大数据架构师必读的NoSQL建模技术
从数据建模的角度对NoSQL家族系统做了比较简单的比较,并简要介绍几种常见建模技术。
1.前言
为了适应大数据应用场景的要求,Hadoop以及NoSQL等与传统企业平台完全不同的新兴架构迅速地崛起。而下层技术基础的革命必将影响上层建筑:数据模型和算法。简单地将传统基于第四范式结构化关系型数据库的模型拷贝到新的引擎上,无异于削足适履,不仅增加了大数据应用开发的难度和复杂度,又无法发释放新框架的潜能。
该如何构建基于NoSQL的数据模型?现在能供参考的公开知识积累要么是空虚简单的一句“去规范化“或粗暴的宽表化(将query和应用需要访问的所有字段“排排坐“,放在一个有很多列的结构化表中),要么是针对具体工具或具体场景的实现细节,(如《HBase权威指南》中对于如何设计HBase主键的探讨)。没有一个像编程的设计模式一样的,在模型架构层面可以遵循的方法论。
在比较不同的NoSQL数据库时,通常使用功能以外其他各种指标,如可扩展性、性能和一致性。由于这些指标通常是使用NoSQL的初衷,所以无论从理论的角度还是实践的角度被深入地研究了,而像CAP定理这样的分布式系统基础结论也同样适用于NoSQL系统。另一方面,在NoSQL的数据模型领域,却还没有很好地研究过,也缺乏关系数据库中那种系统性的理论。
我在这篇文章中从数据建模的角度对NoSQL家族系统做了比较简单的比较,并简要介绍几种常见建模技术。
2.NoSQL数据模型视图
要探索数据建模技术,必须先从系统性的NoSQL数据模型视图着手,这多多少少能帮助我们揭示其发展趋势以及相互之间的关系。下图描绘了主要NoSQL家族系统的虚拟“进化”过程,即键值存储,BigTable类型的数据库,文档数据库,全文搜索引擎,数据库和图形数据库:
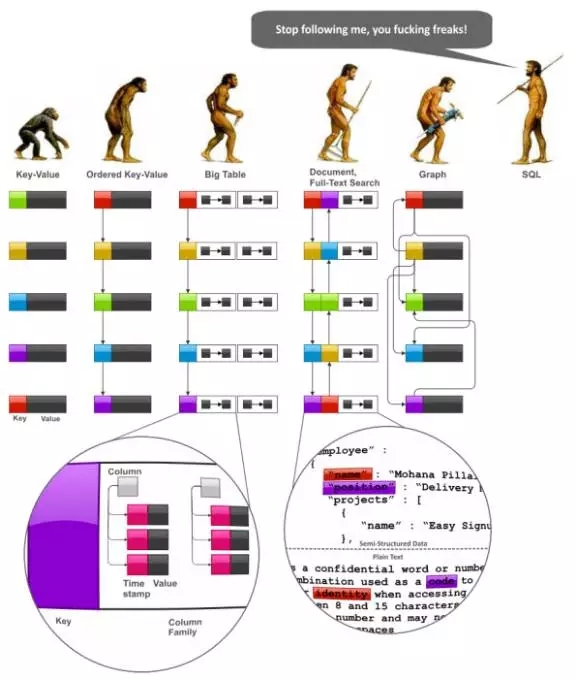
首先,我们应该注意到,一般意义上讲,SQL和关系型模型都是在很久以前就被设计出来,目的是为最终用户交互之用。这种面向用户的性质有极深的影响:
最终用户往往对汇总报表信息感兴趣而不是单独的数据项,因而SQL这方面做了大量的工作。
不能指望作为自然人的用户能显式地控制并发性、完整性、一致性或者数据类型有效性。这就是为什么SQL竭力关注于事务保证、schema和参照完整性。
另一方面,软件应用程序往往对在数据库内部做聚合没有太大的兴趣,而且至少在许多情况下,程序能够自己控制完整性和有效性。除此之外,剔除这些功能对于性能和可扩展性存储的影响极其重要。
新数据模型的演变开始了:
键-值存储是一个非常简单,但非常强大的模型。下面所描述的许多技术都完全适用于这个模型。
键值模型最致命的缺点之一就是不适合按范围处理主键的场景。有序的键-值模型突破了这一限制,并显著提高了聚合能力。
有序的键-值模型非常强大,但它不提供任何针对值(value)的建模框架。在一般情况下,值的建模可以由应用程序完成,但BigTable风格的数据库想得更加周到,它可以将值按照映射的映射的映射(map-of-maps-of-maps)进行建模,说得明确点,分别是列簇(column family)、列(column)和时间戳化的版本。
文档数据库对BigTable模式提出两个明显的改善。第一,值可以被声明为任意复杂的schema,而不仅仅是一个映射的映射(map-of-maps)。第二,至少有一些产品实现了被数据库管理的索引。就这个意义上来讲,全文搜索引擎也可以同样被认为提供了灵活的schema和自动化的索引。他们之间主要区别在于,文档数据库是根据字段名对索引进行编组,而搜索引擎是使用字段值对索引编组。值得注意的是像Oracle Coherence这样的键-值存储系统增加了索引和内嵌入口处理器的功能,正逐步向文件数据库演进。
最后,图形数据模型可以被视为有序的键-值模型朝另外一个方向的进化。图形数据库允许对业务实体进行非常透明的建模(这个东西取决于那个东西),而分层建模技术在这方面用的是另外的数据模型,但也可与之媲美。图形数据库和文件数据库息息相关,因为许多实现允许建模的值是映射或者文档。
3.NoSQL数据建模的一般注意事项
与关系型建模不同,NoSQL数据建模往往是从特定查询的应用开始:
关系型建模是典型地被手上可用数据的结构所驱动。设计主要围绕着的是“我有什么样的答案?”
