那些年我们踩过的乱码坑
前言
这是一个由乱码引发的故事。抱歉我暂时找不到更加惨烈的图,请相信我,还有更目不忍视的画面。请看下图那些框框,那都是些什么鬼!这是要害死强迫症吗?如果同时看到几十个框,简直让人崩溃。
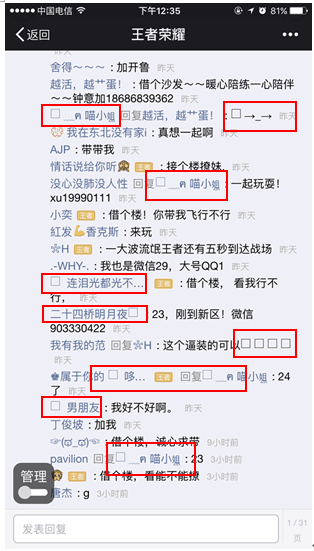
问题来了,这究竟是些什么鬼?
计算机编码
既然是乱码,当然要看编码,那什么是编码呢?我们都知道,计算机本质上不就是 01 组成的一坨东西在运作着么? 01 这叫二进制,也就是最基本最底层的编码。
那么大家平常看到的网页也好,APP也好,上面的这些文字符号是怎么表现出来的?当然是根据标记打印出来的,但计算机只能是二进制的存储,并不能真正存ABCD呀,那就要把字母映射为相应的二进制。
上个世纪60年代,美国制定了一套字符编码,对英语字符与二进制位之间的关系,做了统一规定。这被称为ASCII码,一直沿用至今。
ASCII码一共规定了128个字符的编码,比如大写的字母A是65(二进制01000001)。这128个符号(包括32个不能打印出来的控制符号),只占用了一个字节的后面7位,最前面的1位统一规定为0。但你美国英文字母少啊,我中文怎么办呢?全世界其他国家的字母其他语言怎么办呢,那就多加一些字节来表示咯。
如果有一种编码,将世界上所有的符号都纳入其中。每一个符号都给予一个独一无二的编码,那么乱码问题就会消失了,这就是Unicode。Unicode规定了每个符号都有自己的二进制码。标准虽是标准,但各平台实现标准的进度不一啊,有的各自为政,这就有问题了,就像各大浏览器产商,没给我们前端少带来麻烦啊。简单点说,虽然你苹果实现了这个标准可以显示这个符号,但我Android没有,也不知道这个符号表达成啥,所以暂时给个框吧。
因此导致乱码的真正原因:就是各平台间对Unicode标准实现不一致(包括实现的时间先后不同,以及Unicode所代表含义不同)。
编码分析
那框框的Unicode编码到底是什么呢? charCodeAt() (这个方法有局限性,后面说)方法可返回指定位置的字符的 Unicode 编码。这个返回值是 0 - 65535 之间的整数。
" 追求简單的小生活".charCodeAt(0) // 5761457614是个十进制数,对应16进制为E10E,Unicode也可以表示为U+E10E。通过这个 网站 查询得知结果如下:

一头雾水,PRIVATE USE CODEPOINT这是个什么意思呢?幸好下面有wiki的解释:
In Unicode, the Private Use Areas (PUA) are three ranges of code points (U+E000–U+F8FF in the BMP, and in planes 15 and 16) that, by definition, will not be assigned characters by the Unicode Consortium. The code points in these areas can not be considered as standardized characters in Unicode itself. They are intentionally left undefined so that third parties may define their own characters without conflicting with Unicode Consortium assignments. Under the Unicode Stability Policy, the Private Use Areas will remain allocated for that purpose in all future Unicode versions.
咳咳,由于英文水平问题,但我还是勉强翻译下。大意就是:位于BMP的 U+E000–U+F8FF 编码,和第15以及16平面的区域的编码,Unicode协会表示不会对该区域的编码指定符号,且这些区域编码不是标准符号, 故意留下未定义的区域是让第三方自己去玩 。
那什么又是BMP,第一个平面称为基本多语言平面(Basic Multilingual Plane, BMP),或称第零平面(Plane 0)。其他平面称为辅助平面(Supplementary Planes)。最前面的65536个字符位,都在BMP中。
好了,回到前面看,U+E10E这个Unicode刚好落到了(U+E000–U+F8FF)区间内。所以这个字符是因为第三方自定义的。
网上找到了一份表, http://www.easyapns.com/iphone-emoji-alerts 。 U+E10E 对应符号如下:

