Java Streams,第 3 部分: Streams 的幕后原理
本系列 的前两篇文章探讨了如何使用 Java SE 8 中添加的 java.util.stream 库,该库使得声明性地表达数据集上的查询变得很容易。在许多情况下,该库会确定如何高效地执行查询,而不需要用户协助。但在性能至关重要时,了解该库的内部工作原理很有价值,这样您就能够消除低效性的可能来源。第三期文章将探索 Streams 实现的工作原理,解释一些可通过声明性方法实现的优化。
流管道
一个 流管道 包含一个 流来源 、0 或多个 中间操作 ,以及一个 终止操作 。流来源可以是集合、数组、生成器函数或其他任何适当地提供了其元素的访问权的数据源。中间操作将流转换为其他流 — 通过过滤元素 ( filter() ),转换元素 ( map() ),排序元素 ( sorted() ),将流截断为一定大小 ( limit() ),等等。终止操作包括聚合( reduce() 、 collect() ),搜索 ( findFirst() ) 和迭代 ( forEach() )。
关于本系列
借助 java.util.stream 包,您可以简明地、声明性地表达集合、数组和其他数据源上可能的并行批量操作。在 Java 语言架构师 Brian Goetz 编写的这个系列 中,全面了解 Streams 库并学习如何最充分地使用它。
流管道是惰性构造的。构造流来源不会计算流的元素,而是会确定在必要时如何找到元素。类似地,调用中间操作不会在元素上执行任何计算;只会将另一个操作添加到流描述的末尾。仅在调用终止操作时,管道才会实际执行相应的工作:计算元素,应用中间操作,以及应用终止操作。这种执行方法使得执行多项有趣的优化成为可能。
流来源
学习更多知识。开发更多项目。联系更多同行。
全新的 developerWorks Premium 订阅计划提供了强大的开发工具和资源,包括 500 篇通过 Safari Books Online 提供的顶级技术文章(包含作者的 Java 并发性实战 )、最重要开发人员活动的大幅折扣、最新的 O'Reilly 大会的视频录像,等等。立即注册。
流来源有一种称为 Spliterator 的抽象来描述。顾名思义, Spliterator 组合了两种行为:访问来源的元素(迭代),可能分解输入来源来实现并行执行(拆分)。
尽管 Spliterator 包含与 Iterator 相同的基本行为,但它没有扩展 Iterator ,而采用了不同的元素访问方法。 Iterator 有两个方法: hasNext() 和 next() ;访问下一个元素可能涉及到(但不需要)调用这两个方法。因此,正确编写 Iterator 需要一定量的防御性和重复性编码。(如果客户端没有在调用 next() 之前调用 hasNext() 会怎么样?如果它调用 hasNext() 两次会怎么样?)此外,这种两方法协议通常需要一定水平的有状态性,比如前窥 (peek ahead ) 一个元素(并跟踪您是否已前窥)。这些要求累积形成了大量的每元素访问开销。
语言中拥有拉姆达表达式使 Spliterator 能够采取一种通常更加高效的元素访问方法 — 而且更容易正确地编码。 Spliterator 有两个访问元素的方法:
boolean tryAdvance(Consumer<? super T> action); void forEachRemaining(Consumer<? super T> action);
tryAdvance() 方法尝试处理单个元素。如果没有元素, tryAdvance() 只会返回 false ;否则,它会前移游标,将当前元素传递给所提供的处理函数并返回 true 。 forEachRemaining() 方法处理所有剩余的元素,将它们一次一个地传递给所提供的处理函数。
即使忽略了并行分解的可能性, Spliterator 抽象也是一个 “更好的迭代器” — 更容易编写,更容易使用,而且通常具有更低的每元素访问开销。但 Spliterator 抽象还扩展到了并行分解领域。一个 spliterator 描述剩余元素的序列,调用 tryAdvance() 或 forEachRemaining() 元素访问方法来在该序列中前进。为了拆分来源,以便两个线程可分别处理输入的不同部分, Spliterator 提供了一个 trySplit() 方法:
Spliterator<T> trySplit();
