教机器学习摘要
文本摘要是自然语言处理中比较难的一个任务,别说是用机器来做文摘了,就连人类做文摘的时候都需要具备很强的语言阅读理解能力和归纳总结能力。新闻的摘要要求编辑能够从新闻事件中提取出最关键的信息点,重新组织语言来写摘要;paper的摘要需要作者从全文中提取出最核心的工作,然后用更加精炼的语言写成摘要;综述性的paper需要作者通读N篇相关topic的paper之后,用最概括的语言将每篇文章的贡献、创新点写出来,并且对比每篇文章的方法各有什么优缺点。自动文摘本质上做的一件事情是信息过滤,从某种意义上来说,和推荐系统的功能有一点像,都是为了让大家更快地找到感兴趣的东西,只是用了不同的手段而已。
问题描述
文本摘要问题按照文档数量可以分为单文档摘要和多文档摘要问题,按照实现方式可以分为提取式(extractive)和摘要式(abstractive)。摘要问题的特点是输出的文本要比输入的文本少很多很多,但却蕴藏着非常多的有效信息在内。有一点点感觉像是主成分分析(PCA),作用也与推荐系统有一点像,都是为了解决信息过载的问题。现在绝大多数应用的系统都是extractive的,这个方法比较简单但存在很多的问题,简单是因为只需要从原文中找出相对来说重要的句子来组成输出即可,系统只需要用模型来选择出信息量大的句子然后按照自然序组合起来就是摘要了。但是摘要的连贯性、一致性很难保证,比如遇到了句子中包含了代词,简单的连起来根本无法获知代词指的是什么,从而导致效果不佳。研究中随着deep learning技术在nlp中的深入,尤其是seq2seq+attention模型的“横行”,大家将abstractive式的摘要研究提高了一个level,并且提出了copy mechanism等机制来解决seq2seq模型中的OOV问题。
本文探讨的是用abstractive的方式来解决sentence-level的文本摘要问题,问题的定义比较简单,输入是一个长度为M的文本序列,输出是一个长度为N的文本序列,这里M>>N,并且输出文本的意思和输入文本的意思基本一致,输入可能是一句话,也可能是多句话,而输出都是一句话,也可能是多句话。
语料
这里的语料分为两种,一种是用来训练深度学习模型的大型语料,一种是用来参加评测的小型语料。
1、 DUC
这个网站提供了文本摘要的比赛,2001-2007年在这个网站,2008年开始换到这个网站 TAC 。很官方的比赛,各大文本摘要系统都会在这里较量一番,一决高下。这里提供的数据集都是小型数据集,用来评测模型的。
2、 Gigaword
该语料非常大,大概有950w篇新闻文章,数据集用headline来做summary,即输出文本,用first sentence来做input,即输入文本,属于单句摘要的数据集。
3、CNN/Daily Mail
该语料就是我们在机器阅读理解中用到的语料,该数据集属于多句摘要。
4、Large Scale Chinese Short Text Summarization Dataset( LCSTS )[6]
这是一个中文短文本摘要数据集,数据采集自新浪微博,给研究中文摘要的童鞋们带来了福利。