NoSQL数据建模通常由特定应用的访问模式所驱动,比如需要支持的查询类型。设计主要围绕着的是“我有什么问题?”
NoSQL数据建模往往比关系数据库建模需要更加深入地了解数据结构和算法。在这篇文章中,我介绍了几个著名的数据结构,他们虽然非NoSQL所特有,但对于实际的NoSQL建模非常有用。
数据复制和去规范化是一等公民。
关系数据库在对分层或图形数据进行建模和处理时不是很方便。图形数据库显然是这个领域的完美解决方案,但实际上大多数的NoSQL也都非常善于解决这样的问题。这就是为什么这篇文章为分层数据建模单独写了一个章节。
虽然数据建模技术基本上和具体实现无关,但我还是列出了在写这篇文章时我能想到的产品:
键值存储:Oracle Coherence,Redis,Kyoto Cabinet
BigTable风格的数据库: Apache HBase,Apache Cassandra
文档数据库: MongoDB,CouchDB
全文搜索引擎: Apache Lucene,Apache Solr
图形数据库:Neo4j,FlockDB
4.概念技术
本节专门介绍NoSQL数据建模的基本原则。
1、 去规范化(Denormalization)
可以将去规范化定义为把相同的数据复制到多个文档或数据表中,这样可以简化/优化查询处理,或者让用户数据能匹配一个特定的数据模型。在本文的大多数技术用到了这样或那样的去规范化。
一般来说,去规范化用于以下的折衷:
查询的数据量或每次查询IO**与总数据量的折衷。去规范化可以将一个查询所需的所有数据组合起来存放到同一个地方。这通常意味着对相同数据的不同的查询会访问不同的数据组合。因此,数据需要被复制多份,也就意味着增加了总数据量。
处理复杂性与总数据量的折衷。建模时的规范化和相应查询的连接(join)明显增加了查询处理器的复杂度,在分布式系统中尤为明显。去规范化允许将数据按照查询友好的方式存储,从而简化查询的处理。
适用性:键值存储,文档数据库, BigTable风格的数据库
2、 聚合(Aggregates)
所有主流NoSQL都提供了这样或那样的松散schema(soft schema)支持:
键值存储和图形数据库通常不对值进行约束,所以值可能是任意格式。另外,也可以通过使用组合键将一个业务实体表示为多条记录。例如,可以将一个用户帐户建模为UserID_name,UserID_email,UserID_messages等组合键表示的一个实体集合。如果用户没有电子邮件或消息,然后相应的实体不会被记录。
BigTable模式也支持松散schema,因为一个列簇是可变的列集合,一个单元格又能存储不定数目的数据版本。
文档数据库天生就没schema,虽然某些文档数据库允许在数据输入时使用用户定义的schema进行验证。
松散schema允许使用复杂的内部结构(嵌套实体)构造实体的类,也允许改变特定实体的结构。这个更能带来了两个重要的便利:
通过嵌套的实体,最小化了一对多的关系,也因此减少了连接(join)。
异构业务实体的模型可以使用一个文档集合或者一个数据表。松散schema掩藏了这种建模和业务实体之间“技术”上的差异。
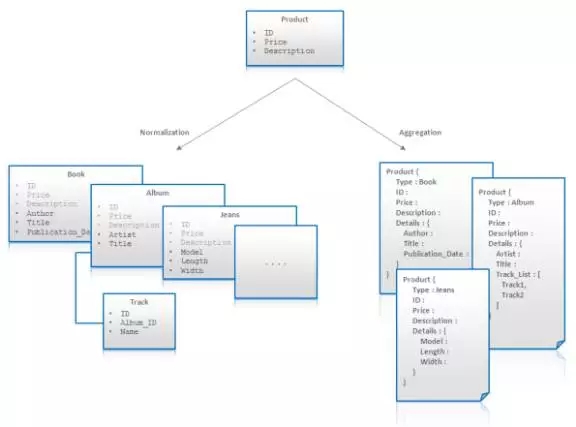