trySplit() 的行为是尝试将剩余元素拆分为两个部分,这两部分最好具有类似的大小。如果 Spliterator 可以拆分, trySplit() 会将所描述元素的初始部分拆分为一个新 Spliterator ,将其返回,并调整其状态,以便描述拆分后的部分后面的元素。如果来源无法拆分, trySplit() 将会返回 null ,表明无法拆分且调用方应按顺序继续处理。对于很重要的来源(例如数组、 List 或 SortedSet ), trySplit() 必须保留此顺序;它必须将剩余元素的初始部分拆分到一个新的 Spliterator 中,而且当前 spliterator 必须按照与原始顺序相同的顺序描述剩余元素。
JDK 中的 Collection 实现都已配备了高质量的 Spliterator 实现。允许一些来源获得比其他来源更好的实现:包含多个元素的 ArrayList 始终可以干净且均匀地进行拆分; LinkedList 的拆分效率一直很差;而且基于哈希值和基于树的数据集通常能够进行比较不错的拆分。
构建流管道
流管道是通过构造流来源及其中间操作的链接列表表示来构建的。在内部表示中,管道的每个阶段都通过一个 流标志 位图来描述,该位图描述了在流管道的这一阶段已知的元素信息。流使用这些标志优化流的构造和执行。表 1 展示了流标志和它们的解释。
表 1. 流标志
| 流标志 | 解释 |
|---|---|
SIZED | 流的大小已知。 |
DISTINCT | 依据用于对象流的 Object.equals() 或用于原语流的 == ,流的元素将有所不同。 |
SORTED | 流的元素按自然顺序排序。 |
ORDERED | 流有一个有意义的遇到顺序(请参阅 “” 部分)。 |
来源阶段的流标志来自 spliterator 的 characteristics 位图(spliterator 支持比流更大的标志集)。高质量的 spliterator 实现不仅提供了高效的元素访问和拆分,还会描述元素的特征。(例如,一个 HashSet 的 spliterator 报告 DISTINCT 特征,因为已知一个 Set 的元素是不同的。)
“ 在某些情况下,Streams 可以使用来源和之前的操作的知识来完全省略某个操作。 ”
每个中间操作都对流标志具有已知的影响;一个操作可设置、清除或保留每个标志的设置。例如, filter() 操作保留 SORTED 和 DISTINCT 标志,但清除 SIZED 标志; map() 操作清除 SORTED 和 DISTINCT 标志,但保留 SIZED 标志; sorted() 操作保留 SIZED 和 DISTINCT 标志,但注入 SORTED 标志。构造阶段的链接列表表示时,会将前一个阶段的标志与当前阶段的行为相组合,以获得当前阶段的一组新标志。
在某些情况下,标志使完全省略一个操作成为可能,就像清单 1 中的流管道一样。
清单 1. 可自动省略操作的流管道
TreeSet<String> ts = ... String[] sortedAWords = ts.stream() .filter(s -> s.startsWith("a")) .sorted() .toArray(); 来源阶段的流标志包含 SORTED ,因为来源是一个 TreeSet 。 filter() 方法保留了 SORTED 标志,所以过滤阶段的流标志也包含 SORTED 标志。通常, sorted() 方法的结果是构造一个新的管道阶段,将它添加到管道末尾,然后返回新阶段。但是,因为已知元素是按自然顺序排序的,所以 sorted() 方法是一个空操作 — 它仅返回前一个阶段(过滤阶段),因为排序是多余的。(类似地,如果元素已知是 DISTINCT ,那么可以完全消除 distinct() 操作。)
执行流管道
发起终止操作时,流实现会挑选一个执行计划。中间操作可划分为 无状态 ( filter() 、 map() 、 flatMap() )和 有状态 ( sorted() 、 limit() 、 distinct() )操作。无状态操作是可在元素上执行而无需知道其他任何元素的操作。例如,过滤操作只需检查当前元素来确定是包含还是消除它,但排序操作必须查看所有元素之后才知道首先发出哪个元素。
如果管道按顺序执行,或者并行执行,但包含所有无状态操作,那么它可以在一轮中计算。否则,管道会划分为多个部分(在有状态操作边界上划分)并分多轮计算。
