GYDataCenter:高性能数据库框架
GYDataCenter 是一个 SQLite 数据库框架,提供了一套简单易用的面向对象的数据操作接口,同时保留了 SQL 查询的灵活性。GYDataCenter 简单易上手,相对于 CoreData,GYDataCenter 的学习成本更低。同时,根据自己的需求,开发者可以更方便地划分数据库,设计数据库表,数据库索引等。
概览
GYDataCenter 具有以下特性:
- 面向对象的数据操作接口
- 使用 SQLite 的 where 语句做为查询条件
- 自动创建及更新数据库表
- 高性能 cache 层
- faulting 机制(类似 Core Data)
- 自动批量写入磁盘
- 使用 ANALYZE 优化查询
使用方法
1)把 model 类继承于 GYModelObject。
@interface Employee : GYModelObject
@property (nonatomic, assign) NSInteger employeeId;
@property (nonatomic, strong) NSString *name;
@property (nonatomic, strong) NSDate *dateOfBirth;
@property (nonatomic, strong) Department *department;
@end
2)实现下面的 protocol 方法,指定数据库名,表名,指定哪个 property 做为主键(主键可以为 nil),以及哪些 property 需要持久化。
+ (NSString *)dbName {
return @"GYDataCenterTests";
}
+ (NSString *)tableName {
return @"Employee";
}
+ (NSString *)primaryKey {
return @"employeeId";
}
+ (NSArray *)persistentProperties {
static NSArray *properties = nil;
if (!properties) {
properties = @[
@"employeeId",
@"name",
@"dateOfBirth",
@"department"
];
});
return properties;
}
3)实现上面方法后,即可以存储,查询,更新数据。
Employee *employee = ...
[employee save];
employee = [Employee objectForId:@1];
NSArray *employees = [Employee objectsWhere:@"WHERE employeeId < ? ORDER BY employeeId"
arguments:@[ @10 ]];
4) 这里的查询条件使用的还是 SQL 的 where 语句,这样做有两个好处:
- 学习成本低。如果你已经熟悉 SQL 的语法,GYDataCenter 可以很快上手,你无需再学习一套新的查询语法。
- 保持了 SQL 查询的灵活性。
实际上,跟原生 SQL 一样,除了 where 语句,你也可以直接使用 order by,limit 等其它语句:
NSArray *employees = [Employee objectsWhere:@"ORDER BY employeeId"
arguments:nil];
NSArray *employees = [Employee objectsWhere:@"LIMIT 1"
arguments:nil];
甚至是内嵌查询:
NSArray *employees = [Employee objectsWhere:@"WHERE department in (SELECT departmentId from department WHERE name = ?)"
arguments:@[ @"Human Resource" ]];
特性
自动创建及更新数据库表
如上面所示,开发者只需把 model 继承于 GYModelObject,并实现必要的 protocol 方法,即可以存储,查询,更新 model 对象了。开发者无需自己创建数据库,数据库表等,GYDataCenter 会自动创建。
并且,当一个数据库表已经存在时,如果开发者添加了新的持久化的 property,GYDataCenter 也会自动更新数据库表,添加相应的 column 定义。
但是,GYDataCenter 不能 自动删除或修改已经存在的 column,如果开发者因业务变更需要这样做,开发者只能自己创建一个新表,并把数据迁移过去。
GYDataCenter 同样能自动创建及修改数据库索引,开发者只需实现下面方法。与 property 不同,已存在的索引是可以自动删除的。
+ (NSArray *)indices {
return @[
@[ @"dateOfBirth" ],
@[ @"department", @"name" ]
];
}
关系型 property 及 faulting
如上面所示,持久化 property 的类型可以是另外一个 model 类型。比如 Employee 有一个属性 department,该属性的类型为 Department 。这种属性称为 关系型 property 。对于关系型 property,必须在实现里定义为 dynamic:
@dynamic department;
对于上面的关系型 property,GYDataCenter 会在 Employee 的数据库表里添加一个 column,用于存储 department 的主键值。当调用 [employee save] 时,GYDataCenter 会把 department 的主键值存在新插入的 Employee 数据库记录里。但是 GYDataCenter 不会 把整个 department 存在 Department 表里。当开发者需要这样做时,需要显示地调用 save:
[employee save]; [employee.department save];
当开发者通过查询接口从 GYDataCenter 里拿出 Empolyee 对象时,属性 department 不会被完全赋值。属性 department 会指向一个 Department 对象,但该对象只有主键值被初始化了。当代码里第一次访问属性 department 时,department 才被完全赋值,这个过程对开发者是透明的。这个机制叫 faulting,与 Core Data 类似。
Faulting 机制避免了拿一个对象时把它所有的关系对象,以及关系对象的关系对象都拿出来。这样带来了两个好处:
- 减少内存使用。
- 提高查询性能。
高性能 cache 层
与 FMDatabaseQueue 建议的一致,GYDataCenter 对于每一个数据库(dbName 相同)的所有操作,都放在同一个队列排队执行,这样做既保证了线程安全,同时又保证了数据的一致性。实际上,GYDataCenter 底层用的正是 FMDatabaseQueue。
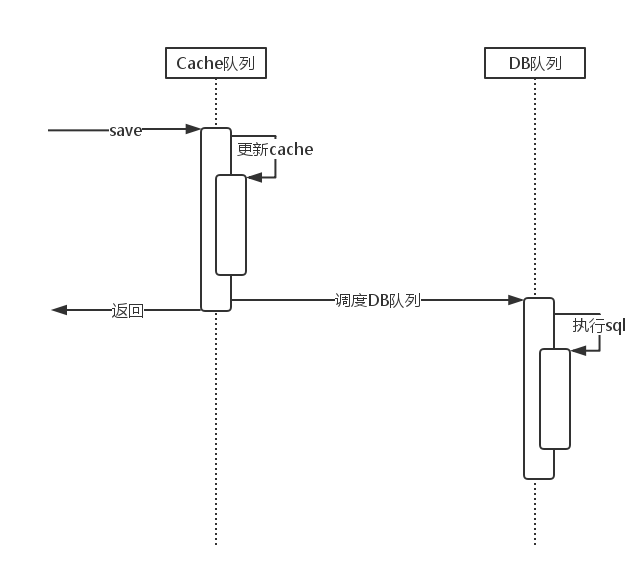
为了提高性能,GYDataCenter 还对 model 对象做了 cache,cache 以 model 对象的主键值为索引。开发者可以为每个 model 类型指定是否要 cache,以及在 memory warning 时是否要回收 cache。GYDataCenter 对于每一个数据库的所有 cache 的操作,同样也放在一个队列排队执行,具体流程如下:
1)按主键的查询操作
先到 cache 队列查询 cache 是否存在,存在则返回,不存在则同步到 DB 队列查询数据库,从 DB 队列返回后,回到 cache 队列先更新 cache,然后再返回。

