在 IBM Integration Bus V10 中设置嵌入式全局缓存来实现高可用性
简介
企业应用程序可能要求频繁地访问已保存到数据库或文件中的数据,这对性能产生了负面影响。为了缩短查询时间并减少所使用的处理器资源量,可以将数据加载到缓存中。IBM® Integration Bus V10 提供了一个嵌入式全局缓存,它在多个流之间共享,并且被部署在多个集成服务器和集成节点上。这种快速的分布式缓存结构被存储在集成服务器的 JVM 堆中。当集成服务器发生故障或重新启动时,缓存将被清空,而且存储的所有数据都会丢失。这种数据丢失对于要求高可用的缓存的企业解决方案是不可接受的。
全局缓存的另一个缺点是缓存结构,该结构由简单的键值对组成。应用程序查找一个键,缓存返回一个值。这个基础方法仅适用于包含两个列的数据库表:一个列是惟一的键,另一个列是对应的值。大多数企业应用程序必须访问更为复杂的数据,而且这些数据的检索会要求使用复杂的选择标准。本文将介绍如何为嵌入式全局缓存设计一个容错拓扑。本文还将演示如何使用 CDATA XML 和标记格式将数据加载到缓存中,并为复杂的查询提供示例 ESQL 函数。
设计高可用的缓存解决方案
在设计高可用的缓存时,请考虑以下理念和原则:
- 如果要在高可用性配置中运行,IBM Integration Bus 可以与 IBM WebSphere® MQ 的多实例队列管理器( 多实例 配置)配合使用。
- 缓存被存储在集成服务器的 JVM 堆里。因此,每次重启集成服务器时,缓存都被清空,而且必须重新加载缓存。
- 目录服务器 用于控制和管理缓存的组件。
- 容器服务器 是保存缓存数据的子集的组件。
- 管理一个故障至少需要两个目录和两个容器。
- 一个多实例集成节点不能托管一个目录服务器。
- 如果有多个目录服务器,那么至少必须启动其中的两个,缓存才是可用的。
- 一个集成服务器最多包含一个目录服务器。
- 一个集成服务器最多包含四个容器服务器。
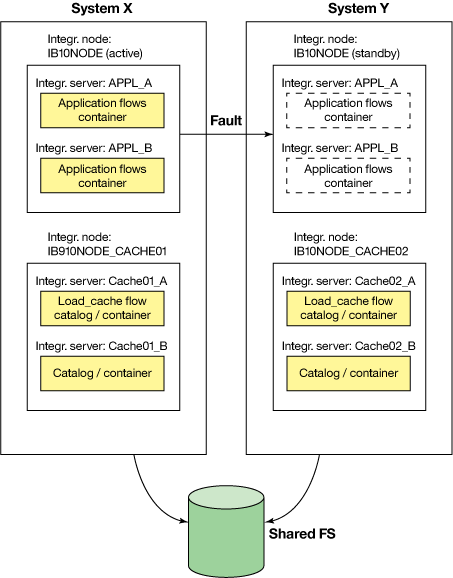
基于这些准则,设计解决方案示例将包含两个 Linux® Red Hat® 6.5 服务器,在这里将它们称为 系统 X 和 系统 Y 。系统 X( 主系统 )通常包含企业应用程序; 系统 Y( 备用系统 )在系统 X 出现故障或切换系统时运行企业应用程序。IBM WebSphere MQ V8.0 安装自带一个多实例队列管理器,在系统 X 和系统 Y 之间共享的文件系统中定义该管理器。缓存是一种非永久性的结构,所以数据被永久存储在 Oracle® 11g 的表中。在每个集成服务器启动后,都会将数据从数据库加载到缓存中。
IBM Integration Bus V10 运行企业应用程序并占用缓存。该应用程序在一个多实例集成节点 ( IB10NODE ) 上运行,该节点包含两个集成服务器( APPL_A 和 APPL_B )。每一个集成服务器都包含一个缓存容器和该企业应用程序。多实例集成节点 IB10NODE 一般在系统 X 上活动;在出故障的时候,节点将切换到系统 Y。缓存由单实例集成节点管理:系统 X 上的 IB10NODE_CACHE01 和系统 Y 上的 IB10NODE_CACHE02 。
集成节点 IB10NODE_CACHE01 包含两个集成服务器( Cache01_A 和 Cache02_B ),各有一个目录服务器,所以当这个集成节点运行的时候,缓存是可用的。集成服务器 Cache01_A 运行应用程序 Load_Cache ,从数据库加载缓存。系统 Y 上的集成节点 IB10NODE_CACHE02 使用两个集成服务器(C ache02_A 和 Cache02_B )来确保缓存的高可靠性,每一个集成服务器有一个目录服务器。如果系统 X 或集成节点 IB10NODE_CACHE01 不可用,那么缓存由节点 IB10NODE_CACHE02 管理。
图 1. IBM Integration Bus 多实例配置,提供高可用性缓存
实现高可用性缓存
在配置缓存之前,应该先安装和配置 Linux 系统和 IBM Integration Bus 节点(本文中未包含)。
配置缓存:
-
创建一个策略文件。部署复杂缓存拓扑的最佳方法是,使用一个描述拓扑的策略文件。表 1 显示了在示例解决方案中使用的基础架构拓扑。
表 1. 高可用性缓存拓扑
集成节点 类型 目录服务器
数量
集成服务器 服务器 IP 端口范围 IB10NODE 多实例 0 APPL_AAPPL_B 192.0.2.1192.0.2.2 3020 - 3039 IB10NODE_CACHE01 单实例 2 CACHE01_ACACHE01_B 192.0.2.1 3000 - 3019 IB10NODE_CACHE02 单实例 2 CACHE02_ACACHE02_B 192.0.2.2 3000 - 3019 容器的数量等于在集成节点中定义的集成服务器的数量(共计 2 个);其他所有信息都被插入到策略文件 Cache_Policy_File.xml,如清单 1 所示。