那框真的是这个皇冠emoji吗?因为是用户昵称,查一下就知道了
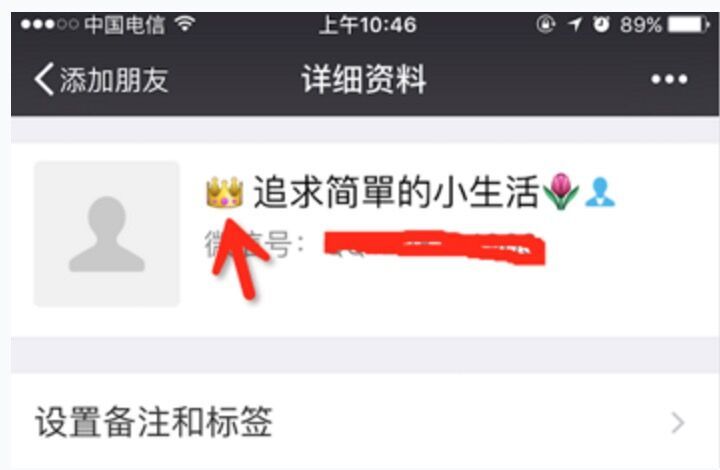
事实证明,确实没错。那么既然是emoji表情,为什么iphone(9.3.1)都不能正常解析?这编码又是怎么被用户输入进去的?
emoji表情
说到emoji,那我们先来扒一扒emoji的历史故事。
emoji表情源于日本,叫做绘(e=图)文字(moji=字符)。
Emoji were initially used by Japanese mobile operators, NTT DoCoMo, au, and SoftBank Mobile (formerly Vodafone).
日本几家公司各自定义了一套标准,用两个字节表示符号,Shift-JIS(日本电脑系统的一种编码)编码是从F89F到F9FC。当然这已经是上世纪的事情了,其中被广泛采用的是SoftBank标准,也称之为SB (SoftBank,这里不是ShaBi的缩写,咳咳)emoji表情。
发展到今天,Unicode协会把emoji表情纳入标准中,但编码范围重新划分了。前面说了,Private Use Areas 是留给第三方用的,不能瞎占用。
在这个 网站 查到 E10E 如下信息:
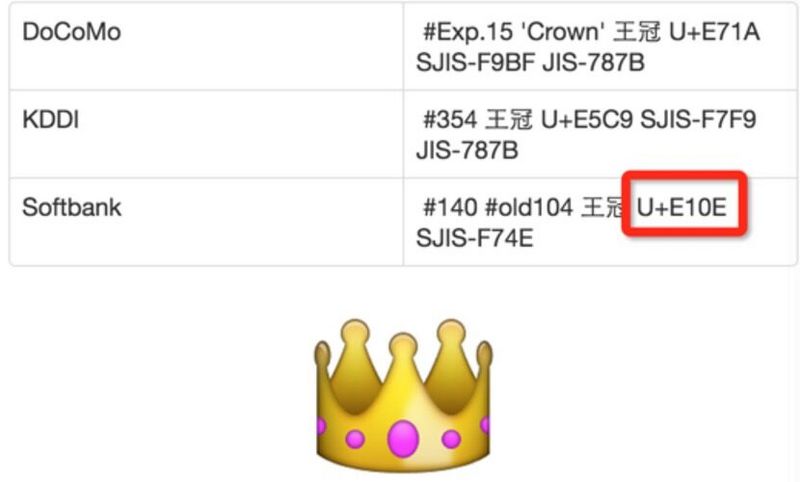
可以初步怀疑是SoftBank的emoji表情。
恰好手中有台旧的华为手机,有一个系统自带的华为输入法,输入法里面有一些跟苹果emoji一样的表情,只不过数量没这么多。下面四个是华为输入法键盘上的表情:

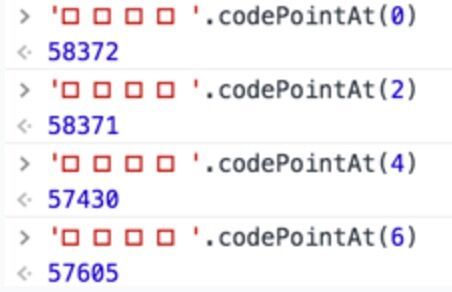
这四个表情在Unicode中的标准编码是:

注意,如果使用charCodeAt方法来获取Unicode编码的时候要注意了,前面我们提到了该方法有缺陷。简单的原因就是JavaScript使用的编码与utf-8不一样导致,这里不展开讲,有兴趣可以看这篇 文章 。ES6提供了新的接口来获取码点, codePointAt 。

输入的结果展示如下:
-
iphone6sp显示框框。

-
huawei显示空白

虽然在两台机器的表现形式不一样,但都是无法正确显示,那我们看下这到底是什么编码。
上面四个编码落入的区域也是在(U+E000–U+F8FF)内,然后根据上面的网站查询,可以确认是来自SoftBank标准的emoji表情了。
所以只要替换这些编码就好了。
解决方案
也就是说 SoftBank emoji表情现在的系统基本不支持 ,因为已经过时了。
但为什么用户还能够输入这些SoftBank emoji呢?原因就在于有些手机输入法(相对古老了)厂商对emoji的实现还是参照SoftBank的标准。
因此把SoftBank emoji编码转换为Unicode标准的就是解决之道。在 github 上找到了SoftBank与标准emoji Unicode的对应关系。
有两种解决方案:
1、转换为html实体编码
/uE10E -> /u1F451 -> 👑 优点:
-
高清,依赖系统编码;
-
不需要加载css和emoji图片,省流量。
缺点:
-
所有平台表情不统一,各系统自定义的图标,风格不同,但表达意思基本一样;