我们用下面的图来说明这些便利。该图描绘了对电子商务领域中一个产品实体进行的建模。首先我们可以认为所有的产品都有一个ID、价格(Price)和描述(Description)。进一步来看,我们发现不同类型的产品有不同的属性,如图书包含作者信息,而牛仔裤有长度属性。这些属性中间的某些属性天生就有一对多或这多对多的特性,比如音乐唱片中的曲目。
更进一步来看,可能有些实体不可能使用固定的类型进行建模。例如,不同品牌的牛仔裤的属性是不固定的,而每个制造商出产的牛仔裤的属性也是不一致的。在规范化的关系型数据模型中虽然这些问题都可以解决,但方法很猥琐。松散schema软架构允许只使用一个聚合(Aggregation)(产品)就能对所有类型的产品及其属性进行建模:
内嵌的去规范化会在性能和一致性上对更新操作造成很大的影响,所以要特别注意更新过程。
适用性:键值存储,文档数据库, BigTable的风格数据库
3、 应用端连接(Application Side Joins)
很少有NoSQL解决方案支持连接。NoSQL“问题导向”性质的后果就是,通常在设计时处理join,而关系型模型是在执行查询时处理join。查询时处理join几乎肯定会带来性能上的损失,但在许多情况下,可使用去规范化和聚合,即嵌入嵌套实体来避免join。当然,join在许多情况下是不可避免的,而且应该由应用程序处理。主要的用例:
多对多关系往往是通过链接(link)建模的,这需要join。
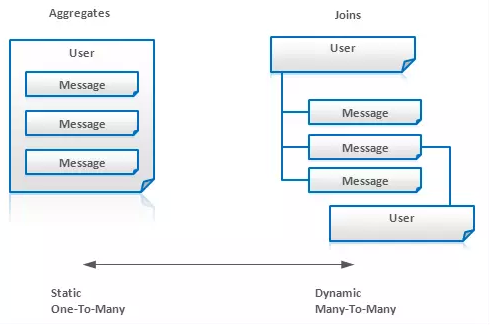
聚合操作往往不适合内部实体会被频繁修改的场景。通常更好的办法是将发生的事情作为一条新的记录保留,并在查询的时候将所有记录做join,而不是去更改值。例如,对于一个信息系统而言,可以用嵌套包含了Message实体的User实体来建模。但是,如果会经常地添加消息,更好的办法可能是把Message提取出来作为独立实体,并在查询时再将其与User进行连接:
适用性:键值存储,文档数据库, BigTable风格数据库,图形数据库
5.一般建模技术
在本节中,我们将讨论适用于各种NoSQL实现的一般建模技术。
1、 原子聚合(Atomic Aggregates)
许多NoSQL解决方案提供了有限的事务支持,虽然有些NoSQL不支持。在某些情况下,人们还可以使用分布式锁或应用程序管理的MVCC机制实现事务行为,但常见的是使用聚合技术来对数据建模,以保证一些ACID特性。
强大的事务处理机制对于关系型数据库而言是不可或缺的,其中原因之一就是规范化的数据通常需要在多个地方进行更新。另一方面,聚合允许一个单个业务实体存储为一个文件,行或键值对,从而可以对其进行原子性的更新:
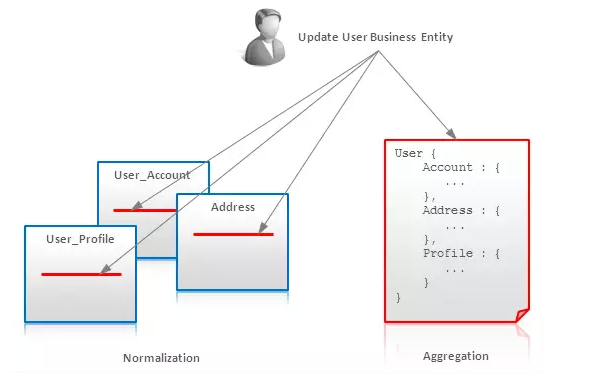
当然,做为一种数据建模技术,原子聚合并不是一个完善的事务型解决方案,但如果存储能提供原子性、锁或者TAS(test-and-set,测试并设置)指令上的一些担保,那原子聚合就是可行的。
(译者注:即将需要事务性操作的业务数据聚合放在一起,存储在一个NoQSQL提供或者应用能提供原子性操作的数据结构中。使用HBase时,将某个用户某个业务的所有数据,如上图,用一行存储就是这种模式的应用。)