清单 1. 策略文件 Cache_Policy_File.xml
<?xml version="1.0" encoding="UTF-8"?> <cachePolicy xmlns= "http://www.ibm.com/xmlns/prod/websphere/messagebroker/globalcache/policy-1.0"> <broker name="IB10NODE_CACHE01" listenerHost="192.0.2.1"> <catalogs>2</catalogs> <portRange> <startPort>3000</startPort> <endPort>3019</endPort> </portRange> </broker> <broker name="IB10NODE_CACHE02" listenerHost="192.0.2.2"> <catalogs>2</catalogs> <portRange> <startPort>3000</startPort> <endPort>3019</endPort> </portRange> </broker> <broker name="IB10NODE"> <listenerHost>192.0.2.1</listenerHost> <listenerHost>192.0.2.2</listenerHost> <catalogs>0</catalogs> <portRange> <startPort>3020</startPort> <endPort>3039</endPort> </portRange> </broker> </cachePolicy>
- 连接到主系统(系统 X),并将策略文件应用于两个集成节点:
mqsichangeproperties IB10NODE -b cachemanager -o CacheManager -n policy –v "Cache_Policy_File.xml" mqsichangeproperties IB10NODE_CACHE01 -b cachemanager -o CacheManager -n policy –v "Cache_Policy_File.xml"
- 连接到备用系统(系统 Y),并将策略文件应用于集成节点:
mqsichangeproperties IB10NODE_CACHE02 -b cachemanager -o CacheManager -n policy –v "Cache_Policy_File.xml"
- 重新启动所有集成节点。
- 要验证系统 X 上的配置,请运行以下命令:
mqsireportproperties IB10NODE -e APPL_A -o ComIbmCacheManager -r mqsireportproperties IB10NODE -e APPL_B -o ComIbmCacheManager -r mqsireportproperties IB10NODE_CACHE01 -e CACHE01_A -o ComIbmCacheManager -r mqsireportproperties IB10NODE_CACHE01 -e CACHE01_B -o ComIbmCacheManager -r mqsicacheadmin IB10NODE -c showMapSizes mqsicacheadmin IB10NODE_CACHE01 -c showMapSizes
- 要验证系统 Y 上的配置,请运行以下命令:
mqsireportproperties IB10NODE_CACHE02 -e CACHE02_A -o ComIbmCacheManager -r mqsireportproperties IB10NODE_CACHE02 -e CACHE02_B -o ComIbmCacheManager -r mqsicacheadmin IB10NODE_CACHE02 -c showMapSizes
至少有两个目录服务器启动后,缓存就准备好了。提示: 首先启动缓存管理器集成节点(系统 X 上的 IB10NODE_CACHE01 或系统 Y 上的 IB10NODE_CACHE02),然后再启动多实例集成节点(IB10NODE)。
在启动缓存后,Linux 中的系统日志文件 /var/log/messages 会显示一条消息:
A connection has been established to the integration node global cache. The integration node global cache is now available for use from message processing nodes.