终止操作是 短路 ( allMatch() 、 findFirst() )或 非短路 ( reduce() 、 collect() 、 forEach() )操作。如果终止操作是非短路操作,那么可以批量处理数据(使用来源 spliterator 的 forEachRemaining() 方法,进一步减少访问每个元素的开销);如果它是短路操作,则必须一个元素处理一次(使用 tryAdvance() )。
对于顺序执行,Streams 构造了一个 “机器” — 一个 Consumer 对象链,其结构与管道结构相符。其中每个 Consumer 对象知道下一个阶段;当它收到一个元素(或被告知没有更多元素)时,它会将 0 或多个元素发送到链中的下一个阶段。例如,与 filter() 阶段有关联的 Consumer 将过滤器谓词应用于输入元素,并将它发送或不发送到下一个阶段;与 map() 阶段有关联的 Consumer 将映射函数应用于输入元素,并将结果发送到下一个阶段。与有状态操作(比如 sorted() )有关联的 Consumer 会缓冲元素,直到它看到输入的末尾,然后将排序的数据发送到下一个阶段。机器中的最后一个阶段将实现终止操作。如果此操作生成了结果,比如 reduce() 或 toArray() ,该阶段可充当此结果的累加器。
图 1 显示了以下流管道的 “流机器” 的动画(或者在某些浏览器中显示为快照)。(在图 1 中,黄色、绿色和蓝色块按顺序进入机器顶部的第一个阶段。在第一个阶段,每个块压缩为更小的块,然后进入第二个阶段。在这里,一个类似吃豆人的游戏人物吃掉每个黄色块,仅让绿色和蓝色块落入第三个阶段。压缩的蓝色和绿色块交替显示在计算机屏幕上。)
blocks.stream() .map(block -> block.squash()) .filter(block -> block.getColor() != YELLOW) .forEach(block -> block.display());
图 1. 流机器(动画来自 Tagir Valeev)
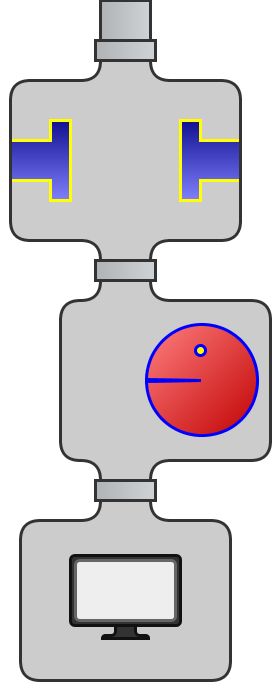
并行执行将会执行类似的操作,但不会创建单个机器,每个工作线程将会获取自己的机器副本并将其数据节提供给它,然后将每个线程机器的结果与其他机器的结果合并,生成最终结果。
流管道的执行也可以使用流标志来优化。例如, SIZED 标志指示最终结果的大小是已知的。 toArray() 终止操作可使用此标志预先分配正确大小的数组;如果没有 SIZED 标志,则需要猜测数组大小,并在猜测错误时复制数据。
“ 当性能至关重要时,了解库的内部工作原理非常重要。 ”
预先设置大小的优化在并行流执行中更有效。除了 SIZED 标志之外,另一个 spliterator 特征 SUBSIZED 表示不仅大小已知,而且如果 spliterator 已拆分,则拆分大小也是已知的。(数组和 ArrayList 就属于这种情况,但其他可拆分来源,比如树,不一定属于这种情况。)如果有 SUBSIZED 特征,在并行执行中, toArray() 操作可为整个结果分配一个正确大小的数组,各个线程(分别处理输入的不同部分)可将它们的结果直接写入数组的正确部分 — 无需同步或复制。(缺少 SUBSIZED 标志时,会将每一部分收集到一个中间数组中,然后复制到最终位置。)
遇到顺序
另一个影响库的优化能力的微妙的考虑事项是 遇到顺序 。遇到顺序指的是来源分发元素的顺序是否对计算至关重要。一些来源(比如基于哈希的集合和映射)没有有意义的遇到顺序。流标志 ORDERED 描述了流是否有有意义的遇到顺序。JDK 集合的 spliterator 会根据集合的规范来设置此标志;一些中间操作可能注入 ORDERED ( sorted() ) 或清除它 ( unordered() )。
如果流没有遇到顺序,大部分流操作都必须遵守该顺序。对于顺序执行,会自动保留遇到顺序,因为元素会按遇到它们的顺序自然地处理。甚至在并行执行中,许多操作(无状态中间操作和一些终止操作(比如 reduce() )),遵守遇到顺序不会产生任何实际成本。但对于其他操作(有状态中间操作,其语义与遇到顺序关联的终止操作,比如 findFirst() 或 forEachOrdered() ),在并行执行中遵守遇到顺序的责任可能很重大。如果流有一个已定义的遇到顺序,但该顺序对结果没有意义,那么可以通过使用 unordered() 操作删除 ORDERED 标志,加速包含顺序敏感型操作的管道的顺序执行。