-
部分平台不支持emoji。
ios:  android:
android: 
2、转换为html标签。
code 对应emoji图标的classID,用雪碧图。
<i class="emoji emoji'+code+'" text=""></i>优点:
-
所有平台表情统一(如果统一算优点的话,有争议,毕竟Android用户看习惯了Android表情)。
缺点:
-
需要加载额外的css和emoji图标;如果要高清(暂时无法找到,图片会模糊),则图标会很大。
综上,结合方案一二,在Android版本小于4.4的时候采用方案二,其他采用方案一。
结果
(左边为处理前,右边为处理后)

不同系统的处理结果
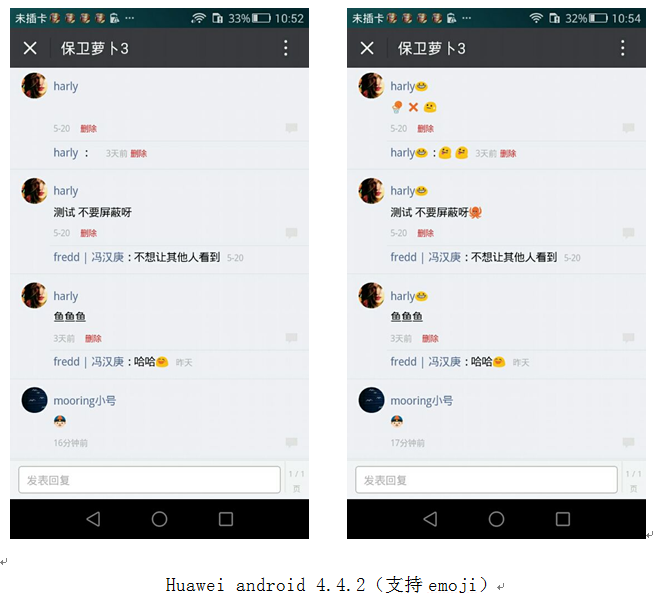
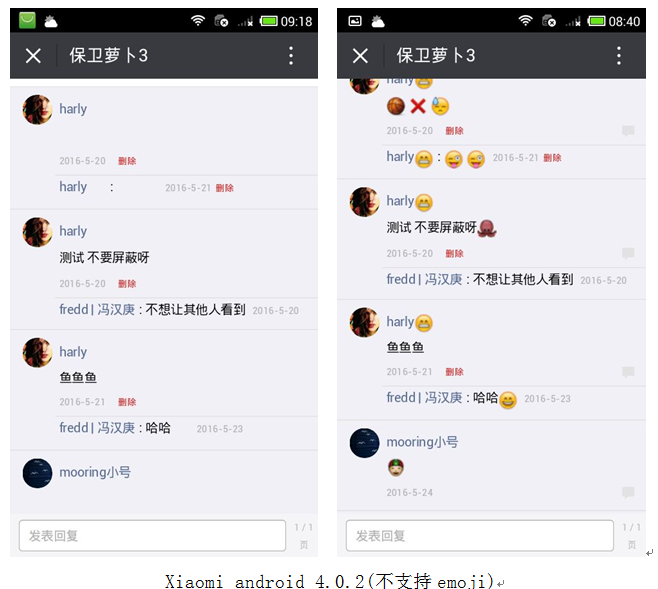
总结
问题来了,如果遇到了其他编码标准(google, DoCoMo,KDDI 等等)的表情该怎么办?如果没有Unicode的与符号的映射关系真是白搭,你丝毫没有办法。就像你不学习英文单词,你还想看懂英文文章?
emoji表情不断在丰富,这也给前端(各种终端)工作者带来麻烦,只能尽可能的补上已知的。
参考资料
https://codepoints.net
http://www.unicode.org/faq/private_use.html#pua1
http://www.ruanyifeng.com/blog/2007/10/ascii_unicode_and_utf-8.html
http://blog.csdn.net/binjly/article/details/47321043
http://computerism.ru/emoji-smiles.htm
http://www.ruanyifeng.com/blog/2014/12/unicode.html
http://blog.csdn.net/ugg/article/details/44225723
https://github.com/iamcal/js-emoji
https://github.com/node-modules/emoji
http://www.fileformat.info/info/emoji/softbank.htm
http://caniemoji.com
http://www.easyapns.com/iphone-emoji-alerts
https://en.wikipedia.org/wiki/Emoji
https://mathiasbynens.be/notes/javascript-unicode正文到此结束
热门推荐










相关文章

近期评论
-
你这基本没有更新呀,最近文章显示还是2019年的文章。不符合要求哈
-
关键词:慕云博客 链接:https://www.lilun.me 描述:分享原创文字的个人博客
-
-
-
可以提供一下源码吗
-
不是商业站,鸡娃学习笔记
-
-
-
-
听他们说很厉害的样子
Loading...
![[HBLOG]公众号](http://www.liuhaihua.cn/img/qrcode_gzh.jpg)