加载和访问缓存
因为全局嵌入式缓存被存储在集成服务器的 JVM 堆里,因此可以通过一个 Java 对象访问它,比如,在 IBM Integration Bus 包 com.ibm.broker.plugin 中定义的 MbGlobalMap 。 MbGlobalMap 对象表示在嵌入式全局缓存中的映射的一个实例。它提供了查询和修改缓存键值对的方法: get 、 update 和 put 。
目前有些实现缓存的解决方案使用了键值对访问。不过,这些解决方案被限制为只用于包含两个列的数据库表,其中一列是惟一的键,另一列是对应的值。请参阅中的相关文章。本文介绍的 ESQL 函数可以实现企业应用程序所需的复杂的访问和加载操作。
以数据库表 USERS_MAP (表 2)为例。数据被加载到缓存映射 users_map 。
表 2. 数据库表 USERS_MAP
| ID | NAME | ADDRESS | PHONE_NUMBER | STATE |
|---|---|---|---|---|
| ID1 | NAME1 | ADDRESS1 | PHONE1 | STATE1 |
| ID2 | NAME2 | ADDRESS2 | PHONE2 | STATE2 |
| ID3 | NAME3 | ADDRESS3 | PHONE3 | STATE3 |
| ID4 | NAME4 | ADDRESS4 | PHONE4 | STATE4 |
| ID5 | NAME5 | ADDRESS5 | PHONE5 | STATE5 |
| ID6 | NAME6 | ADDRESS6 | PHONE6 | STATE6 |
| ID7 | NAME7 | ADDRESS7 | PHONE7 | STATE7 |
为了引用在缓存映射 users_map 中的数据,应用程序搜索 ID 和 NAME 列,并提取其他列(ADDRESS、PHONE_NUMBER 和 STATE)。如果在要实现的查询或更新中,搜索键由两个列(ID 和 NAME)组成,并且要求输出包含多个列(ADDRESS、PHONE_NUMBER 和 STATE),那么用于访问缓存中的键值对的原生方法就有些不够用。
这里存在的问题是:
- 复杂键 :当查询条件与多个列有关的时候(例如,在缓存映射
users_map中 ID = ID1 和 NAME = NAME1 ),应用程序如何搜索缓存中的某一行? - 多个值 :如果只用一个缓存访问,应用程序如何可以获得满足查询搜索的所有列(例如,缓存映射
users_map中的 ADDRESS、PHONE_NUMBER 和 STATE)?
为了解决第一个问题,复杂键问题,您可以创建通过连接符合查询条件的所有列值的单个键。例如,如果应用程序查找的缓存条目涉及列 ID = ID1 并且列 NAME = NAME1,那么复杂键是: ID1$;$NAME1 。单个列值用标签分隔:存储在用户定义的属性 (UDP) CACHE_TAG_SEPARATOR 中的 $;$ 。UDP 的优点是,可以在部署和运行的时候更改它们的值,不需要更改应用程序。
您还可以解决第二个问题 “多个值”,一种解决方法是将所有的列值都插入到缓存值字段,将它们作为一条 CDATA XML 消息(称为 CDATA XML 格式),另一种解决方法是,使用在 CACHE_TAG_SEPARATOR 变量中指定的标记分隔符将它们连接起来(称为标记格式)。
将数据库值加载到缓存中
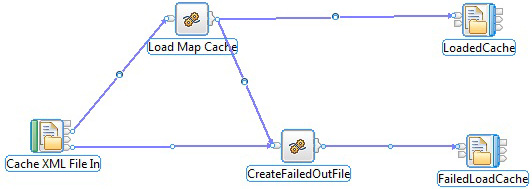
访问缓存的第一步是,将数据库表中的数据加载到缓存映射中。使用 Java 对象 MbGlobalMap 的 put 和 update 方法可以将数据库表加载到缓存映射中。在示例消息流 LoadGlobalCacheMap 中,这些方法被增强,可以将更多数据库列值加载到缓存键和缓存值中。流是在应用程序 CACHE_LOADER 中定义的。
图 2 中的消息流接收一个 XML 文件作为输入,其中指定了要加载到缓存中的表。如果加载处理成功,消息流会创建一个具有加载缓存映射内容的输出文件,或者一个异常描述。
图 2. 在缓存中加载数据库的示例消息流
输入 XML 文件包含以下数据:
-
<MapName>。数据被写入的缓存映射的名称。 -
<TableName>。在缓存映射中加载的数据库表的名称。表名的前面是数据库模式名称。例如,要加载在模式IBMDEV中定义的表USERS_MAP,XML 字段<TableName>中包含以下字符串:IBMDEV.USERS_MAP。 -
<PrimaryKey>。一个文件夹,包含列名的清单,这些列的值被插入到缓存键条目中。这些值已使用标记分隔符 (CACHE_TAG_SEPARATOR)串联起来。
数据库列值可以作为一条 CDATA XML 消息插入到缓存值中,或者用标记分隔符 ( CACHE_TAG_SEPARATOR ) 串联起来。
为了指定使用这两种格式中的哪一种来加载缓存值,在输入 XML 文件中使用下列文件夹之一:
-
<XMLData>.A文件夹,包含列名的清单,这些列的值被作为 CDATA XML 消息插入到缓存值条目。 -
<TagData>.A文件夹,包含列名的清单,这些列的值用标记分隔符串联起来,被插入到缓存值条目。
例如,使用清单 2 中所示的 XML 输入文件,可以将表 USERS_MAP (模式 IBMDEV )加载到缓存映射 users_map 中(采用 CDATA XML 格式)。
清单 2. 用于加载表 USERS_MAP(CDATA XML 格式)的 XML 输入文件
