定是否继续重构轴突以及怎么继续。考虑到轴突的路径长度只有10^4-10^5 μm,所以,即使要对一个单独的神经元进行符合实际的重构,有效的分类器错误率必须近似 10^-4-10^-5 。而目前,最好的分类器最好也只能在轴突路径长度上达到十分之一到四十分之一微米的数量级。图 1B说明了其含义:联接组学在分类器精度上还需要大约 2 个数量级的提升,才能合适地自动重构仅仅一个神经元;而要自动重构一整个老鼠的大脑,那还需要另外 7 个数量级的提升。对比一下这和分类 MNIST 数据集中相当受限的手写数字集合的自动化改进:它用去了大约 15 年时间获得了一个数量级的错误率提升。因此,在提升的绝对数量和关于所需速率的两方面,联接组学的挑战比其它机器学习基准艰巨几个数量级。
对标签的需求——人vs.机器
机器学习需要大量有标签的样本(训练数据)。在多数情况下,人类数据标准被认为是黄金标准,但手工生成的标签可能包含错误。其中有些错误与注意力有关,其它错误则可能更系统化。应该怎么解决这个问题?人类性能可以通过一致性流程得到大幅增强——在该流程中,标签的生成依据多个独立标注而非单独一个手工选择。当单人标记者错误中大部分是没有偏见且独立时,这种流程是尤其成功的(例如当错过神经元重构中的分支时)。在所有的情况下,人类标注需要进行交叉验证,以确保标签的解释处在所需的误差范围内。
这仍然是假定手动标注比自动标注更优,而自动标注必须要对计算机而非人类进行训练。但用人类生成的标签训练的分类器是否有可能超越人类的表现?在一些情况中,人类标注已经比自动标注差了;以来自钙瞬变的动作电位的检测为例,它没有合理的真实世界检测可以类比。因为潜在的模型在生物物理学上已得到了很好的理解,计算机有望成为比人类更好的分析设备,手动标注也会变得无关紧要。
因此,一旦有了足够正确的自动分析模型,计算机分析的表现原则上就可以超越人类。证明学习到的代码有足够描述能力,通常很难。
前馈 vs 递归( Recurrent )神经网络架构
现在,比较机器学习技术和合乎生物学的神经元网络(biologically plausible neuronal networks)。早期神经元网络让人想起感知机,带有一个输入层和一个输出层。五十多年以后,一项关键改进就是使用「深度」网络,它包含许多隐藏层(图中C),通过使用计算机科学提供的新学习策略,它还能够被训练,赢得了当今包括联接组数据分类在内的机器学习竞赛(ML competition)。所有这些仍然是严格的前馈架构。但是,大脑中的神经网络却是高度递归的(recursive)。因此,除了迫切需要深度网络,在机器学习领域,当训练这些网络已经成为常规作业后,递归神经网络( recurrent neuronal networks ,RNNs)的使用已经重新抬头。目前,在视觉或听觉序列的自动分析中,递归神经网络几乎是最成功的。
这些灵感源自大脑、但人为构想出的网络架构,有无可能实际上就位于大脑分类器的核心呢?我们是否已经获得了这方面的洞见呢?如此以来,我们要做的就是用更好、更高效的机器实现(machine implementation )去抗衡和战胜人类分析(正如更多乐观的机器学习支持者会赞同的那样)呢,还是说,我们仍然遗漏了某些演化已经发现(但人类认为还并未发现的)技巧?
