Dropbox的神奇口袋:Dropbox架构详析第二篇
原文: Inside the Magic Pocket
作者:James Cowling,在MIT就读PhD时师从图灵奖得主Barbara Liskov
翻译:孙薇
自从内部使用、扩展至EB级别的存储系统 “Magic Pocket”发布 之后,我们收到了很多正面反馈。我们会继续跟进Magic Pocket,陆续发布一系列技术博文,从各种有趣的角度来观察这个系统,包括我们的保护机制、操作工具以及软件与硬件之间的方法创新。不过首先,我们需要了解一些背景:在本文中,我们会从宏观角度对Magic Pocket的架构以及设计标准做以概览。
在之前的序篇中我们解释过(注:上篇的翻译请 点击这里查看 ),Dropbox存储两类数据:文件内容与文件/用户的元数据。Magic Pocket是我们用来存储文件内容的系统,这些文件被分成块状存储,并存有副本以保证持久化,它们分布在整个系统中的多个物理位置上。
虽然Magic Pocket的基础是相当简单的核心协议组,但它本身仍是庞大而复杂的系统,因此我们需要略过一些细节。欢迎反馈,我们会在后续文章中尽量深入探究。
引用
注:在Dropbox内部,这个系统也被称为“MP”,这样我们就不用因为老提起“神奇(Magic)”这个词而感觉傻乎乎的了,本文中我们也会用MP来代指这个系统。
需求 不可变的数据块存储MP是一个具有不变性的数据块存储系统,其中存储了多达4MB的加密块区文件,某个数据块一旦写入系统就不会再发生变化。不变性让一切简单得多。
当用户在Dropbox上对文件作出变更时,我们会在另一个单独的系统中(FileJournal)记录下所有的变更。这样一来,通过将支持易变性的逻辑转移到堆栈的更高层级,就能简单地存储不变的数据块了。许多大规模的存储系统都对可变数据块提供内部支持,但在较低层级中一般都是基于不可变的存储基元。
工作负载Dropbox有很多数据,并具有高度的时间局部性(temporal locality)。许多数据在上传后一个小时之内会有频繁的访问量,而随着时间流逝,访问频率也会越来越低。这种模式合乎情理:Dropbox的用户有大量的协作任务,因此文件上传后很可能需要同步到其它设备上。但我们仍需要可靠的快速访问:也许从1997年开始你就没怎么看过税务记录了,但在需要的时候,你会想要立即看到。我们有一个相当“冷”的存储系统,但需要以低延迟快速访问所有数据区域。
为了处理这种工作负载,我们在构建系统时用到了硬盘驱动,由于硬盘具有持久、价廉、存储密集、延迟较低等优势,我们使用了SSD盘来保存数据库以及缓存内容。对于新近上传的内容,我们使用了高度的初始复制与缓存技术;而对于其余的数据,我们使用了更为高效的存储编码技术。
持久性在MP中,持久性是必备的。理论上,我们要求系统的持久性能保持到地老天荒,除非小行星导致天灾——我们有更重要的事情要操心,不能因为随机的磁盘故障就出现数据损毁的问题。这些数据以效率更高的纠删码(erasure-coded)形式存储,同时还使用了跨区(地理位置)高度复制以保障在灾难或自然灾害发生时数据的安全性。
规模对工程师来说,这个部分非常有趣,MP必须在差不多半年的时间里,从初始数十PB的原型成长到EB级别的庞然大物,这可真是空前的转变。因此,我们需要花费大量时间来思考、设计、构建原型,以克服能预见到的瓶颈问题。在这个过程中,我们也确认了这个架构完全可以扩展,因此在出现不可预知的需求时,也能进行相应的修改。