适用性:键值存储,文档数据库, BigTable风格数据库
2、 可枚举主键(Enumerable Keys)
也许无序键-值数据模型最大的好处就是可以通过将主键哈希的办法把实体数据分别存储在多个服务器上。排序使事情变得更加复杂,但是即使存储不提供这样的功能,有时应用程序也能利用到有序主键的优势。让我们将对电子邮件建模作为一个例子:
某些NoSQL存储提供原子计数器,能生成一个顺序化的ID。在这种情况下,可以使用userID_messageID作为一个复合键来存储消息。如果最新的消息ID是已知的,那就可以遍历以前的消息。另外,对于任何一个给定的消息ID,也可以向前或向后进行遍历。
也可以将消息分桶(bucket),例如,每天的数据放到一个桶里。这样就允许从任何指定日期或当前日期开始,向前或向后遍历一个邮箱。
适用性:键值存储
(译者注:能利用主键的一些自然或业务维度的特征,将随机读写转换为顺序读写能提高遍历性能,同时能方便应用逻辑编写。但需要注意对分布式部署时并发写的影响以及对于业务的过度耦合。对于无序主键和有序主键的讨论可以参见《HBase权威指南》中Schema设计章节。)
3、 降维(Dimensionality Reduction)
降维这种技术允许将一个多维数据模型映射到一个键-值模型或其他非多维模型。
传统的地理信息系统使用四叉树(Quadtree)或R树(R-tree)的某种变形来做索引。这些结构需要就地完成更新操作,因此在数据量很大时,维护开销相当的大。另一种方法是对这个二维结构进行遍历,并将其扁平化为一个普通的条目列表。使用这种技术的一个众所周知的例子是Geohash。 Geohash使用类似Z形状的路线来扫描整个二维空间,每次移动根据行进方向被编码为0或1。交错位的经度和纬度上的变更移动以及移动。编码过程在下图中进行了说明,其中黑色和红色位分别代表经度和纬度:
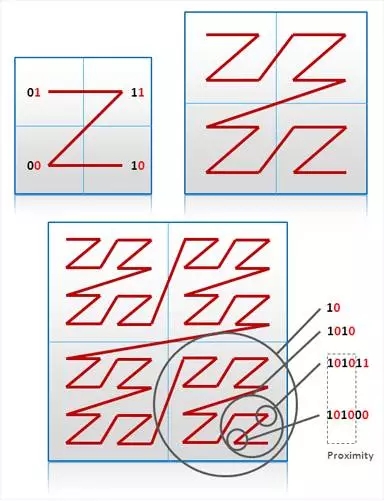
如图所示,Geohash的一个重要特性是能够通过这种逐位编码的近似程度来估计区域之间的距离。Geohash编码允许使用简单普通的数据模型来存储地理信息,比如用有序键值保存空间上的联系。[6.1]讲述了BigTable中的降维技术。更多有关Geohash及其相关技术的信息可以在[6.2]和[6.3]中找到。
适用性:键值存储,文档数据库, BigTable风格的数据库
(译者注:通过交织编码方式来能将原本需要多维度标示的数据,如cube,存储到一维的键值存储系统中,这是一种非常重要的建模模式:提供了不同缩放等级下在多维空间中邻接的数据仍然顺序存储,遍历高效;同时不同主键从前向后的相似度和空间距离的远近相一致,能通过键值的简单顺序比较判断其位置“相似度”。
它的应用远远不只地理信息的表示,有多个维度属性不同粒度的数据表示都能用到这个技术,比如线下销售交易数据通常都有时间和分支结构信息,用户查询销售数据时通常先查询一个大的区域,而且使用的时间段跨度也比较大,需要查询更具体的信息时同时缩小地区和时间来逐步定位细节,这时分支机构和时间就好比是经度维度的两个轴,通过交织时间和分支结构编码的方式建立主键,能很好的满足这种场景。而单纯的使用时间或分支机构做主键或索引却都不能适应上述场景。)
