文件系统fsck提速方案
朱颖航(个人微信号:casualfisher),北京灵犀智造科技有限公司(www.linkedsee.com)技术总监,设计参与了百度智能数据中心项目,集中在智能供电方向, 负责了硬件感知项目,参与设计服务器硬件采集及管理工具, 并基于采集数据进行故障及使用趋势预测,曾设计和开发重复数据删除文件系统, 参与多个存储相关的开源项目(mhvtl, zfs on linux等)
在分布式文件系统(例如HDFS)中,当出现异常掉电、加电恢复后,通常存储系统会检测内部数据的一致性,检测分为两个层次
- 首先是单机文件系统的数据一致性检查
- 其次是使用了erasure coding编码的存储系统进行数据一致性校验
必要时进行根据erasure coding进行数据恢复。
根据阿姆达尔定律,存储系统恢复的整体时间由串行部分最慢的节点决定。
在 ec 恢复的过程中,通常是多个节点,多个设备之间并行恢复,系统的瓶颈通常受限于第一阶段本地文件系统的 fsck 过程。
在类 HDFS 中,通常使用 SATA 硬盘存储数据,SATA 硬盘的磁盘容量随着新的SMR、HAMR技术的出现而越来越大,而传输的速率目前受限于 SATA3.0定义的最大速率(6Gb/s,实际使用中通常顺序读稳定在 100-150MB/s 之间),因此提升文件系统的fsck速度就显得愈发重要,本文中以 ext4 文件系统为例,列举除了文件系统 fsck 提速的若干方案。
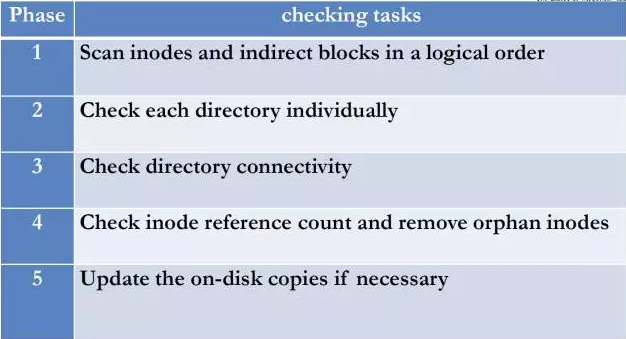
方法1:优化文件系统及 fsck 本身
Ted 在 e2fsprogs版本1.41.9中已经完成了针对 ext4 的 fsck 优化工作,而公司目前线上的 fsck 版本为 1.41.12 ,已经加入了这个优化。
从优化fs check本身考虑,《ffsck: The Fast File System Checker》中提出了对于ext3磁盘数据格式进行修改,在每个block group内部加入专为元数据存储的空间,以优化fsck中磁盘对于元数据的随机寻址(e2fsck中 phase1/扫描文件间接索引占据了总时间的90%以上),进而提高性能,由于需要修改磁盘上数据存储的格式,所以此方法不可行。
思路:
建议如果需要优化fscheck本身,下一步可以考虑和应用类型结合起来进行(例如找到应用关心的文件进行检查,不关心的直接跳过,对于hadoop hdfs之类的数据存储,目录和文件均有用,因此此方法不适合),并且在mkfs的时候,使用bigalloc和inline data的功能,大文件保证其连续性,减少元数据存储量,小文件可以直接合并入 inode,减少 seek 的程度,不过这种方案并未从根本上解决问题,随着文件系统碎片的增加,可能抵消掉带来的性能提升。
方法2: online fsck
ZFS,BTRFS 等由于采用了 COW 机制,对写入磁盘的数据不会再进行修改,保证存盘数据的稳定性,在恢复之后可以立即对外提供服务,将对断电时刻的数据检查作为一个优先级较低的操作(ZFS为scrub操作),可以和文件系统的正常操作并行执行,一旦有正常的读写等操作,将会停止 fsck 过程,减少对于应用性能的影响。
由于数据库等系统需要尽可能的在线提供服务,所以我们希望能够尽可能的缩短宕机后的启动时间。所以,如果可以实现 online fsck 的功能,则可以尽可能的缩短系统启动的时间,同时保证文件系统不被破坏。
目前已知的可以进行online fsck的文件系统是 zfs, ffs, btrfs。
Ted 给出的建议是可以考虑在分配磁盘块的时候在相应的 block group 上添加相应的标记,表明这个block group 正在进行磁盘块的分配,在出现宕机后,这个 block group 的数据只进行读操作,所有写操作都会被映射到其他的 block group中。这样可以尽可能的保证文件系统的一致性(来自ext4 workshop总结)。
鉴于kernel mainline已经明确表明不会接受ext4 snapshot的 patch,所以基于 fs 的 snapshot 进行 online fsck无法进行,可以尝试结合比较成熟的 lvm 快照为 fsck 提速。
Andreas的回复: *
When you write about online e2fsck, what do you mean exactly? It is already possible
with LVM to create a read-only snapshot of a device and run read-only e2fsck. This
works because the LVM snapshot is hooked to ext4 to freeze the filesystem and flush
the journal before the snapshot is done.