关于不可预知的需求,其实有很多例子:比如流量突然增长,网络集群间的路由器工作负载逐渐饱和。因此,我们需要修改数据存放的算法以及路径请求,以便更好地反映集群间的关联(以及可用存储量、集群成长计划等),并最终为集群间的网络架构带来改变。
简单性是个工程师都知道,复杂性通常会导致不可靠性。有很多人在花费大量时间编写复杂的一致性协议后发现:在Paxos算法的重实现上浪费一整天可不是什么好主意。MP尽可能避免了quorum一致或分布式协作的情况,并在使用容错及可伸缩方式时大量利用集中的协作点。有时在数据块索引(Block Index)中,我们可以选择分布式哈希表或trie树,而不仅是巨大的分片MySQL集群。这一决策在简化开发与减少未知因素方面表现非常优秀。
数据模型在讨论架构自身之前,我们先来研究一下所存储的内容。
在Dropbox的MP系统中,存储的是最大4MB的文件数据块:

经过压缩加密后,这些数据块(block)被发送到MP中进行存储,每个数据块都需要一个键值或者名称,大多情况下我们会使用SHA-256哈希。
然而在EB级别的存储系统中,4MB的数据量犹如沧海一粟,如果需要替换磁盘或者对某些数据使用纠删码技术,这个大小就显得太小了。为了简化这个问题,我们将这些数据块整合成1GB大小的逻辑存储容器,称为bucket。指定bucket中的数据块无需有什么相同的特性,只是上传的时间差不多相同。
为了保证可靠性,我们需要将这些bucket复制到多台物理机器上,新近上传的数据块可直接复制到多台机器上。最终系统会将包含数据块的bucket整合到一起,再通过纠删码技术提高存储的效率。我们使用volume来指代复制到一系列物理存储节点的一个或多个bucket。
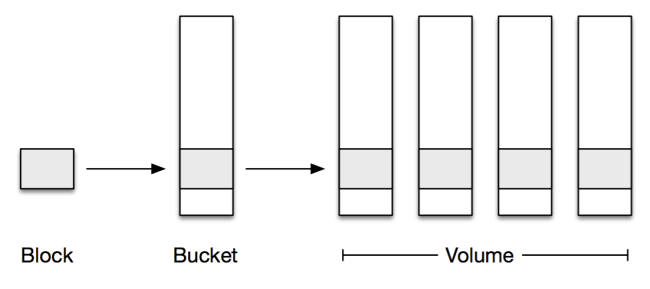
总结一下:数据块可通过哈希进行识别,并且要写入bucket中。每个bucket都存储在volume中,volume分布在多台机器上,这些bucket或是复制的,或是纠删码形式的。
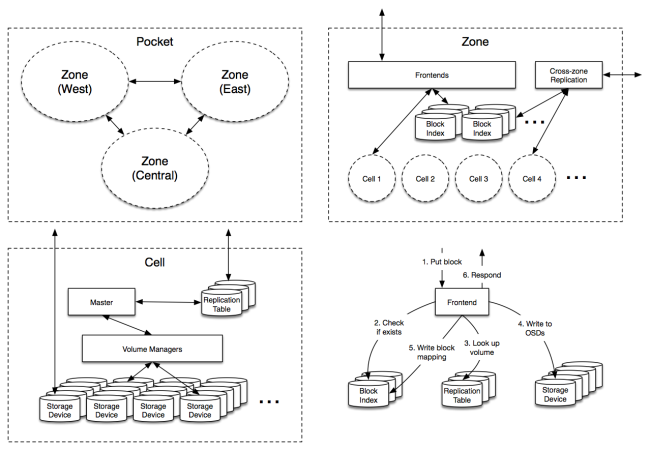
架构那么现在我们了解了自身需求与数据模型,实际中MP又到底是什么样子呢?其实有些类似下图这样:
下面我们对上图的组件一一进行讲解。
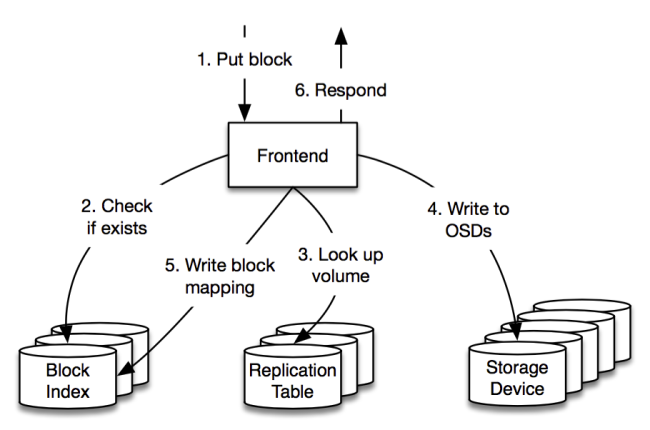
前端(Frontends)这些节点负责从系统外部接收存储请求,它们是MP的网关,负责确认某个数据块应当存储在什么地方,并在MP内部发布读取/写入数据块的命令。
数据块索引(Block Index)
这项服务将每个数据块映射到相应的存储bucket中,我们可以将其视为如下结构的大型数据库:
hash → cell, bucket, checksum其真实结构要比上面的简化版稍微复杂些,还需要支持类似删除、跨区复制等操作。
数据块索引是一个巨大的分片MySQL集群,以RPC服务层为前端,再加上许多操作数据库和确保数据库可靠性的工具。起初我们计划建立一个专门的键值存储库,不过MySQL完全能胜任这一职责。我们已有数以千计跨Dropbox堆栈的数据库节点可提供服务,因此也能规模化地管理MySQL。
最终建立的系统可能略有些复杂,不过到目前为止我们都很满意。键值存储方式十分流行,性能表现优秀,但数据库有着高度的可靠性,所提供的数据模型让我们今后能容易地对结构和功能进行扩展。