4、 索引表(Index Table)
索引表是一个非常简单的技术,它在内部不支持索引的存储上提供索引的支持。这类存储中最重要的一类就是BigTable风格的数据库。索引表的想法是按照访问模式所需要的键来创建和维护一个特殊的表。例如,有一个主表,存储了可以通过用户ID直接访问的用户帐户。查询指定城市的所有用户可以通过一个额外的用城市做主键的表来支持:
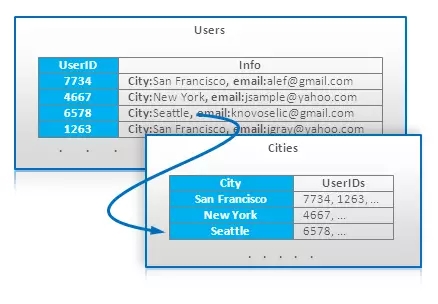
索引表可以在每一个主表记录更新时更新或者使用批模式更新。无论哪种方式,它会导致额外的性能损失,并带来数据一致性上的问题。
可以认为索引表是一种对关系数据库实例化视图的模拟。
适用性: BigTable风格的数据库
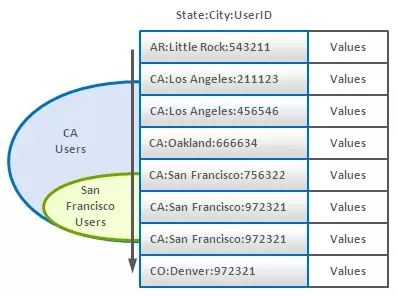
5、 组合主键索引(Composite Key Index)
复合主键是一个非常通用的技术,但尤其在主键有序存储时极其有用。复合主键结合二次排序就能建立起一种多维索引,这和前面所述的降维技术在原理上是类似的。例如,假设我们有一组记录,每个记录是一个用户统计数据。如果我们要按用户来自的地区来聚合这些统计资料,我们可以使用这样的主键格式(State:City:UserId)。如果主键的存储支持通过部分匹配来选取范围(如BigTable风格的数据库),那就可以在特定的州(State)或者城市(City)的记录上做遍历:

适用性: BigTable风格的数据库
(译者注:在使用HBase这类BigTable风格的数据库时,如果主键只使用一个字段/域的信息简直是暴殄天物。使用多字段组合主键不仅能解决主键值不能重复的问题,还能提高对于数据子集二次查找时的性能。)
6、 组合主键的聚合
复合主键不仅可用于作索引,还可以为不同类型分组。让我们来看一个例子。有一个巨大的日志数组,记录了互联网用户和他们访问不同的网站(点击流)的信息。我们的目标是对于每个唯一用户计算出每个站点的点击数量。这类似于下面的SQL查询:

我们可以使用将用户名当前缀的组合主键来对这种情况进行建模:
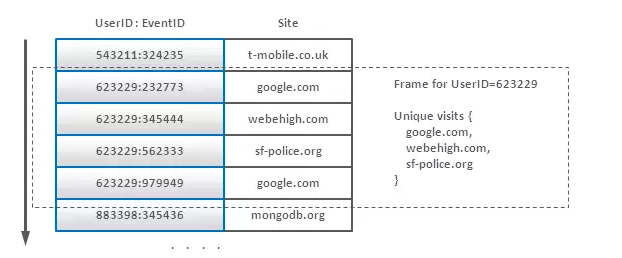
我们的想法是将一个用户的所有记录放置在一起,这样就可能将其全部加载到内存中(一个用户不会产生太多的事件),并使用哈希表或其他方法消除掉重复的网站。另一种技术是将用户做为主键,每次事件到达时将网站添加到这条数据的后部。然而,在大多数实现中,修改数据一般比插入数据的效率低。
适用性:有序键值存储,BigTable风格的数据库
7、 倒排搜索-直接聚合
这种技术更像是数据处理模式,而不是数据建模。然而,数据模型也受这种模式使用的影响。这种技术的主要思想是使用索引来找到满足条件的数据,但聚合操作还是使用原来的方式或者全表扫描。让我们来考虑一个例子。有一堆的日志数据记录了互联网用户和他们访问不同的网站(点击流,click stream)的信息。假设每条记录都包括用户ID、用户所属类别(男性、女性、博主(Blogger)等)、用户来自的城市以及访问的网址。我们的目标是找出满足条件(网址、城市等)的观众,并将这堆观众(如符合标准的用户集合)中出现的不同用户按类别归类。