<LoadMaps> <LoadMap> <MapName>users_map</MapName> <TableName>IBMDEV.USERS_MAP</TableName> <PrimaryKey> <column>ID</column> <column>NAME</column> </PrimaryKey> <XMLData> <column>ID</column> <column>ADDRESS</column> <column>PHONE_NUMBER</column> <column>STATE</column> </XMLData> </LoadMap> </LoadMaps>
缓存键由数据库列 ID 和 NAME 组成,而且缓存值包含采用了 CDATA XML 格式的数据库列 ID 、 ADDRESS 、 PHONE_NUMBER 和 STATE 。
使用清单 3 中所示的 XML 输入文件,表 USERS_MAP (模式 IBMDEV )也可以加载到缓存映射 users_map 中(采用标记格式)。
清单 3. 用于加载表 USERS_MAP(标记格式)的 XML 输入文件
<LoadMaps> <LoadMap> <MapName>USERS_MAP</MapName> <TableName>IBMDEV.USERS_MAP</TableName> <PrimaryKey> <column>ID</column> <column>NAME</column> </PrimaryKey> <TagData> <column>ID</column> <column>ADDRESS</column> <column>PHONE_NUMBER</column> <column>STATE</column> </TagData>> </LoadMap> </LoadMaps>
缓存值包含标记格式的数据库列值。
您可以使用 XML CDATA 格式化加载缓存中的一些表,使用标记格式化来加载其他表。例如,清单 4 显示了一个示例输入 XML 文件,采用 CDATA XML 格式加载表 ALIAS_MAP ,并采用标记格式加载表 USERS_MAP 。
清单 4. 用于加载表的 XML 输入文件(包括 XML CDATA 和标记格式)
<LoadMaps> <LoadMap> <MapName>ALIAS_MAP</MapName> <TableName>IBMDEV.ALIAS_MAP</TableName> <PrimaryKey> <column>KEYNAME</column> </PrimaryKey> <XMLData> <column>VALUE</column> </XMLData> </LoadMap> <LoadMap> <MapName>USERS_MAP</MapName> <TableName>IBMDEV.USERS_MAP</TableName> <PrimaryKey> <column>ID</column> <column>NAME</column> </PrimaryKey> <TagData> <column>ID</column> <column>ADDRESS</column> <column>PHONE_NUMBER</column> <column>STATE</column> </TagData> </LoadMap> </LoadMaps>
消息流 LoadGlobalCacheMap 可以通过验证其 ESQL 指令中是否包含文件夹 <XMLData> 或 <TagData> 来识别加载格式(清单 5)。
清单 5. 识别加载格式的类型的 ESQL 指令
IF EXISTS(refInLoadMap.*:XMLData.*[]) THEN -- The value is a XML CDATA structure SET cSQL_SELECT_TABLE = CreateSQLQuery(refInLoadMap.*:XMLData,cTableName, rPrimaryKey ); ELSEIF EXISTS(refInLoadMap.*:ValueData.*[]) THEN -- The value is a single value SET cSQL_SELECT_TABLE = CreateSQLQuery(refInLoadMap.*:ValueData,cTableName, rPrimaryKey ); ELSEIF EXISTS(refInLoadMap.*:TagData.*[]) THEN SET cSQL_SELECT_TABLE = CreateSQLQuery(refInLoadMap.*:TagData,cTableName, rPrimaryKey ); END IF; SET rSQLQuery.SQL[] = PASSTHRU(cSQL_SELECT_TABLE);
ESQL 过程 CreateSQLQuery (清单 6)创建一个 SQL 查询,选择采用指定的格式(XML CDATA 或标记)加载到缓存中的表行和列。
清单 6. 用于将数据加载到缓存中的示例 ESQL 过程
清单 6. 用于将数据加载到缓存中的示例 ESQL 过程