模型
本文所说的模型都是abstractive式的seq2seq模型。nlp中最早使用seq2seq+attention模型来解决问题的是machine translation领域,现如今该方法已经横扫了诸多领域的排行榜。
seq2seq的模型一般都是如下的结构[1]:
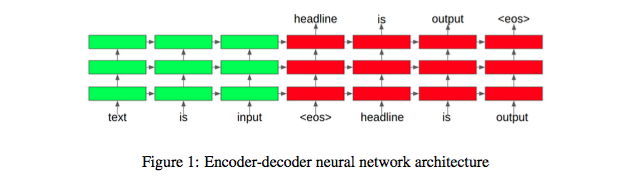
encoder部分用单层或者多层rnn/lstm/gru将输入进行编码,decoder部分是一个语言模型,用来生成摘要。这种生成式的问题都可以归结为求解一个条件概率问题p(word|context),在context条件下,将词表中每一个词的概率值都算出来,用概率最大的那个词作为生成的词,依次生成摘要中的所有词。这里的关键在于如何表示context,每种模型最大的不同点都在于context的不同,这里的context可能只是encoder的表示,也可能是attention和encoder的表示。decoder部分通常采用beam search算法来做生成。
1、Complex Attention Model[1]
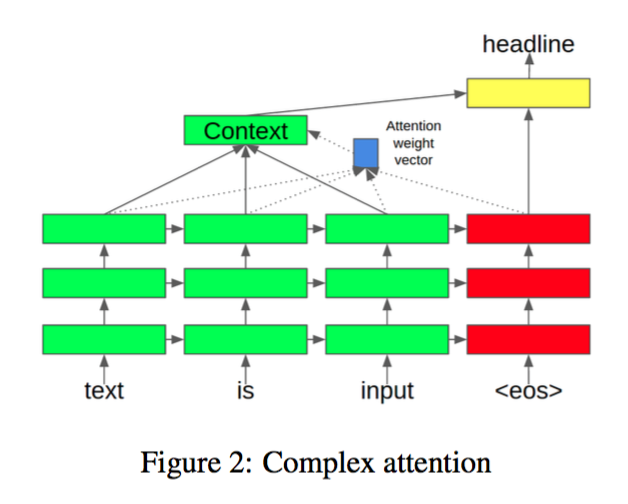
模型中的attention weights是用encoder中每个词最后一层hidden layer的表示与当前decoder最新一个词最后一层hidden layer的表示做点乘,然后归一化来表示的。
2、Simple Attention Model[1]
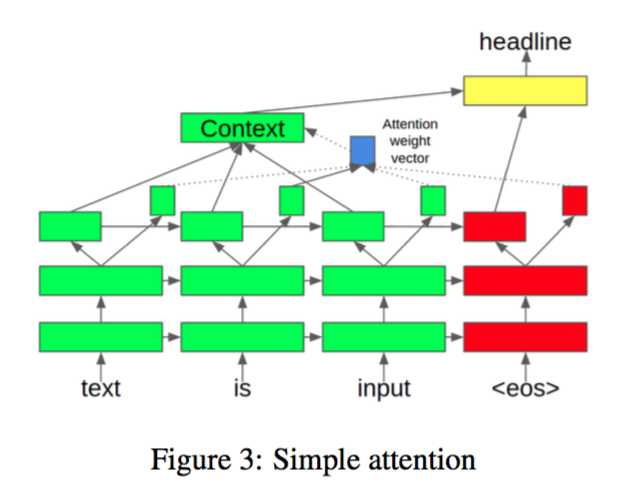
模型将encoder部分在每个词最后一层hidden layer的表示分为两块,一小块用来计算attention weights的,另一大块用来作为encoder的表示。这个模型将最后一层hidden layer细分了不同的作用。
3、Attention-Based Summarization(ABS)[2]
这个模型用了三种不同的encoder,包括:Bag-of-Words Encoder、Convolutional Encoder和Attention-Based Encoder。Rush是HarvardNLP组的,这个组的特点是非常喜欢用CNN来做nlp的任务。这个模型中,让我们看到了不同的encoder,从非常简单的词袋模型到CNN,再到attention-based模型,而不是千篇一律的rnn、lstm和gru。而decoder部分用了一个非常简单的NNLM,就是Bengio[10]于2003年提出来的前馈神经网络语言模型,这一模型是后续神经网络语言模型研究的基石,也是后续对于word embedding的研究奠定了基础。可以说,这个模型用了最简单的encoder和decoder来做seq2seq,是一次非常不错的尝试。
4、ABS+[2]
Rush提出了一个纯数据驱动的模型ABS之后,又提出了一个abstractive与extractive融合的模型,在ABS模型的基础上增加了feature function,修改了score function,得到了这个效果更佳的ABS+模型。