跨区复制(Cross-zone replication)跨区复制的后台程序负责异步执行操作,将一个区的所有数据块复制到另一个区中。在数据上传后一秒之内,系统就会将各个数据块写入远程区域。我们将这种复制延迟作为持久性模型的一部分,并确保在本地区域内对数据进行了足够广泛的复制。
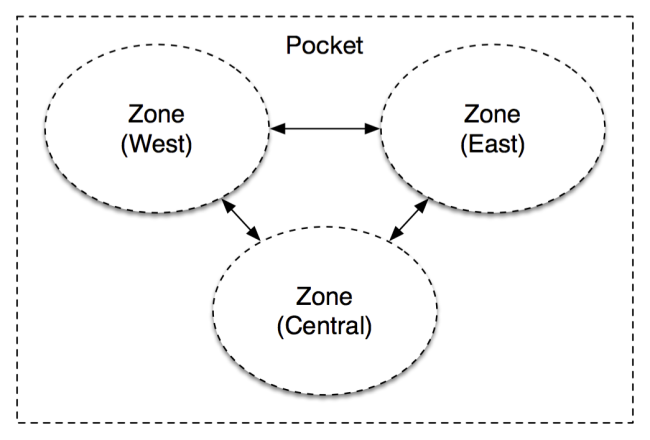
单元(Cells)每个单元都是独立的逻辑存储集群,存储着约50PB的原始数据。一般我们想给MP增加容量时,就会添加新的单元。由于各单元在逻辑上完全独立,各个单元分布在各个机架上,以确保每个单元的物理多样性最大化。
下面我们来深入探究一下其工作原理:
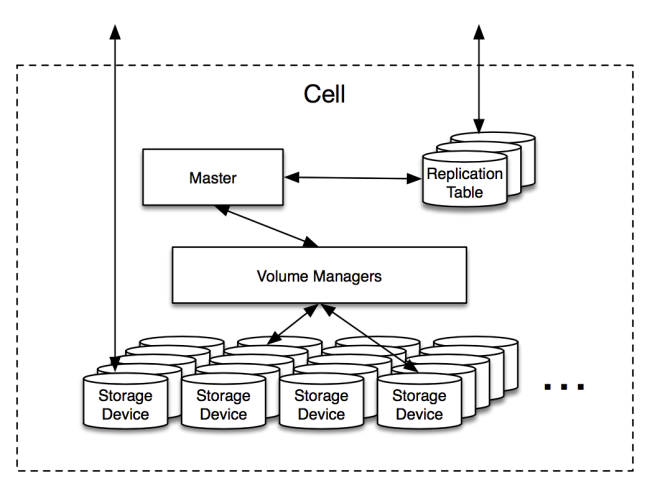
单元中最重要的角色就是OSD,整个磁盘上都是这种可以在单台机器上存储超过1PB数据、在各机架上存储超过8PB数据的存储容器。在这些设备上,缓存管理、负责磁盘调度与数据验证都有一些非常复杂的逻辑,不过从系统其他设备的角度来看,这些都属于“傻瓜”节点:它们存储数据块,但并不了解单元拓扑结构,也不参与分布式协议。
复制表(Replication Table)复制表是单元的索引,从数据的每个逻辑bucket映射到该bucket所存储的volume与OSD上。与数据块索引类似,复制表是作为MySQL数据库存储的,但比MySQL数据库要小得多,更新也远没那么频繁。复制表的工作集完全适用于这些数据库中的存储,赋予我们对少量物理机器的高读取吞吐能力。
复制表的模式就像下面这样:
bucket → volume volume → OSDs, open, type, generation
这里有一个重要的概念就是open flag,指示着volume是“打开”还是“关闭”,开启的volume只在要写入新数据时打开,而关闭的volume则是保持不变的,可以在单元间安全移动。只有很少一些volume会在任何时候都保持开启。
类型(type)指定了volume的类型:是复制的volume,还是以某种纠删码形式编译的volume。生成(generation)序号则用于确保在从磁盘故障中恢复或优化存储布局时,能确保移动的volume一致。
MasterMaster被认定是最适合单元的管理或协调程序,包含系统中大部分复杂的协议逻辑,主要任务就是监控OSD,并在出现错误时触发数据修复操作。同时,Master也负责协调类似创建新存储bucket这样的后台操作,在删除数据时触发垃圾回收操作,或者在垃圾回收过后,bucket过小时对其进行合并的操作。
复制表存储了volume状态,因此Master自身是完全soft-state的。注意:Master并不在数据层面中,其中并没有实时的流量,如果Master宕掉的话,单元是可以继续负责读取的。单元甚至可以在没有Master的情况下接收写入的操作,尽管最终会由于缺乏Master产生的新内容,而导致可用存储bucket耗尽的情况。如果Master没有时间创建新的bucket,总会有许多其他的单元可以支持写入操作。
逐单元运行单独的Master,能够为复杂的数据分布决策提供集中式的协调方案,并且不会因分布式协议而导致情况太过复杂。这种集中式的模式确实导致每个单元的大小受限:在内存与CPU开销达到瓶颈前,可以支持的容量只有大约100PB。幸好,从部署角度来看拥有多个单元也是非常方便的,可以提供更大的隔离性以避免级联故障。