CREATE PROCEDURE CreateSQLQuery(IN rCols REFERENCE, IN cInNameTable CHARACTER, IN rInPrimaryKey REFERENCE) RETURNS CHARACTER BEGIN DECLARE rcolumn REFERENCE TO rCols.*:column[1]; DECLARE cSQLQuery,cPrimKeys CHARACTER; DECLARE iPos INTEGER; DECLARE cSchema, cTable CHARACTER; -- Input Table name contains also the schema:SCHEMA.TABLENAME SET iPos = POSITION ('.'IN cInNameTable); SET cSchema = SUBSTRING(cInNameTable FROM 1 FOR (iPos - 1)); SET cTable = SUBSTRING(cInNameTable FROM (iPos+1)); IF cSchema IS NULL or cTable IS NULL THEN THROW USER EXCEPTION VALUES ('ERROR Reding Database table.Table Name Unknown:' || COALESCE(cSchema,'') || '.'|| COALESCE (cTable,'')); END IF; SET cSQLQuery = 'SELECT '; -- -- Create the SQL string with the primary keys.For example: -- T.COL_NAME1 PRIMARY_KEY_1, T.COL_NAME1 PRIMARY_KEY_2 -- SET cPrimKeys = CreatePrimKeySQL(rInPrimaryKey); SET cSQLQuery = cSQLQuery || cPrimKeys; WHILE LASTMOVE(rcolumn) DO SET cSQLQuery = cSQLQuery || ', T.' || rcolumn; MOVE rcolumn NEXTSIBLING REPEAT NAME; END WHILE; -- LASTMOVE(rcolumn) SET cSQLQuery = cSQLQuery || ' FROM ' || cSchema || '.'|| cTable || ' T'; RETURN cSQLQuery; END; 访问采用了 CDATA XML 格式的缓存
如果将数据库列值插入一个采用了 CDATA XML 格式的缓存中,缓存值会包含一条 CDATA XML 消息。例如,如果使用清单 7 中的 XML 文件,将表 USERS_MAP (如表 2 所示)加载到缓存中,那么得到的缓存映射 USERS_MAP 如清单 8 所示。
清单 7. 用于加载 USERS_MAP 表(CDATA XML 格式)的 XML 输入文件
<LoadMaps> <LoadMap> <MapName>users_map</MapName> <TableName>IBMDEV.USERS_MAP</TableName> <PrimaryKey> <column>ID</column> <column>NAME</column> </PrimaryKey> <XMLData> <column>ID</column> <column>ADDRESS</column> <column>PHONE_NUMBER</column> <column>STATE</column> </XMLData> </LoadMap> </LoadMaps>
清单 8. USERS_MAP 表的缓存映射
清单 8. USERS_MAP 表的缓存映射
<Map name="USERS_MAP"> <Entry key="ID1$;$NAME1"> <IBMDEV.USERS_MAP><PRIMARY_KEY_1>ID1</PRIMARY_KEY_1><PRIMARY_KEY_2>NAME1</PRIMARY_KEY_2><ID>ID1</ID> <ADDRESS>ADDRESS1</ADDRESS><PHONE_NUMBER>PHONE1</PHONE_NUMBER><STATE>STATE1</STATE></IBMDEV.USERS_MAP> </Entry> ...... <Entry key="ID7$;$NAME7"> <![CDATA <IBMDEV.USERS_MAP><PRIMARY_KEY_1>ID7</PRIMARY_KEY_1><PRIMARY_KEY_2>NAME7</PRIMARY_KEY_2><ID>ID7</ID> <ADDRESS>ADDRESS7</ADDRESS><PHONE_NUMBER>PHONE1</PHONE_NUMBER><STATE>STATE7</STATE></IBMDEV.USERS_MAP>]]> </Entry> </Map>
应用程序可以通过调用 ESQL 过程 ExtractXMLValues 来访问 CDATA XML 格式的缓存,如清单 9 所示。
清单 9. 用于访问 CDATA XML 格式的缓存的 ESQL 过程
清单 9. 用于访问 CDATA XML 格式的缓存的 ESQL 过程
CREATE PROCEDURE ExtractXMLValues(IN rInCache REFERENCE, IN rOutCacheFields REFERENCE ) RETURNS BOOLEAN BEGIN DECLARE cMapName, cKey, cMainFieldName CHARACTER; DECLARE cMainFieldValue,cFieldName CHARACTER; DECLARE bFound BOOLEAN FALSE; DECLARE rOutTmp, rTmp1 REFERENCE TO rOutCacheFields; DECLARE rOutCache REFERENCE TO OutputRoot; SET cMapName = rInCache.MapName; SET cKey = rInCache.Key; SET cMainFieldName = rInCache.MainField; IF (cMapName || cKey || cMainFieldName ) IS