「无中生有」计算机视觉探奇 (上)

作者: 魏秀参 , 南大Lamda实验室在读博士。研究兴趣是计算机视觉和机器学习。
计算机视觉 (Computer Vision, CV) 是一门研究如何使机器“看”的科学。1963年来自MIT的Larry Roberts发表的该领域第一篇博士论文“ Machine Perception of Three-Dimensional Solids ”,标志着CV作为一门新兴人工智能方向研究的开始。在发展了50多年后的今天,我们就来聊聊最近让计算机视觉拥有「无中生有」能力的几个有趣尝试:1)超分辨率重建;2)图像着色;3)看图说话;4)人像复原;5)图像自动生成。可以看出,这五个尝试层层递进,难度和趣味程度也逐步提升。(注:本文在此只谈视觉问题,不提太过具体的技术细节,若大家对某部分感兴趣,以后再来单独写文章讨论
声明:本文为上半部分,先介绍超分辨率重建和图像着色,更多敬请期待。本文完整版可能将于近期发表在CSDN的《程序员》上,欢迎支持。
超分辨率重建 (Image Super-Resolution)
去年夏天,一款名为“ waifu 2x ”的岛国应用在动画和计算机图形学中着实火了一把。waifu 2x借助深度「卷积神经网络」(Convolutional Neural Network, CNN) 可以将图像的分辨率提升2倍,同时还能对图像降噪。简单来说,就是让计算机「无中生有」的填充一些原图中并没有的像素,从而让漫画看起来更清晰真切。大家不妨看看下图,真想童年时候看的就是如此 高清的龙珠 啊!

