网易视频云:PowerDrill论文读书笔记
网易视频云是网易倾力打造的一款基于云计算的分布式多媒体处理集群和专业音视频技术,为客户提供稳定流畅、低时延、高并发的视频直播、录制、存储、转码及点播等音视频的PASS服务。在线教育、远程医疗、娱乐秀场、在线金融等各行业及企业用户只需经过简单的开发即可打造在线音视频平台。现在,网易视频云与大家分享一下PowerDrill论文读书笔记
PowerDill是Google内部的一款BI产品, 支持交互式OLAP查询, 根据google 论文数据powerdrill性能惊人, 30~40秒内能够处理近8000亿行数据。 Powerdrill的超强处理能力得益于Google自研的列存引擎, 号称性能是普通列存的10~100倍。
PowerDrill列存引擎的主要特点:
• 列存储。 与MonetDB, Vetica等数据库类似, 按照列组织数据库。 查询只需读取所需的列, 且超强存储压缩能力强是列存的两大优势。 正因为数据量较小, 列存广泛采用全表扫表技术进行查询, 较好地支持了无法事先建索引的adhoc类查询。
• 分区。 按照多个列将表分区成差不多大小的Chunk, 查询时可检测Chunk是否符合查询条件, 跳过不必要chunk。 由于分区策略和查询性能相关性比较大, 事先考虑好查询模式,根据查询模式进行分区, 才能获得较大优化。
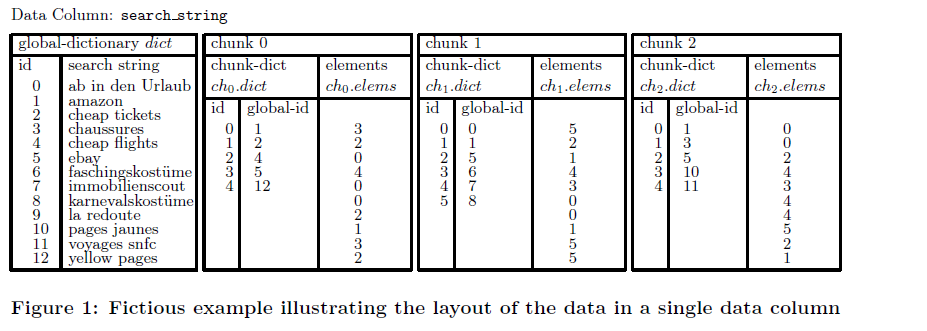
• 双字典编码。 双字典方式编码如上图所示, 表范围对列值全局编号, chunk范围对列值重新本地编号, 记录全局编号和chunk内本地编号的映射关系到全局字典。 这种编码压缩率较高, 编码后的数据量相当于普通列存压缩后的数据量。 双字典编码采用连续的整数编码列植, 单列group by查询时可采用数组替代哈希表存储中间结果, 性能提升较大, 这也是双字典编码的另外一个好处。
• 数据压缩,双字典编码之后, chunk中包含大量数值相近的正数,可压缩性仍然比较高。 PowerDrill采用的压缩技术主要有: trie压缩全局字典, snappy压缩, 用更短的位来编码列值等。 双字典编码搭配上这些压缩算法, 数据压缩比能做到50倍。
• 内存处理。在普通列存储数据库中, 扫描磁盘代价与查询执行代价相近, 所以采用磁盘扫描技术。 与它们不同, PowerDrill查询处理相比磁盘扫描更快, 所以尽量把数据Cache到内存, 用内存处理, 否则会被磁盘性能拖累。
与Google自家的Dremel类似, PowerDrilll采用树状查询执行方式, 查询尽量下推到存储(leaf node)上去执行, leaf node查询结果交给中间节点汇总, 中间节点再汇总到根节点, 根节点计算最终查询结果。 PowerDilll界面的典型操作触发20条SQL, 1000台服务器(共计4T内存的)集群中, 这些SQL在30~40秒内完成, 处理近8000亿行数据, 平均每个SQL查询2s, 这比Dremel还要快1个数量级。
可能的缺点:
• 双字典编码需要做load操作。 双字典编码需要全局编码, 所以需要针对全量数据预处理, load到数据库, 数据导入的代价比较高,数据实时性较差。
• 占资源较多。 Powerdrill需要大量的内存做计算, 成本较大, 当然powerdrill磁盘处理也不会慢, 只是会被磁盘拖累,性能优势损失很多。
• 复杂查询性能未知。 轮文中只是以3个单列group by查询作为例子, 没有提到join等复杂查询, 复杂场景下性能未知。
正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](http://www.liuhaihua.cn/img/qrcode_gzh.jpg)