很明显,满足条件的用户可以通过像{类别->[用户ID]}或{网站->[用户ID]}这样的倒排索引表非常高效地查找到。使用这样的倒排索引,可以得到所要的用户ID的交集或者并集(如果用户ID被存储为排有序的列表或位图,这就可以非常高效地实现),从而获得目标用户。但如果目标用户是使用类似这样的聚集查询描述的:

那如果类别的数量很大,就不能用倒排索引做有效的处理。要解决这个问题,可以用{用户名->[分类集合]}的形式创建直接索引(Direct Index),然后遍历它来建立最终报表。此架构示意如下图:
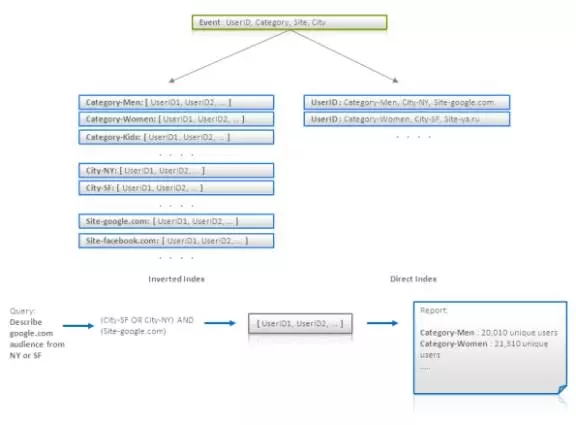
最后需要提示的是,我们需要知道如果随机地访问目标用户中每一个用户ID所对应记录,这样做的效率可能很低。可以通过利用批量查询处理解决这个问题。这意味着,一些数量的用户集可以被预先计算(针对不同的报表条件),然后可以通过对直接索引表或倒排索引表进行一次全表扫描从而计算出这批目标用户的所有报告。
适用性:键值存储,BigTable风格的数据库,文档数据库
分层建模技术(Hierarchy Modeling Techniques)
(译者注:如果需要通过属性或者类别来快速查找对应的实体,这样的索引比不可少。现在很火的用大数据分析用户画像不就需要像{用户标签->用户群}这样的结构么。)
8、 树聚合(Tree Aggregation)
可以将一条单独的记录或者文件的模型建成树,甚至是任意的图(通过去规范化)。
在树会被一次性访问的场景中(例如,博客的整个评论树会被读取,并显示在一篇文章的页面中),这个技术很高效。
搜索和访问任意条目可能有问题。
在大多数NoSQL的实现中,更新操作的效率低下(同相互独立的节点相比)。

适用性:键值存储,文档数据库
(译者注:这是文档型NoSQL的天下,对于无需跨树join的场景,不仅读写效率高,而且能很好的支持局部性的事务应用。)
9、 邻接列表(Adjacency Lists)
邻接列表是一个简单的图型建模方法——每个节点作为一个单独记录建模,其中有包含直接祖先的数组或包含后代的数组。它允许通过其父母或子女的标识符来搜索一个节点,当然也可以通过查询一次前进一步的方式来遍历一个图。无论对于深度优先或广度优先遍历而言,要在整个子树中找到一个给定的节点,这种方法的效率通常不高。
适用性:键值存储,文档数据库
10、 物化路径
物化路径是一种有助于避免在树型结构上做递归遍历的技术。也可以认为这是一种去规范化的技术。其设计思想是用一个节点所有的父节点或者子女节点来标识该节点,这样就有可以不用遍历而得到一个节点的所有祖先节点或者衍生节点:
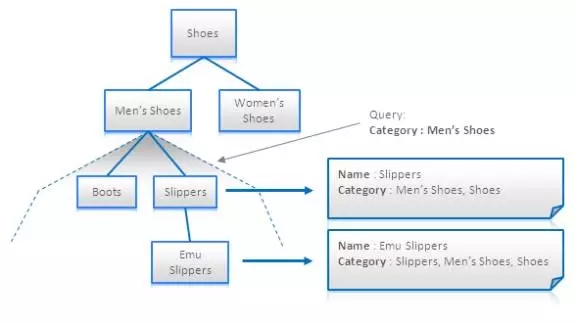
因为这个技术可以将层次结构转换成扁平化的文档,所以它对于全文搜索引擎特别地有用。从上图中可以看出,在男鞋(Men’s Shoes)类别下所有的产品或者子类别可以简单的通过查询一个类别名称而得到。这个查询很短。
物化路径的存储方式可以是一个ID的集合,或者一个是包含级联ID的字符串。后一种方式允许使用正则表达式,来查找那些指定部分的路径符合某种条件的节点。此种方法如在下图(路径也包括了节点自身)所示:
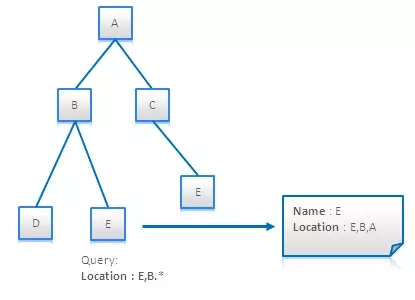
适用性:键值存储,文档数据库,搜索引擎
11、 嵌套集合(Nested Sets)
在对类似树型结构进行建模时,嵌套集合是个标准的做法。它在关系数据库中广泛被使用,然而它也完全适用于键值存储和文档数据库。其设计思想是在用数组来存储树的叶子节点(译者:每个叶子节点对应数组中的一个位置下标),并将每个非叶结点映射为一个叶子节点的范围,这个范围就是开始叶子节点和结束叶子节点在数组中的位置下标。如下图所示:
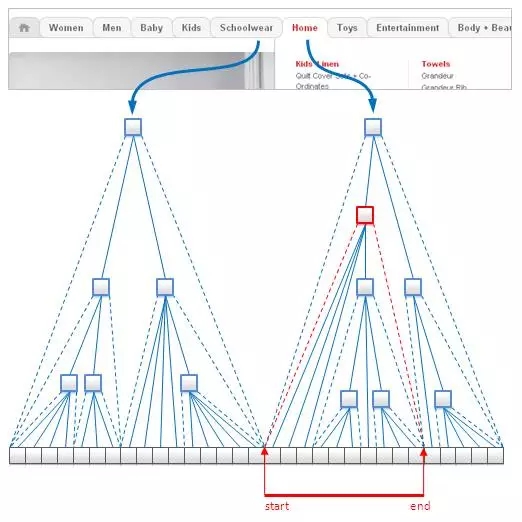
这个结构对于不变数据来讲非常有效,因为它占用的内存小,并且可以在不遍历树的情况下得到一个给定节点的所有叶子节点。然而,因为增加一个叶子节点会带来位置下标的大量更新,所以插入和更新的操作代价是相当的高。
适用性:键值存储,文档数据库
(译者注:适用于字典表、按日期排序的历史日志数据表等。)
12、 扁平化嵌套文件:字段名称编号
搜索引擎通常工作在扁平化的文档之上,即每个文档由两个扁平列表组成,这两个列表分别记录了字段的名称和它对应的值。数据建模的目标是将业务实体映射为简单无结构的文档,但如果实体内部的结构很复杂,这就难办了。一个典型的困难就是层次结构模型,比如要将内部嵌套了文档的文档映射为简单无结构的文档。让我们来考虑下面的例子:
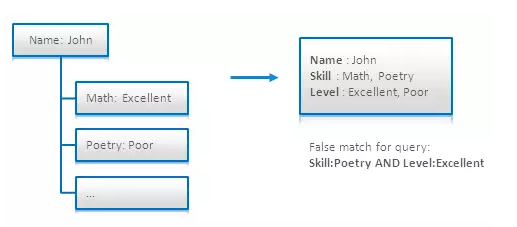
每一个业务实体是一份某种形式的简历,其中包含了这个人的名字,和枚举了他或她所具有的技能以及相应技能水平的列表。为这样的实体建模的一个很显然的方式就是是建立的简单无结构文档,里面包含Skill和Level字段的列表。这种模式允许通过技能或水平来搜索某个人,但将这两个字段联合起来搜索却容易导致虚假匹配,正如上图所述。(译者:简单的AND操作不能感知技能以及其水平的对应关系。)
在[4.6]中提出了一种解决这个问题的方法。这项技术的主要思想是将每一项技能以及相应的水平联合起来组成一个配对(pair),并使用下标标识成为Skill_i和Level_i。在搜索时需要同时查询所有这些对值(查询中OR条件语句的个数是和一个人所能具有的技能的最大值相同):
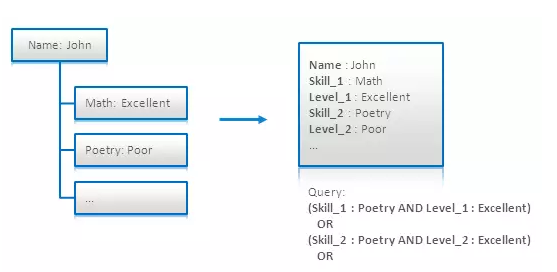
这种方法实际上没有可扩展性,因为随着嵌套结构的数目的增长会迅速增加查询的复杂度。
适用性:搜索引擎
(译者注:如果你对于使用索引来加速查询无计可施,尤其对用户将来如何查询数据一无所知,无法在设计模型时进行优化时,这就是最后的稻草:使用全文搜索工具。它至少能在可接受的时间内能查出点东西来^o^。)
13、 扁平化嵌套文件:近似查询
在[4.6]中还描述了另一种可以解决嵌套文件问题的技术。它的想法是使用近似的查询,将文档中单词之间的距离限制在可以接受的距离范围以内。在下面的图中,所有的技能和水平都被索引到了一个叫SkillAndLevel的域。使用“Excellent”和“Poetry”进行查询表示的话,就会查找到这两个单词邻接的条目:
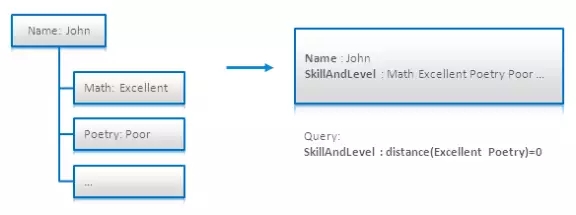
[4.3]讲述了在Solr之上使用这种技术的一个成功案例。
适用性:搜索引擎