作为对遇到顺序敏感的操作的示例,可以考虑 limit() ,它会在指定大小处截断一个流。在顺序执行中实现 limit() 很简单:保留一个已看到多少元素的计数器,在这之后丢弃任何元素。但是在并行执行中,实现 limit() 要复杂得多;您需要保留 前 N 个元素。此要求大大限制了利用并行性的能力;如果输入划分为多个部分,您只有在某个部分之前的所有部分都已完成后,才知道该部分的结果是否将包含在最终结果中。因此,该实现一般会错误地选择不使用所有可用的核心,或者缓存整个试验性结果,直到您达到目标长度。
如果流没有遇到顺序, limit() 操作可以自由选择 任何 N 个元素,这让执行效率变得高得多。知道元素后可立即将其发往下游,无需任何缓存,而且线程之间唯一需要执行的协调是发送一个信号来确保未超出目标流长度。
遇到顺序成本的另一个不太常见的示例是排序。如果遇到顺序有意义,那么 sorted() 操作会实现一种 稳定 排序(相同的元素按照它们进入输入时的相同顺序出现在输出中),而对于无序的流,稳定性(具有成本)不是必需的。 distinct() 具有类似的情况:如果流有一个遇到顺序,那么对于多个相同的输入元素, distinct() 必须发出其中的 第一个 ,而对于无序的流,它可以发出任何元素 — 同样可以获得高效得多的并行实现。
在您使用 collect() 聚合时会遇到类似的情形。如果在无序流上执行 collect(groupingBy()) 操作,与任何键对应的元素都必须按它们在输入中出现的顺序提供给下游收集器。此顺序对应用程序通常没有什么意义,而且任何顺序都没有意义。在这些情况下,可能最好选择一个 并发 收集器(比如 groupingByConcurrent() ),它可以忽略遇到顺序,并让所有线程直接收集到一个共享的并发数据结构中(比如 ConcurrentHashMap ),而不是让每个线程收集到它自己的中间映射中,然后再合并中间映射(这可能产生很高的成本)。
创建流
“ 可以轻松地调整现有数据结构来分发流。 ”
尽管 JDK 中的许多类已被改进来用作流来源,但同样可以轻松地调整现有数据结构来分发流。要从任意数据源创建流,需要为该流的元素创建一个 Spliterator ,并将该 spliterator 连同一个 boolean 标志传递给 StreamSupport.stream() ,该标志表明结果流应是顺序的还是并行的。
Spliterator 实现的质量可能存在巨大差别,以平衡使用 spliterator 作为来源的流管道的实现工作与性能。 Spliterator 接口有多种可选的方法,比如 trySplit() 。如果您不想实现拆分,可以从 trySplit() 返回 null ,但这意味着使用这个 Spliterator 作为来源的流将无法利用并行性来加速计算。
影响 spliterator 质量的考虑因素包括:
- spliterator 是否报告了准确的大小?
- spliterator 能否拆分输入?
- 它能否将输入拆分为几乎相等的部分?
- 所拆分部分的大小是否可预测(通过
SUBSIZED特征反映)? - spliterator 是否报告了所有相关特征?
创建 spliterator 的最简单方法(但会导致最差的结果质量)是将 Iterator 传递给 Spliterators.spliteratorUnknownSize() 。您可以通过将 Iterator 和一个大小传递给 Spliterators.spliterator 来获得稍微好点的 spliterator。但是如果流性能很重要(尤其是并行性能),可以实现完整的 Spliterator 接口(包括所有适用的特征)。集合类(比如 ArrayList 、 TreeSet 和 HashMap )的 JDK 来源提供了一些高质量的 spliterator 示例,您可针对您自己的数据结构来模仿它们。
第 3 部分的小结
尽管开箱即用的 Streams 的性能通常很好(有时比相应的命令式代码更好),但牢固掌握 Streams 的幕后工作原理使您能够最高效地使用这个库,并创建自定义适配器来从任何数据源中获取流。 Java Streams 系列接下来的两期将深入探讨并行性。
正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](http://www.liuhaihua.cn/img/qrcode_gzh.jpg)

