网易视频云:impala笔记
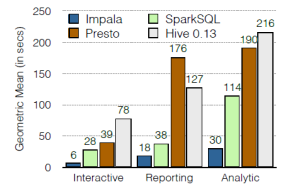
Impala是hadoop上交互式MPP SQL引擎, 也是目前性能最好的开源SQL-on-hadoop方案。 如下图所示, impala性能超过SparkSQL、 Presto、 Hive。
impala与hadoop生态结合紧密
(1) HDFS是impala最主要的数据源。 除此之外, impala也支持HBase,甚至支持S3存储。
(2) impala表定义存储在hive metastore中, 支持读取hive表定义。
(3) 支持Parquet, RCFile, sequence file, txt等常见文件格式, 其中Parquet是列存格式,性能最佳。
(4) 集成YARN。
SQL支持度:
支持SQL92中的大部分select语句, 以及SQL2003标准中的分析函数。 不支持DELETE和UPDATE, 但是支持批量装载数据(insert into select, LOAD DATA) 和批量删除数据(drop partition)。除此之外, 用户也可直接操作HDFS文件实现数据装载和清理。
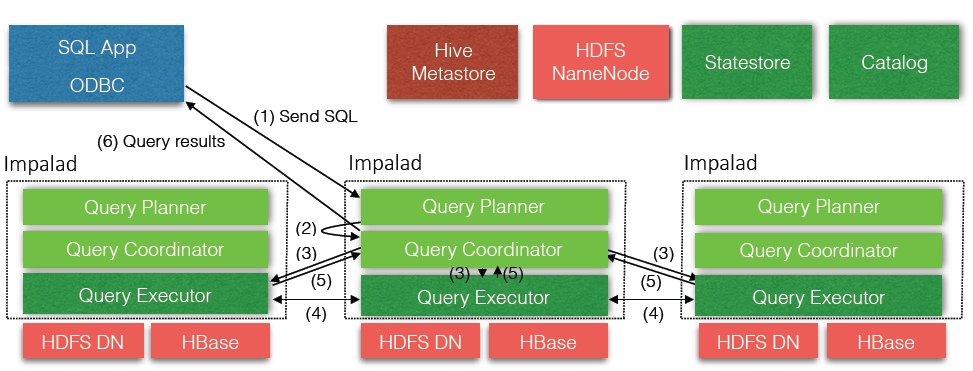
架构如上图所示。
• impalad是最核心组件, 负责接收用户查询请求(ODBC协议), 生成查询计划, 协调其他impalad执行查询计划, 并汇总查询结果返回给用户。 impalad部署在每个datanode上, 一般来说impalad只读取本机数据, 尽量避免远程访问HDFS文件数据。
• statestore负责集群元数通知和分发。 元数据包括catalog和集群成员关系等, SQL查询依赖于这些元数据, 所以元数据会缓存在每个impalad节点。 statestore通过publish/subsriber机制确保impalad及时拿到最新元数据, 但是它本身不需要理解元数据, 也不需要持久化元数据 。 statestore宕机重启时, 元数据可从权威数据源或者从impalad重构, 因此statestore虽是全局单点, 但也不影响可用性。
• catalogd负责数据库、表等catalog信息, 实现DDL功能, catalog更新通过statestore分发给impalad。
查询执行
impalad分为frontend和backend两个层次, frondend用java实现(通过JNI嵌入impalad), 负责查询计划生成, 而backend用C++实现, 负责查询执行。
frontend生成查询计划分为两个阶段:(1)生成单机查询计划,单机执行计划与关系数据库执行计划相同,所用查询优化方法也类似。(2)生成分布式查询计划。 根据单机执行计划, 生成真正可执行的分布式执行计划,降低数据移动, 尽量把数据和计算放在一起。
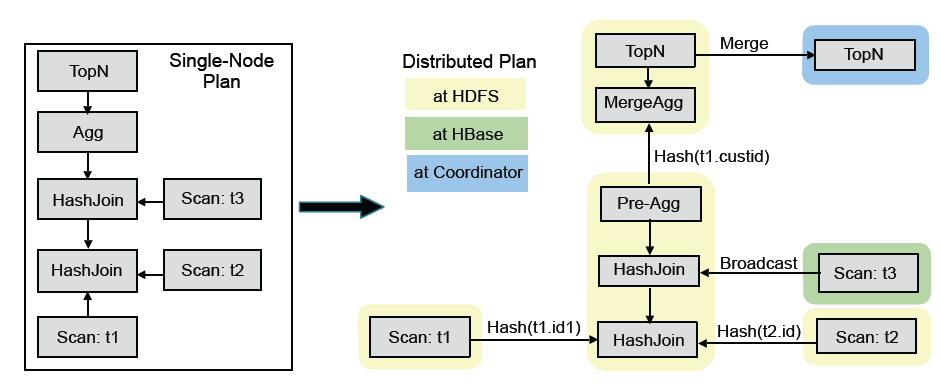