5、Recurrent Attentive Summarizer(RAS)[3]
这个模型是Rush的学生提出来的,输入中每个词最终的embedding是各词的embedding与各词位置的embedding之和,经过一层卷积处理得到aggregate vector:
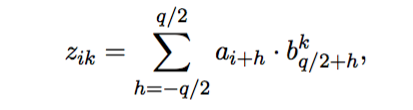
根据aggregate vector计算context(encoder的输出):

其中权重由下式计算:
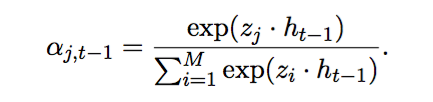
decoder部分用RNNLM来做生成,RNNLM是在Bengio提出的NNLM基础上提出的改进模型,也是一个主流的语言模型。
6、big-words-lvt2k-1sent模型[4]
这个模型引入了large vocabulary trick(LVT)技术到文本摘要问题上。本方法中,每个mini batch中decoder的词汇表受制于encoder的词汇表,decoder词汇表中的词由一定数量的高频词构成。这个模型的思路重点解决的是由于decoder词汇表过大而造成softmax层的计算瓶颈。本模型非常适合解决文本摘要问题,因为摘要中的很多词都是来自于原文之中。
7、words-lvt2k-2sent-hieratt模型[4]

文本摘要中经常遇到这样的问题,一些关键词出现很少但却很重要,由于模型基于word embedding,对低频词的处理并不友好,所以本文提出了一种decoder/pointer机制来解决这个问题。模型中decoder带有一个开关,如果开关状态是打开generator,则生成一个单词;如果是关闭,decoder则生成一个原文单词位置的指针,然后拷贝到摘要中。pointer机制在解决低频词时鲁棒性比较强,因为使用了encoder中低频词的隐藏层表示作为输入,是一个上下文相关的表示,而仅仅是一个词向量。这个pointer机制和后面有一篇中的copy机制思路非常类似。
8、feats-lvt2k-2sent-ptr模型[4]
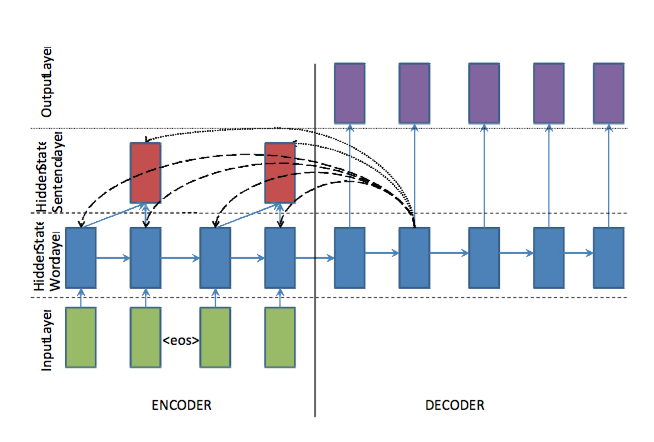
数据集中的原文一般都会很长,原文中的关键词和关键句子对于形成摘要都很重要,这个模型使用两个双向RNN来捕捉这两个层次的重要性,一个是word-level,一个是sentence-level,并且该模型在两个层次上都使用attention,权重如下:
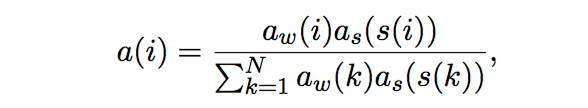
9、COPYNET[8]
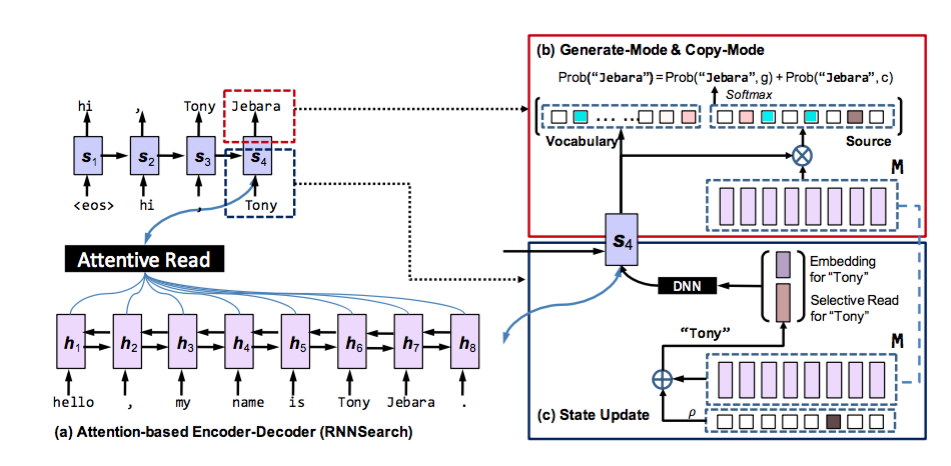
encoder采用了一个双向RNN模型,输出一个隐藏层表示的矩阵M作为decoder的输入。decoder部分与传统的Seq2Seq不同之处在于以下三部分:
- 预测 :在生成词时存在两种模式,一种是生成模式,一种是拷贝模式,生成模型是一个结合两种模式的概率模型。