图一: 动画《龙珠》超分辨率重建效果。右侧为原画,左侧为waifu 2x对同帧动画超分辨率重建结果。

图二: waifu 2x超分辨率重建对比。上方为低分辨率且有噪声的动画图像,左下为直接放大的结果,右下为waifu 2x去噪和超分辨率结果。
不过需要指出的是,图像超分辨率的研究始于2009年左右,只是得力于「深度学习」的发展,waifu 2x可以做出更好的效果。在具体训练CNN时,输入图像为原分辨率,而对应的超分辨率图像则作为目标,以此构成训练的“图像对” (image pair),经过模型训练便可得到超分辨率重建模型。waifu 2x的深度网络原型基于香港中文大学汤晓欧教授团队的工作 [1] 。有趣的是,[1]中指出可以用传统方法给予深度模型以定性的解释。如下图,低分辨率图像通过CNN的卷积 (convolution) 和池化 (pooling) 操作后可以得到抽象后的特征图 (feature map)。基于低分辨率特征图,同样可以利用卷积和池化实现从低分辨率到高分辨率特征图的非线性映射 (non-linear mapping)。最后的步骤则是利用高分辨率特征图重建高分辨率图像。实际上,所述三个步骤与传统超分辨率重建方法的三个过程是一致的。
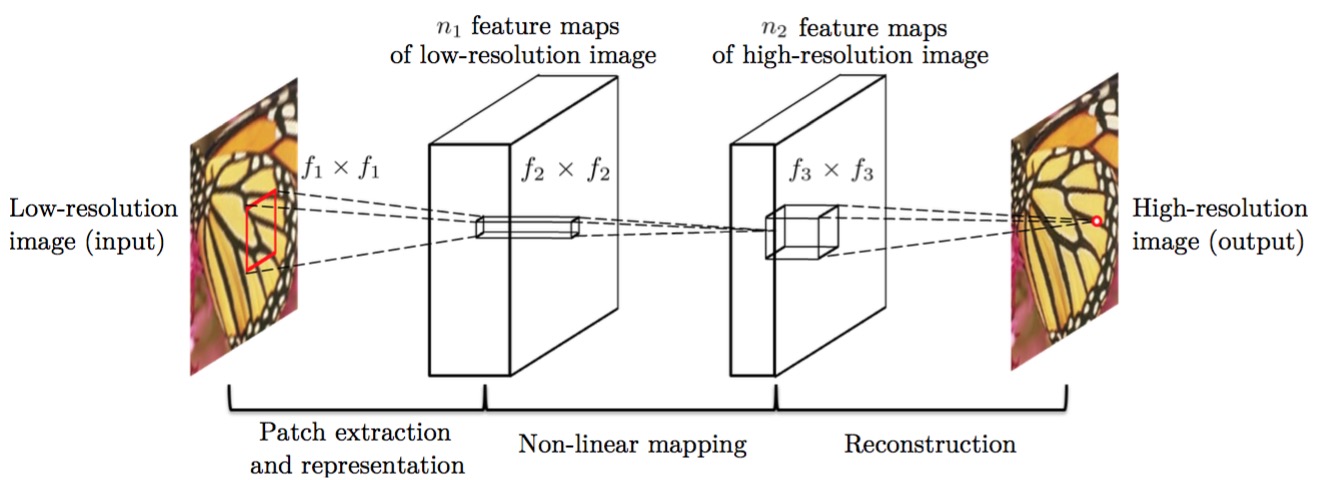
图三 文献[1]中超分辨率重建算法流程。左1为低分辨率图像(输入),左2为经过若干卷积和池化操作得到的低分辨率特征图。右2为低分辨率特征图经过非线性映射得到的高分辨率特征图,右1为高分辨率重建图像(输出)。
图像着色 (Image Colorization)
顾名思义,图像着色是将原本「没有」颜色的黑白图像进行彩色填充。图像着色同样借助卷积神经网络,输入为黑白和对应彩色图像的“图像对”,但是仅仅通过对比黑白像素和RGB像素来确定填充的颜色,效果欠佳。因为颜色填充的结果要符合我们的认知习惯,比如,把一条汪星人的毛涂成鲜绿色就会让人觉得很怪异。于是近期,早稻田大学发表在2016年计算机图形学国际顶级会议SIGGRAPH上的一项工作 [2] 就在原来深度模型的基础上,加入了「分类网络」来预先确定图像中物体的类别,以此为“依据”再做以颜色填充。下图分别是模型结构图和颜色恢复demo,其恢复效果还是颇为逼真的。另外,此类工作还可用于黑白电影的颜色恢复,操作时只需简单的将视频中逐帧拿来做着色即可。
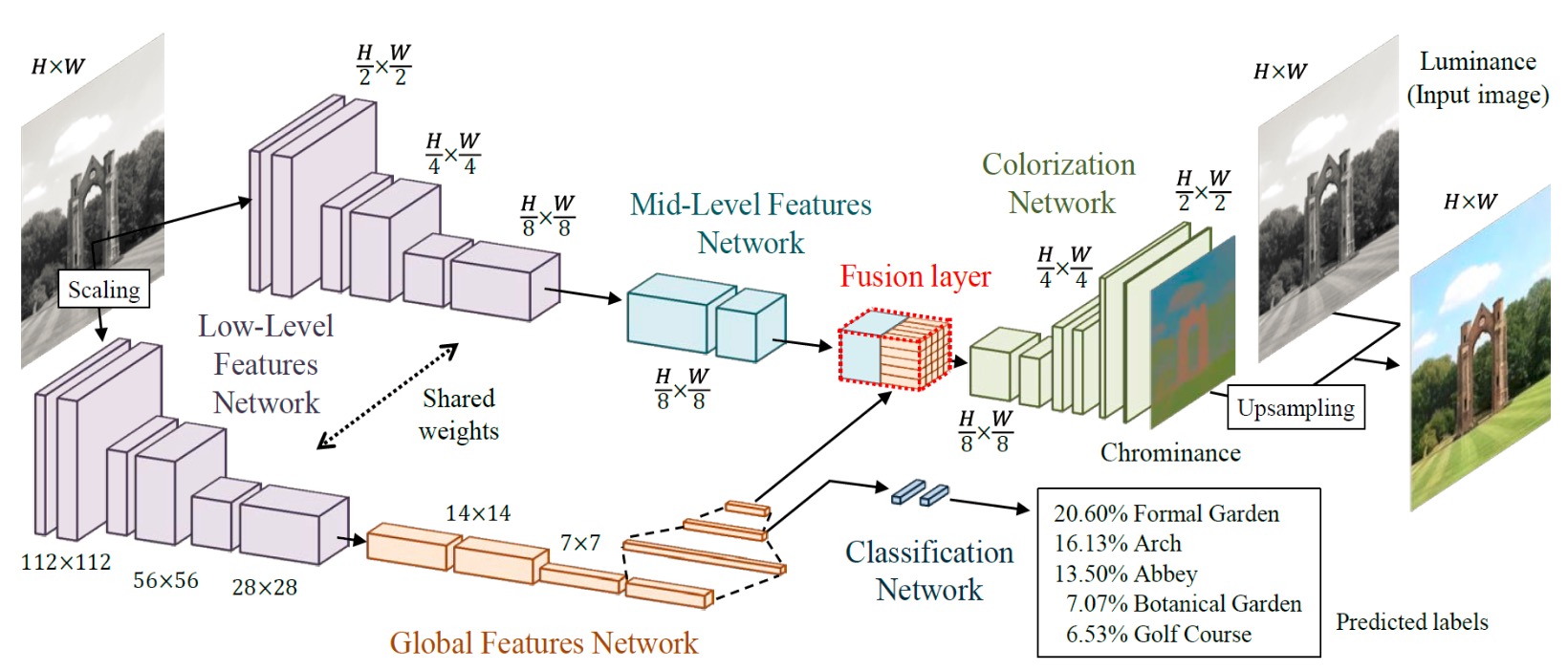
图四: 文献[2]中图像着色的深度学习网络结构。输入黑白图像后即分为两支,上侧一支用于图像着色,下侧一支用于图像分类。在图中红色部分(Fusion layer)处,两支的深度特征信息进行融合,由于包含了分类网络特征,因此可以起到“用分类结果为依据辅助图像着色”的效果。
 图五:图像着色效果示例
图五:图像着色效果示例
未完待续...
References:
[1] Chao Dong, Chen Change Loy, Kaiming He, Xiaoou Tang. Image Super-Resolution Using Deep Convolutional Networks , IEEE Transactions on Pattern Analysis and Machine Intelligence , Preprint, 2015.
[2] Satoshi Iizuka, Edgar Simo-Serra, and Hiroshi Ishikawa. Let there be Color!: Joint End-to-end Learning of Global and Local Image Priors for Automatic Image Colorization with Simultaneous Classification , In Proc. of SIGGRAPH 2016 , to appear.
[3] Qi Wu, Chunhua Shen, Lingqiao Liu, Anthony Dick, Anton van den Hengel. What value do explicit high level concepts have in vision to language problems, In Proc. of CVPR 2016 , to appear.
[4] Yağmur Güçlütürk, Umut Güçlü, Rob van Lier, Marcel A. J. van Gerven. Convolutional Sketch Inversion , arXiv:1606.03073 .
[5] Ian J. Goodfellow, Jean Pouget-Abadie, Mehdi Mirza, Bing Xu, David Warde-Farley, Sherjil Ozair, Aaron Courville, Yoshua Bengio. Generative Adversarial Nets , In Proc. of NIPS 2014.
[6] Jianwen Xie, Song-Chun Zhu, Ying Nian Wu. Synthesizing Dynamic Textures and Sounds by Spatial-Temporal Generative ConvNet , arXiv:1606.00972.
正文到此结束
热门推荐










相关文章

近期评论
-
你这基本没有更新呀,最近文章显示还是2019年的文章。不符合要求哈
-
关键词:慕云博客 链接:https://www.lilun.me 描述:分享原创文字的个人博客
-
-
-
可以提供一下源码吗
-
不是商业站,鸡娃学习笔记
-
-
-
-
听他们说很厉害的样子
Loading...
![[HBLOG]公众号](http://www.liuhaihua.cn/img/qrcode_gzh.jpg)