(译者注:同上,但查询召回率高,会出现假匹配,有脏数据。)
14、 批量图处理
在浏览一个指定节点的相邻节点或浏览两个或几个节点之间的关系时,像Neo4j这样的图形数据库的性能出奇的好。然而,通用图形数据库对大图做全局性处理不是很高效,因为扩展性不好。分布式图形处理可以使用MapReduce或者消息传递(Message Passing)模式来实现。我以前的一篇文章就介绍了一种这样的模式。这种方法使用了键值存储、文档数据库和BigTable风格的数据库,能处理大型的图形。
适用性:键值存储,文档数据库,BigTable风格的数据库
作者介绍:陈飚,Cloudera售前技术经理、行业领域顾问、资深方案架构师,原Intel Hadoop发行版核心开发人员。2006年加入Intel编译器部门从事服务器中间件软件开发,擅长服务器软件调试与优化,曾带领团队开发出世界上性能领先的 XSLT 语言处理器。2010 年后开始Hadoop 产品开发及方案顾问,先后负责Hadoop 产品化、HBase 性能调优,以及行业解决方案顾问,已在交通、通信等行业成功实施并支持多个上百节点Hadoop 集群。
欢迎加入本站公开兴趣群
软件开发技术群
兴趣范围包括:Java,C/C++,Python,PHP,Ruby,shell等各种语言开发经验交流,各种框架使用,外包项目机会,学习、培训、跳槽等交流
QQ群:26931708
Hadoop源代码研究群
兴趣范围包括:Hadoop源代码解读,改进,优化,分布式系统场景定制,与Hadoop有关的各种开源项目,总之就是玩转Hadoop
QQ群:288410967
正文到此结束
- 本文标签: 博客 Atom 定制 ip cat map 管理 HTML list 企业 http message 编译 shell 产品 NOSQL 大数据 App value 开源 统计 文章 服务器 mail 互联网 sql 开源项目 空间 key 锁 src python 站点 自动化 数据库 HBase IDE 设计模式 Excel 开发 schema 数据库建模 PHP db Oracle apr redis 基本原则 实例 缩小 solr 数据模型 apache tab description 集群 数据 时间 遍历 主键值 QQ群 ACE ORM java Hadoop 搜索引擎 调试 代码 MongoDB 一对多 HBase权威指南 处理器 正则表达式 测试 突破 网站 UI 电子商务 Cassandra 软件 线下
- 版权声明: 本文为互联网转载文章,出处已在文章中说明(部分除外)。如果侵权,请联系本站长删除,谢谢。
- 本文海报: 生成海报一 生成海报二
热门推荐










相关文章

近期评论
-
你这基本没有更新呀,最近文章显示还是2019年的文章。不符合要求哈
-
关键词:慕云博客 链接:https://www.lilun.me 描述:分享原创文字的个人博客
-
-
-
可以提供一下源码吗
-
不是商业站,鸡娃学习笔记
-
-
-
-
听他们说很厉害的样子
Loading...
![[HBLOG]公众号](http://www.liuhaihua.cn/img/qrcode_gzh.jpg)