上图是SQL查询例子, 该SQL的目标是在三表join的基础上算聚集, 并按照聚集列排序取topN。 impala的查询优化器支持代价模型: 利用表和分区的cardinality,每列的distinct值个数等统计数据, impala可估算执行计划代价, 并生成较优的执行计划。 上图左边是frontend查询优化器生成的单机查询计划, 与传统关系数据库不同, 单机查询计划不能直接执行, 必须转换成如图右半部分所示的分布式查询计划。 该分布式查询计划共分成6个segment(图中彩色无边框圆角矩形), 每个segment是可以被单台服务器独立执行的计划子树。
impala支持两种分布式join方式, 表广播和哈希重分布:表广播方式保持一个表的数据不动, 将另一个表广播到所有相关节点(图中t3); 哈希重分布的原理是根据join字段哈希值重新分布两张表数据(譬如图中t1和t2)。分布式计划中的聚集函数分拆为两个阶段执行。第一步针对本地数据进行分组聚合(Pre-AGG)以降低数据量, 并进行数据重分步, 第二步, 进一步汇总之前的聚集结果(mergeAgg)计算出最终结果。 与聚集函数类似, topN也是分为两个阶段执行, (1)本地排序取topN,以降低数据量; (2) merge sort得到最终topN结果。
Backend从frontend接收plan segment并执行, 执行性能非常关键,impala采取的查询性能优化措施有
• 向量执行。 一次getNext处理一批记录, 多个操作符可以做pipeline。
• LLVM编译执行, CPU密集型查询效率提升5倍以上。
• IO本地化。 利用HDFS short-circuit local read功能,实现本地文件读取
• Parquet列存,相比其他格式性能最高提升5倍。
资源管理
impala通常与MR等离线任务运行在一个集群上, 通过YARN统一管理资源, 如何同时满足交互式查询和离线查询两种需求具有较大挑战性。 YARN通过全局唯一的Resource Mananger调度资源, 好处是RM拥有整个集群全局信息,能做出更好调度决策, 缺点是资源分配的性能不足。 Impala每个查询都需要分配资源, 当每秒查询数上千时, YARN资源分配的响应时间变的很长, 影响到查询性能。 目前通过两个措施解决这个问题:(1)引入快速、非集中式的查询准入机制, 控制查询并发度。(2)LLAM(low latency application master)通过缓存资源, 批量分配,增量分配等方式实现降低资源分配延时。
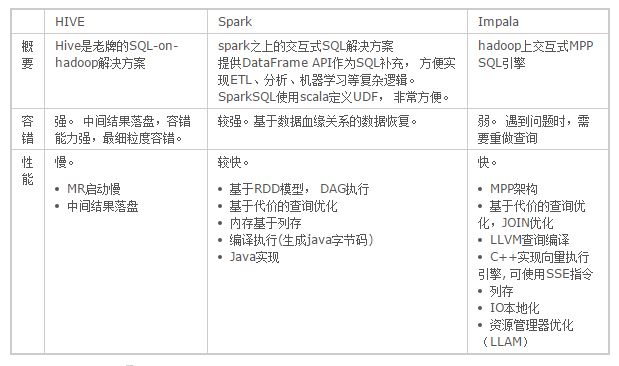
相关系统对比
正文到此结束
热门推荐










相关文章

近期评论
-
你这基本没有更新呀,最近文章显示还是2019年的文章。不符合要求哈
-
关键词:慕云博客 链接:https://www.lilun.me 描述:分享原创文字的个人博客
-
-
-
可以提供一下源码吗
-
不是商业站,鸡娃学习笔记
-
-
-
-
听他们说很厉害的样子
Loading...
![[HBLOG]公众号](http://www.liuhaihua.cn/img/qrcode_gzh.jpg)