volume管理器volume管理器负责单元的重型搬运工作,根据Master发回的请求来移动volume,或者对volume执行纠删。这通常意味着系统要读取一大堆的OSD,向其他OSD写入,再将控制权交回给Master以完成操作。
volume管理器进程运行在与OSD相同的物理硬件上,这样可以让单元中闲置的存储硬件分担其繁重的网络容量需求。
协议到这里,希望大家对较高层面的MP架构有了合理的了解。我们会对一些核心MP协议做个粗略的概览,并在今后的系列文中再进行详细的阐述。不过,幸好这些协议已经非常简单了。
Put在接收Put请求前,前端便存有一些信息:它们定期与每个单元联系,以确认其中有多少可用空间,并包含能够接受新写入请求的open volume列表。
当收到Put请求时,前端会(通过数据块索引)首先检查数据块是否存在,然后选择存储数据块的目标volume。volume的选择方式如下:将单元负载均匀分担,使得存储集群之间的网络流量降到最低。然后前端会询问复制表,以确定目前存储在volume中的OSD。
前端向这些OSD发出存储命令,而OSD在响应前会fsync所有数据块到磁盘上(或者随身SSD上)。如果成功的话,前端会向数据块索引增加新的条目,并向客户端返回成功信息。如果有OSD出错,那么前端会尝试其他volume(可能在另一个单元中)。如果数据库索引出错,那么前端会将请求转发到另一个区域。Master会定期运行后台任务,清理出错操作部分写入的内容。
虽然这里有一些细节问题,最终还是相当简单的。如果采用仅需前端在volume中写入OSD一个子集的那种基于quorum的协议,我们就能避免一些重试的问题,并有可能实现低尾延迟,但会以增加复杂性为代价。在基于重试的方案中,系统对超时进行合理的管理便已实现了低尾延迟,性能也很让人满意。
Get一旦我们知道了Put协议,Get的过程就不言自明了。前端会从数据块索引中查找单元与bucket,然后从复制表中查看volume与OSD,再之后从某个OSD中获取数据块,并在出现故障时进行重试。
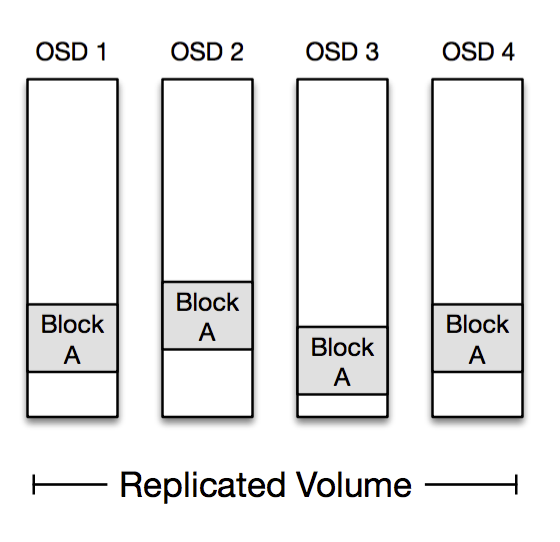
如前所述,我们在MP中存储了复制数据与纠删码数据。由于volume中的每个OSD都存储了所有数据块,从复制volume中读取数据非常简单。
从纠删码volume中读取数据可能有些复杂,根据编码的方式,每个数据块我们都能从单个指定OSD中整体读取,因此大多读取请求都只会涉及单个磁盘,这极大地降低了我们硬盘的负载。如果OSD不可用,那么前端需要通过从其他OSD中读取编码数据,来重建数据块。volume管理器会在重建方面提供协助。
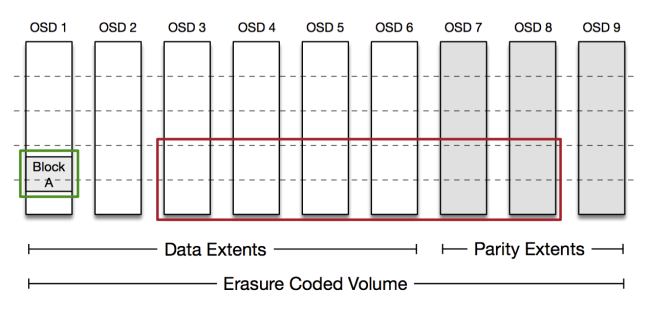
在上述的编码结构中,前端可以从OSD1读取Block A(以绿色圈出)。如果读取失败,系统会从其他OSD中读取足够数量的数据块,用以重建Block A(以红色圈出)。实际中编码要更复杂一些,并且经过了优化——在大多数故障情况下,会从更小的OSD子集中进行重建。
修复Master运行着一些不同的协议,来管理单元中的volume,并在操作出错时执行清理,但Master所执行的最重要操作是修复。
修复是用来在磁盘出错时重新复制volume的操作,Master会继续通过我们的服务探测系统监控OSD的健康性,并在OSD离线15分钟之后触发修复操作——这个时间足以在不触发不必要修复的情况下重启一个节点了,但却不足以执行快速恢复并让任何有漏洞的窗口最小化。