发现大脑分类技巧的策略
超越遗传决定的硬连线(hard-wired)反应的感官分类器的关键回路,很有可能位于哺乳动物的大脑皮层。我们可以通过调查这些回路,来确定生物计算器件(biological computing devices )演化发展出来的算法解决方案吗?(图D)
感官外围的输入,经由丘脑神经抵达大脑初级感觉皮层。比如,啮齿动物初级体觉皮质(S1),这里神经支配的最大部分,都是以第 4,5,3 层的神经元为目标的。L4 ,是一个位于鼠类桶状皮层的独特聚类回路,接受并编码来自鼠类鼻尖触须的感觉输入。在一次突发表征扩充中( a sudden representational expansion),该回路包含2,000个神经元 ,相比之下,脑干和丘脑中,仅200个神经元负责同样的主要感官输入。L4 的神经元彼此高度联结的(20%-30% 成对发生的联接性,pairwise connectivity),而且它们的主要输出神经元位于 L2 和 L3 以及 L5。L4 第一阶段皮层回路的功能是什么呢?有人认为,增强丘脑输入就是它的主要目的。不过,仅为了增强信号而建立一个详尽的十倍(10-fold)回路扩充( circuit expansion),似乎不可能。
因此,合理的策略是,一开始就绘制老鼠 L4 桶状皮层的神经回路结构,将之作为第一个皮层计算模块。那些被推荐的机器学习架构中,有没有一款真的可用于这种计算模块中?如果有,主要数据显示(readouts)位于何处?L2/3或 L5?如何处理自顶到下(top-down)的输入?假设是传输到初级感官皮层,如果是这样的话,那么,传输到哪个区域?L4的大多数神经元都太过本地化(local),以致于不能接受经由L1的远程输入,但是,L2/3和L5的锥体神经元将其树突延伸到 L1,因此,大体上可以接收自顶而下(top-down)的输入。
单独绘制一个这样的皮层处理模块,已经限制了可以实现的机器学习架构的种类范围。为了将到单独(individual)回路模式与一般回路原理(circuit principles)区分开,有必要筛选出单独回路中不同皮层模块间、不同单独回路皮层模块间的不变量(invariants),还要筛选回路原理,这些原理或许就是不同感官皮层回路间的不变量,充当关键的感官模块:感觉,听觉和视觉(分别为 S1, A1, V1)
如今,在一种物种中,比如老鼠,这种「搜索不变量」几乎是可操作的。成像速度以及分析通量能力的提升,有望重构一个皮层模块,而且显然也需要筛选技术。有人可能会问,对于从算法上理解出众的人类分类能力来说,这是不是已经足够好了?事实上,老鼠的分类表现和现在的计算机算法差不多,不过,另一方面,详细绘制人类皮层网络仍然不现实,因为它的规模太大。
因此,我建议,下一个目标应该是,沿着物种轴线进行比较绘制研究( comparative mapping along the species axis )。绘制对象可以从老鼠(mouse)进阶到大一些老鼠 (rat),后者的学习表现更加高级,其大脑皮层的神经元数量增加了三倍,但是,模块结构仍然和 S1 中的一样(只不过体量更大)。通过与老鼠(mouse)的比较,我们可以发现大一些老鼠(rat)皮层在算法、原理上的改进吗?
猫的情况如何?接下来,非人类的灵长动物,最后,人类大脑皮层样本。随着成像和重构通量的进步,我们会达到这种程度。有了适当的算法准备(洞悉老鼠大脑皮层分类器,并将之作为基线,然后一步步沿着物种轴外推),我们就可能仅用几个更高级物种的样例,发现现在有哪些新的算法发明堪比更简单动物的大脑皮层。
这样一个研究项目,我们已经在实验室中求索数年,它极富抱负,也许会花费数十年才能成功。其研究目标已经引起 IARPA (重磅 | 揭秘IARPA项目:解码大脑算法或将彻底改变机器学习)的主要关注。即使一开始,进展会比较缓慢,但是,破解大脑中生物计算器件的分类窍门,这一追求是开放的,而且通过提供比目前人们所能想到的算法都要好的算法,我们的研究最终也将反哺计算机科学。这一过程中,我们需要机器学习的鼎力相助。
欢迎加入本站公开兴趣群
商业智能与数据分析群
兴趣范围包括各种让数据产生价值的办法,实际应用案例分享与讨论,分析工具,ETL工具,数据仓库,数据挖掘工具,报表系统等全方位知识
QQ群:81035754
正文到此结束
热门推荐










相关文章

近期评论
-
你这基本没有更新呀,最近文章显示还是2019年的文章。不符合要求哈
-
关键词:慕云博客 链接:https://www.lilun.me 描述:分享原创文字的个人博客
-
-
-
可以提供一下源码吗
-
不是商业站,鸡娃学习笔记
-
-
-
-
听他们说很厉害的样子
Loading...
![[HBLOG]公众号](http://www.liuhaihua.cn/img/qrcode_gzh.jpg)