NULL THEN RETURN FALSE; END IF; CREATE LASTCHILD OF rOutTmp AS rOutCacheFields NAME 'CACHE'; SET bFound = CacheLib.getCacheCDATAValue(cMapName,cKey, cMainFieldName ,rOutTmp,cMainFieldValue); IF bFound IS TRUE THEN CREATE LASTCHILD OF OutputRoot AS rOutCache DOMAIN('XMLNSC'); CREATE LASTCHILD OF rOutCache AS rOutCache NAME 'CacheOutput'; SET rOutCache.MapName = cMapName; SET rOutCache.Key = cKey; SET rOutCache.MainField = cMainFieldValue; CREATE LASTCHILD OF rOutCache AS rOutCache NAME 'OtherFields'; MOVE rTmp1 TO rOutTmp.CDATA.XMLNSC.*[1]; IF NOT LASTMOVE(rTmp1) THEN RETURN FALSE; END IF; MOVE rTmp1 FIRSTCHILD; FIELD_LOOP:WHILE LASTMOVE(rTmp1) DO SET cFieldName = FIELDNAME(rTmp1); IF CONTAINS(cFieldName, 'PRIMARY_KEY') THEN MOVE rTmp1 NEXTSIBLING; ITERATE FIELD_LOOP; END IF; SET rOutCache.{cFieldName} = FIELDVALUE(rTmp1); MOVE rTmp1 NEXTSIBLING; END WHILE FIELD_LOOP; END IF; END; 例如,一个应用程序可以调用 ESQL 过程 ExtractXMLValues 来搜索 key= ID1$;$NAME1 ,并检索 ADDRESS 列的值和其他列值。
作为输入,该过程需要一个针对以下各项的引用 ( rInCache ):
- MapName =
users_map - Key =
ID1$;$NAME1 - MainField =
ADDRESS
该过程返回 ( rOutCacheFields ):
- MapName:
users_map - Key:
ID1$;$NAME1 - MainField:
ADDRESS1
-
OtherFields: - ADDRESS:
ADDRESS1 - PHONE_NUMBER:
PHONE_NUMBER1 - STATE:
STATE1
通过简单地指定列名,应用程序可以直接引用许多输出值,不需要重复访问缓存。例如, rOutCacheFields.OtherFields.STATE 将返回 STATE1。
访问使用标记格式的缓存
对于具有多个列的表,CDATA XML 缓存格式会占用很多的空间。对于每一列,缓存值字段都在 XML 标记中存储其值和名称。为了节省空间,一种解决方案是使用分隔符 CACHE_TAG_SEPARATOR 来串联列值(无 XML 标记)。例如,假设使用清单 10 中的 XML 输入文件将表 USERS_MAP (如表 2 所示)加载到缓存中。
清单 10. 用于加载 USERS_MAP 表的 XML 输入文件(标记格式)
<LoadMaps> <LoadMap> <MapName>USERS_MAP</MapName> <TableName>IBMDEV.USERS_MAP</TableName> <PrimaryKey> <column>ID</column> <column>NAME</column> </PrimaryKey> <TagData> <column>ID</column> <column>ADDRESS</column> <column>PHONE_NUMBER</column> <column>STATE</column> </TagData>> </LoadMap> </LoadMaps>
所生成的缓存映射 USERS_MAP 如清单 11 所示。
清单 11. USERS_MAP 表的缓存映射
<Map name="USERS_MAP"> <Entry key="ID1$;$NAME1">ID1$;$NAME1$;$ID1$;$ADDRESS1$;$PHONE1$;$STATE1</Entry> ........ <Entry key="ID7$;$NAME7">ID7$;$NAME7$;$ID7$;$ADDRESS7$;$PHONE1$;$STATE7</Entry> </Map>
标记解决方案的缺点是,应用程序只能按位置引用列值。因此,如果列在表中的位置发生改变,必须更改 ESQL 代码才能使用新的索引。
应用程序可以调用 ESQL 过程 ExtractTagValues 来搜索 key = ID1$;$NAME1 ,并检索 ADDRESS 列的值和其他列值(清单 12)。
清单 12. 用于访问标记格式的缓存的 ESQL 过程
清单 12. 用于访问标记格式的缓存的 ESQL 过程