- 状态更新 :用t-1时刻的预测出的词来更新t时刻的状态,COPYNET不仅仅词向量,而且使用M矩阵中特定位置的hidden state。
- 读取M :COPYNET也会选择性地读取M矩阵,来获取混合了内容和位置的信息。
这个模型与第7个模型思想非常的类似,因为很好地处理了OOV的问题,所以结果都非常好。
10、MRT+NHG[7]
这个模型的特别之处在于用了Minimum Risk Training训练数据,而不是传统的MLE(最大似然估计),将评价指标包含在优化目标内,更加直接地对评价指标做优化,得到了不错的结果。
结果
评价指标是否科学可行对于一个研究领域的研究水平有着直接的影响,目前在文本摘要任务中最常用的评价方法是ROUGE(Recall-Oriented Understudy for Gisting Evaluation)。ROUGE受到了机器翻译自动评价方法BLEU的启发,不同之处在于,采用召回率来作为指标。基本思想是将模型生成的摘要与参考摘要的n元组贡献统计量作为评判依据。
在英文数据集DUC-2004上进行评测,结果如下:
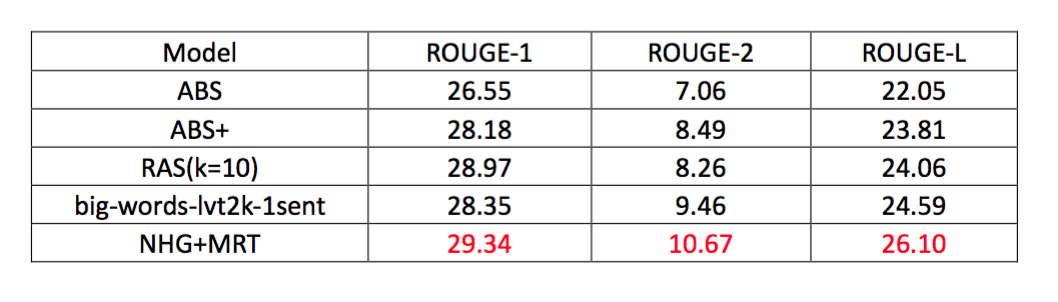
在中文数据集LCSTS上进行评测,结果如下:
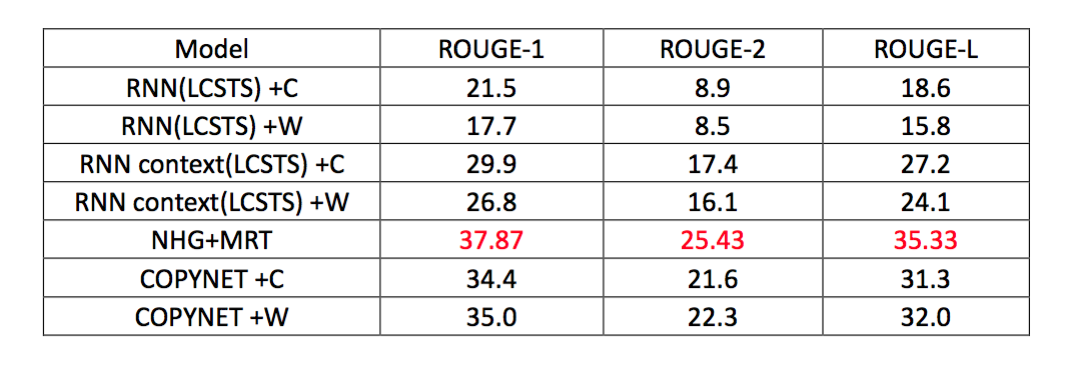
不管是中文数据集还是英文数据集上,最好的结果都是来自于模型10[7],并且该模型只是采用最普通的seq2seq+attention模型,都没有用到效果更好的copy机制或者pointer机制。
思考
自动文摘是我关注的第一个nlp领域,早期了很多相关的paper,从方方面面都有所了解,也有一些比较浅薄的想法,现在总结一下。
1、为什么MRT那篇文章的结果会比其他各种各样的模型都要好呢?因为他直接将ROUGE指标包含在了待优化的目标中,而不是与其他模型一样,采用传统的MLE来做,传统的目标评价的是你的生成质量如何,但与我们最终评价的指标ROUGE并无直接关系。所以说,换了一种优化目标,直接定位于评价指标上做优化,效果一定会很好。这点不仅仅在自动文摘中出现过,我记得在bot相关的paper中还有机器阅读理解相关的paper中都有出现,只是具体的评价指标不同而已。这一点很有启发性,如果在文章[7]中采用copy机制来解决OOV问题,会不会有更加惊人的效果呢?我们拭目以待。
2、OOV(out of vocabulary)的问题。因为文本摘要说到底,都是一个语言生成的问题,只要是涉及到生成的问题,必然会遇到OOV问题,因为不可能将所有词都放到词表中来计算概率,可行的方法是用选择topn个高频词来组成词表。文章[4]和[8]都采用了相似的思路,从input中拷贝原文到output中,而不仅仅是生成,这里需要设置一个gate来决定这个词是copy来还是generate出来。显然,增加了copy机制的模型会在很大程度上解决了OOV的问题,就会显著地提升评价结果。这种思路不仅仅在文摘问题上适用,在一切生成问题上都适用,比如bot。