在一个单元中,volume的分布是比较随机的,每个OSD包括几千个volume。这代表着如果我们失去了单个OSD,是可以同时通过其它数百个OSD来重建整套volume的:

在上图中我们失去了OSD3,但可以通过OSD 1、2、4、5来恢复volume A,volume B以及volume C。在实践中,每个OSD有几千个volume,它们与其它数百个OSD共享数据。这样我们就能通过数百个网卡和数千个碟盘来分担重建的流量,使得恢复时间减到最低。
当OSD出错时,Master首先会关闭OSD上的所有volume,并命令其它OSD在本地反映出这一变化。现在volume关闭,我们知道它们不会再接受写入操作,因此可以安全地移动。
然后Master创建了重建计划,选择一组OSD作为复制源头,另一组作为复制目标,通过这样的方式将负载分布到尽可能多的OSD上。这一步可以避免在特定磁盘或机器上出现流量峰值。重建计划让我们在每个OSD硬件配置上的花费减到最低,不过若没有将Master作为协调的中心点的话,将很难产生。
我们会让数据传输进程尽可能平滑,不过其中的volume管理器要负责将数据从源头复制到目标,在必要时进行纠删,然后将控制权返给Master。
最后的步骤相对简单一些,但却很重要:此刻在源与目标OSD上都存在有volume,但尚未执行移动。如果Master此时出错,volume会存在原来的位置,等待新的Master来修复。为了完成修复操作,Master首先要修改新OSD上的volume生成序号,然后更新复制表以便在新生成时(提交点)存储新的volume-OSD映像。现在随着生成序号递增,我们知道哪个volume在哪个OSD里,这一点将不会产生混淆,即便出错的OSD恢复了活动。
这个协议确保任何时候在任何节点出错时,都不会导致系统出现不一致的状态。在生产环境中我们见过各种类型的案例,其中一例中,数据库前端停滞了整整一个小时,之后恢复并向复制表转发请求,期间Master也出错并重启,发出了一套完全不同的修复操作,我们的一致性协议需要在面对这类故障时也完全可靠。Master还运行着很多其他的后台进程,比如Reconcile进程,它会确认OSD状态,并回滚出错的修复进程或者未完成的操作。
开放或闭合的volume模型是确保实时流量不会干扰后台操作的关键,让我们得以使用更为简单的一致性协议。
封装感谢阅读本文,希望能让大家对MP的工作原理以及我们的一些设计动机有些了解。
这里主要的设计原则在于保持简单性!设计分布式存储系统是很大的挑战,不过构建一个能够大规模执行可靠操作的分布式存储系统/支持所有监控与验证系统还有工具,确保其正常运行更是困难得多。为对的问题给出正确的解决方案,在进行技术决策方面也有着非同寻常的重要性。MP大部分都是由一支不足6人的团队完成构建的,这要求我们将精力放在重要的事情上,所有人都要在项目成功上起到重要的作用。
很明显有很多细节本文没有提及,有些问题可能尚未涉及,不过我们已经在考虑这些问题了。在今后的博文中,我们会就大规模构建与运行系统的细节问题进行更细致的讨论,敬请期待。
正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](http://www.liuhaihua.cn/img/qrcode_gzh.jpg)