CREATE PROCEDURE ExtractTagValues(IN rInCache REFERENCE, IN rOutCacheFields REFERENCE) RETURNS BOOLEAN BEGIN DECLARE cMapName, cKey CHARACTER; DECLARE iMainFieldPos INTEGER; DECLARE cMainFieldValue,cFieldName CHARACTER; DECLARE bFound BOOLEAN FALSE; DECLARE rOutTmp, rTmp1,rOutValue REFERENCE TO rOutCacheFields; DECLARE rOutCache REFERENCE TO OutputRoot; SET cMapName = rInCache.MapName; SET cKey = rInCache.Key; SET iMainFieldPos = rInCache.MainFieldPos; IF (cMapName || cKey || CAST(iMainFieldPos AS CHARACTER) ) IS NULL THEN RETURN FALSE; END IF; SET bFound= CacheLib.getCacheTagValue(cMapName,cKey,iMainFieldPos, cMainFieldValue, rOutTmp); MOVE rOutTmp TO rOutTmp.*:DFDL.*:TaggedCacheValue; IF bFound IS TRUE THEN CREATE LASTCHILD OF OutputRoot AS rOutCache DOMAIN('XMLNSC'); CREATE LASTCHILD OF rOutCache AS rOutCache NAME 'CacheOutput'; SET rOutCache.MapName = cMapName; SET rOutCache.Key = cKey; SET rOutCache.MainField = cMainFieldValue; CREATE LASTCHILD OF rOutCache AS rOutCache NAME 'OtherFields'; MOVE rTmp1 TO rOutTmp; IF NOT LASTMOVE(rTmp1) THEN RETURN FALSE; END IF; MOVE rTmp1 FIRSTCHILD; FIELD_LOOP:WHILE LASTMOVE(rTmp1) DO CREATE LASTCHILD OF rOutCache AS rOutValue NAME 'Value'; SET rOutValue = FIELDVALUE(rTmp1); MOVE rTmp1 NEXTSIBLING; END WHILE FIELD_LOOP; END IF; END; 作为输入,该过程需要一个针对以下各项的引用 ( rInCache ):
- MapName =
users_map - Key =
ID1$;$NAME1 - MainField =
ADDRESS
该过程返回 ( rOutCacheFields ):
- MapName:
users_map - Key:
ID1$;$NAME1 - MainField:
ADDRESS1
-
OtherFields: - Value:
ADDRESS1 - Value:
PHONE_NUMBER1 - Value:
STATE1
通过简单地指定列的位置,应用程序可以直接引用许多输出值,不需要重复访问缓存。例如, rOutCacheFields.OtherFields.Value[2] 将返回 PHONE_NUMBER1。
删除缓存中的映射
要清空缓存映射,可使用命令 mqsicacheadmin 。下面的命令将会清空缓存映射 USERS_MAP:
mqsicacheadmin IB10NODE -c clearGrid -m USERS_MAP
示例应用程序
示例代码包含两个消息流:
- 消息流
LoadGlobalCacheMap(在应用程序CACHE_LOADER中)用于加载来自 Oracle® 数据库的缓存。 - 消息流
ReadCache(在应用程序CACHE_CLIENT_EXAMPLE中)用于访问缓存数据。
参见部分的代码和说明。
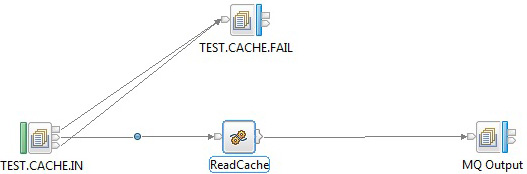
图 3 中的消息流接收作为输入的一条 WebSphere MQ 消息,该消息将指定缓存映射名称( <MapName> 字段)、用于查询的复杂键( <Key> 字段),以及将从缓存值中检索的主要输出列名( <MainField> 字段)。如果找到该缓存映射,消息流会创建一个包含所需值的输出文件。
图 3. 示例消息流 ReadCache
清单 13 显示了一个示例输入文件,用于从以 CDATA XML 格式加载的缓存中提取通过文件夹 <XMLCache> 指定的数据。
清单 13. 用于提取以 CDATA XML 格式加载的数据的 XML 输入文件
<?xml version="1.0" encoding="UTF-8"?> <Cache> <XMLCache> <MapName>USERS_MAP</MapName> <Key>ID1$;$NAME1</Key> <MainField>PHONE_NUMBER</MainField> </XMLCache> </Cache>
消息流 ReadCache 在映射 USERS_MAP 中寻找一个等于 ID1$;$NAME1 的键,并返回存储在缓存值内的所有列值。清单 14 显示了输出消息。
清单 14. ReadCache 的输出消息
<CacheOutput> <MapName>USERS_MAP</MapName> <Key>ID1$;$NAME1</Key> <MainField>PHONE1</MainField> <OtherFields> <ID>ID1</ID> <ADDRESS>ADDRESS1</ADDRESS> <PHONE_NUMBER>PHONE1</PHONE_NUMBER> <STATE>STATE1</STATE> </OtherFields> </CacheOutput>