Ext4 snapshots vs lvm snapshots
*
如何在已有的分区上创建lvm卷组
思路:
遇到宕机/掉电导致的 fsck 时间过长时,将已有的分区转换为 lvm 分区,然后在lvm快照的基础上进行 online fsck,此时文件系统可以挂载供应用读取(读写未出错的文件)。 优势:从根本上免除了 fsck 带来带来的时延。
劣势/待解决问题
- fsck 完成后如何清除 lvm 返回到raw partition的状态
- 是否可以控制不使用第二块盘进行重定向(提前保留部分空间)
- 了解到目前这种lvm online fsck启动后会对应用的性能产生较大的影响,因此建议使用文件系统内置的online fsck功能。
方法3:跳过fsck步骤
google 内部使用 ext4 时采用了no journal的挂载选项,说明在宕机、断电过程后并不进行 fsck,而是通过上层应用对于数据的冗余保证数据的一致性。
思路:
如果上层是 HDFS 之类的分布式文件系统,可以考虑这种思路,但需要注意到副本在同一个机房内,机房断电的情况。
针对以上的思路涉及如下实验验证:
测试:
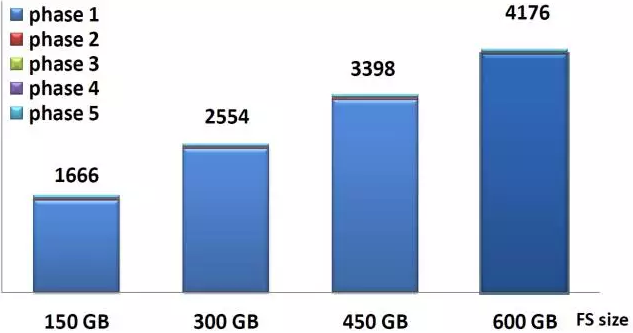
测试环境:ST4000NM0053-1C1 2TB的硬盘+hadoop hdfs 写入 1.3TB 数据(共个 38949 文件,331 个目录)
- 测试1:内核版本 3.10.16 (支持bigalloc+inline_data)+打了 bigalloc 支持补丁的 e2fsprogs 测试(fsck工具不支持inline_data,会 crash),mkfs 选项:mke2fs -m 0 -C 1MB -I 4096 -O bigalloc $device
- 测试2: 2.6.32内核+ e2fsprogs 工具(版本 1.41.12 )mkfs选项:mkfs.ext4 -F -m 0 -b 4096 -Tlargefile (实际环境中 mkfs 选项),测试中fsck参数均为-f -y
结果:测试1 fsck 3次平均时间12s。测试2 fsck 3次平均时间40s。
从测试结果可见, 如果不能使用方法3中上层屏蔽fsck或者方法2中使用lvm及COW文件系统的情况下,切换到使用了bigalloc和inline data的新版内核为比较稳妥的解决方案 。
正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](http://www.liuhaihua.cn/img/qrcode_gzh.jpg)