2)按 where 的查询操作
先进 cache 队列,通过 cache 队列同步调起 DB 队列查询数据库,并组装对象。在组装对象时,对于每一条记录先拿出主键值到 cache 查询一下对象是否存在,如果存在则直接使用,不存在则生成新的对象,并拿出其它 column 值以初始化新生成的对象。所有对象组装完后,返回 cache 队列,更新 cache 并返回。
3)写操作
先到 cache 队列更新 cache,然后异步调起 DB 队列执行数据库操作。
自动批量写入
我们都知道,当数据库连续执行多个写操作时,可以通过事务(transaction)把多个写操作包在一起,一次性写入磁盘以提高性能。GYDataCenter 利用这点,自动地把多个 DB 操作包在一个事务中,以提高性能。
前面说过,对于同一个数据库的所有操作,都放到一个队列排队执行。由于对于同一个数据库,只有一个数据库句柄,且只有一个线程,使得自动批量写入 DB 成为可能。当数据库连接建立时,GYDataCenter 即马上开始一个事务,并且每隔一个固定的时间(默认 1 秒),GYDataCenter 就会把事务提交后再马上开始一个新的事务。
这种优化对于写操作频繁的情况特别有效,当然,对于读操作也是有帮助的。如果不手动加事务,SQLite 会为每个 SQL 的执行创建一个事务,把多个 SQL 的执行包在一个事务中,避免了创建多个事务的开销。
虽然不断地定时提交事务, GYDataCenter 仍然支持多个请求的原子操作。GYDataCenter 提供了 -inTransaction:dbName: 接口,在该接口的开始,GYDataCenter 会把定时事务提交暂停,并把上一个事务提交掉。接着,把参数 block 里的多个操作包在一个事务里,并在该接口结束时恢复定时事务提交。
ANALYZE 优化查询
ANALYZE 是 SQLite 提供的一个工具,执行 ANALYZE 命令后 SQLite 会收集数据和索引的统计信息,并将这些统计信息存于数据库文件的一个内部表里(sqlite_stat1)。这些统计数据可以帮助 SQLite 在执行 SQL 时选择更优的策略,从而提高数据库性能。
ANALYZE 命令产生的统计数据不会自动更新,随着数据库写操作的不断累积,这些统计信息会变得不准确,需要重新执行 ANALYZE 命令。根据这点,GYDataCenter 统计写操作的次数,当写操作累计达到一定次数时(默认 500),GYDataCenter 会在 app 进入后台时执行一次 ANALYZE 命令,以此优化性能。
ANALYZE 命令的执行是比较快的,在实际项目的实践中发现,ANALYZE 命令的执行时间是几十毫秒级别,因此,不必担心由于 ANALYZE 执行太慢导致 app 被系统 kill 掉。
正文到此结束
热门推荐










相关文章

近期评论
-
你这基本没有更新呀,最近文章显示还是2019年的文章。不符合要求哈
-
关键词:慕云博客 链接:https://www.lilun.me 描述:分享原创文字的个人博客
-
-
-
可以提供一下源码吗
-
不是商业站,鸡娃学习笔记
-
-
-
-
听他们说很厉害的样子
Loading...
![[HBLOG]公众号](http://www.liuhaihua.cn/img/qrcode_gzh.jpg)