3、关于评价指标的问题。一个评价指标是否科学直接影响了这个领域的发展水平,人工评价我们就不提了,只说自动评价。ROUGE指标在2003年就被Lin提出了[9],13年过去了,仍然没有一个更加合适的评价体系来代替它。ROUGE评价太过死板,只能评价出output和target之间的一些表面信息,并不涉及到语义层面上的东西,是否可以提出一种更加高层次的评价体系,从语义这个层面来评价摘要的效果。其实技术上问题不大,因为计算两个文本序列之间的相似度有无数种解决方案,有监督、无监督、半监督等等等等。很期待有一种新的体系来评价摘要效果,相信新的评价体系一定会推动自动文摘领域的发展。
4、关于数据集的问题。LCSTS数据集的构建给中文文本摘要的研究奠定了基础,将会很大程度地推动自动文摘在中文领域的发展。现在的互联网最不缺少的就是数据,大量的非结构化数据。但如何构建一个高质量的语料是一个难题,如何尽量避免用过多的人工手段来保证质量,如何用自动的方法来提升语料的质量都是难题。所以,如果能够提出一种全新的思路来构建自动文摘语料的话,将会非常有意义。
参考文献
[1] Generating News Headlines with Recurrent Neural Networks
[2] A Neural Attention Model for Abstractive Sentence Summarization
[3] Abstractive Sentence Summarization with Attentive Recurrent Neural Networks
[4] Abstractive Text Summarization using Sequence-to-sequence RNNs and Beyond
[5] AttSum: Joint Learning of Focusing and Summarization with Neural Attention
[6] LCSTS: A Large Scale Chinese Short Text Summarization Dataset
[7] Neural Headline Generation with Minimum Risk Training
[8] Incorporating Copying Mechanism in Sequence-to-Sequence Learning Training
[9] Automatic Evaluation of Summaries Using N-gram Co-Occurrence Statistics
[10] A Neural Probabilistic Language Model
工具推荐
PaperWeekly,每周会分享N篇nlp领域好玩的paper,旨在用最少的话说明白paper的贡献,欢迎大家扫码关注。

知乎专栏 paperweekly
正文到此结束
热门推荐









相关文章






Loading...
![[HBLOG]公众号](http://www.liuhaihua.cn/img/qrcode_gzh.jpg)