如果以标记格式加载缓存映射(文件夹 <TagCache> ),消息流 ReadCache 的输入消息如清单 15 所示。
清单 15. ReadCache 的输入消息(标记格式)
<?xml version="1.0" encoding="UTF-8"?> <Cache> <TagCache> <MapName>USERS_MAP</MapName> <Key>ID1$;$NAME1</Key> <MainFieldPos>2</MainFieldPos> </TagCache> </Cache>
清单 16 显示了输出文件。
清单 16. ReadCache 的输出文件
<CacheOutput> <MapName>USERS_MAP</MapName> <Key>ID1$;$NAME1</Key> <MainField>NAME1</MainField> <OtherFields> <Value>ID1</Value> <Value>NAME1</Value> <Value>ID1</Value> <Value>ADDRESS1</Value> <Value>PHONE1</Value> <Value>STATE1</Value> </OtherFields> </CacheOutput>
结束语
当应用程序访问数据时,IBM Integration Bus 中的嵌入式全局缓存可以显著提高应用程序的性能。本文介绍了如何在要求高可用性和复杂访问查询的企业环境中使用这种快速结构。本文描述了如何实现容错基础架构。本文还演示了用于加载和访问 CDATA XML 或标记格式的缓存数据的示例 ESQL 函数。
参考资料
- IBM Integration Bus 资源
- IBM Knowledge Center for Integration Bus V10 。所有 IBM Integration Bus 文档的单一门户,包括有关安装、配置、升级和使用 IBM Integration Bus 的概念性信息、任务和参考信息。
- IBM Integration Bus 产品家族页面 。产品特性、用例和资源。
- IBM 知识中心主题: IBM Integration Bus V10 中的新特性 。V10 的特性摘要。
- 公告信:IBM Integration Bus V10 。官方公布的信息,包括先决条件、条款和条件、订购信息,等等。
- IBM Integration Bus 论坛 。关于 mqseries.net 的论坛,论坛中提供了一些用户问题、答案和提示。
- 跟踪 IBM Integration Bus 用户需求 。创建、查看和跟踪 IBM Integration Bus 用户需求。
- 在 WebSphere Message Broker 中使用全局缓存 。这篇 developerWorks 文章介绍了如何使用键值对来访问缓存。
- 在 WebSphere Message Broker 和 IBM Integration Bus 中使用 ESQL 共享变量实现高效、可扩展的缓存 。这篇 developerWorks 文章介绍了使用全局缓存的性能优势。
- WebSphere 资源
- developerWorks WebSphere 。面向使用 WebSphere 产品的开发人员的技术信息和资源。
- developerWorks 上与 WebSphere 相关的文章 。由 IBM 内部和外部的顶尖从业者及顾问撰写的超过 3000 篇有关 WebSphere 及相关技术的编辑和分类文章。搜索您所需要的内容。
- 来自 IBM Press 的关于 WebSphere 的书籍 。通过 Pearson Education 实现便捷的在线订购。
- developerWorks 资源
- IBM 软件产品的试用版本下载 。精选 IBM 产品的免费试用版本下载。
- developerWorks 活动。查找有助于提高技术技能的活动,包括黑客马拉松、研讨会、训练营和聚会。
- 加入 developerWorks 中文社区 ,developerWorks 社区是一个面向全球 IT 专业人员,可以提供博客、书签、wiki、群组、联系、共享和协作等社区功能的专业社交网络社区。
下载
| 描述 | 名字 | 大小 |
|---|---|---|
| Sample Project InterChange | IB10_GlobalCache.zip | 25KB |
| Installation instructions | SampleInstall_README.txt | 6KB |
正文到此结束
- 本文标签: web struct sql 代码 Select 开发 src 社交网络 zip ip cat 管理 DOM 解决方法 lib message update node 产品 数据 HTML 软件 client 免费 java 端口 数据库 黑客 App list example 下载 目录 IBM Oracle UI 空间 value schema 文章 linux tab Ipo 配置 UDP key Connection 博客 cache 服务器 tar 安装 时间 XML 企业 删除 plugin root map 需求 实例 Developer http 处理器
- 版权声明: 本文为互联网转载文章,出处已在文章中说明(部分除外)。如果侵权,请联系本站长删除,谢谢。
- 本文海报: 生成海报一 生成海报二
热门推荐










相关文章






Loading...
![[HBLOG]公众号](http://www.liuhaihua.cn/img/qrcode_gzh.jpg)

