web实战开发–百万级爬虫服务架构的总体设计
前言:
之前写过一个 分布式爬虫服务 , 虽然定位在 日爬取页面百万级 , 规模和难度并不大, 但对于很多 资讯收集站点 而言, 有个这个爬虫系统后, 可以说是如虎添翼. 这也是我所认可的这个 服务的价值所在 .
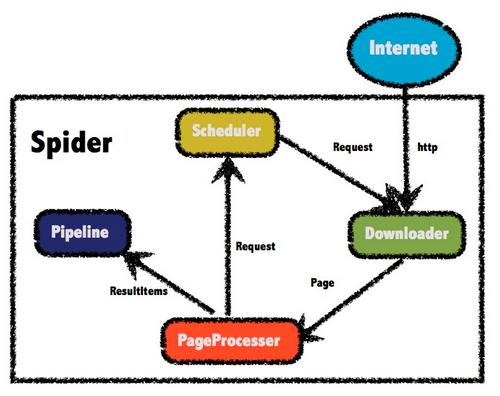 本文将讲述下, 我这个 分布式爬虫服务的架构, 以及如何工作, 写得简陋, 权当抛砖引玉耳.
本文将讲述下, 我这个 分布式爬虫服务的架构, 以及如何工作, 写得简陋, 权当抛砖引玉耳.
概念之争:
首先谈下, 框架Vs服务 , 这两者的区别. 因为之前也有人问我, scrapy爬虫框架和我的服务有什么区别? 我是不是重复造了轮子? 下面先简答解答一下.
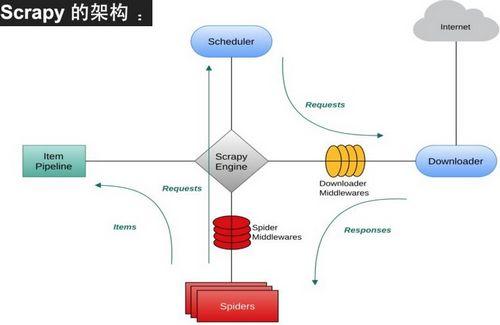 框架: 抽象了网页爬取和网页信息提取, 大大简化了程序员的编写难度, 但是另一方面, 它是单机的, 框架离分布式, 集群化管理还有一定的距离 .
框架: 抽象了网页爬取和网页信息提取, 大大简化了程序员的编写难度, 但是另一方面, 它是单机的, 框架离分布式, 集群化管理还有一定的距离 .
服务:面向的是普通运营人员(非程序员), 只要编写简单的规则, 即可定义一个爬虫任务, 由架构决定, 其是分布式管理.
由此可见, 以汽车为例, 框架相当于汽车零件, 需要专业的技术人员才能打理, 而服务则是整车, 只需有驾照, 就能行驶.
应用场景:
有很多资讯站点, 其文章来源于各大平台, 和各类有特色的先站点. 如果站点运营人员手动去收集, 费时费力, 效果也不见得佳. 一来站点来源多, 二来手动收集文章效率低 .
针对这种情况, 爬虫服务就应运而生. 当然由于信息采集, 是基于模板, 而各个来源网站模本不一. 因此通用爬虫的思路, 必然走不通.
因此 定制爬虫的思 路, 就浮上水面, 另一方面, 抽象爬虫的规则, 使得运营人员绕开代码编写.
思路:
由于是面向资讯站点(博客, 新闻等), 单个网站(板块)其页面模板是相对固定的, 而且有规律可循.
我们简单的把网站页面, 分为两大类, 1. 导航型页面, 2. 内容型页面.
导航型页面, 主要提取文章链接, 而页面型内容, 就是所谓的文章页.
通过对url规则进行提取, 依据 正则表达式 , 还是能区分这两类页面的.
内容提取时, 则依据页面模板, 圈定正文, 标题, 时间等信息. 技术的方案选择, 相对比较容易, 无论是jsoup, 还是xpath, 都是大利器 .

基础架构:
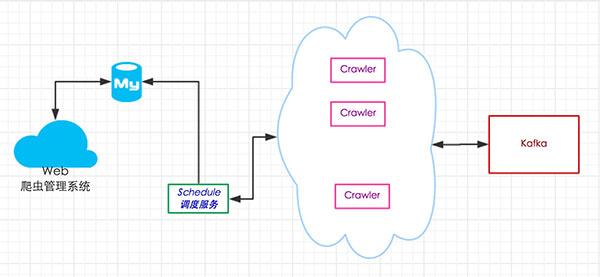 webapp 用于爬虫规则管理(增删改查), 和爬虫进度和调度的查看.
webapp 用于爬虫规则管理(增删改查), 和爬虫进度和调度的查看.
调度节点, 则用于分配爬虫任务.
爬虫节点, 具体执行爬虫任务的节点.
kafka(开源), 分布式队列服务, 用于存放爬取到的网页信息, 借助topic订阅模式, 方便系统耦合.
如何工作:
爬虫节点, 从调度节点中获取爬虫任务, 然后就单点执行该爬虫任务. 一个爬虫节点, 可以设定多个爬虫任务, 其内部采用java并发的 ScheduleExecutorService , 设定有限的线程池, 按时间事件驱动来运行 , 因此爬虫节点的负载和爬虫任务的个数, 并非成正比.
调度任务是, 是排他性的, 任务只允许一个爬虫节点执行. 其采用mysql的for update的锁机制, 来实现任务竞争和锁定的.
爬取频率控制, 每个站点, 基本上每隔一段时间才爬取一次页面.
当前不足:
当然该爬虫服务, 也有相当的不足.
1. 缺少failover机制, 当爬虫节点宕机时, 爬虫任务就不能恢复了, 从而导致当天的数据丢失.
2. 缺少ip地址池, 很容易被网站管理人员加入黑名单.
3. 对于特大站点, 并不适用, 因为限制了爬虫频率.
总结:
就资讯类聚合站点而言, 该爬虫服务, 显然是一大帮助. 它可以设定管理多个爬虫规则, 另一方面, 规则任务可以获取页面数也相当可观.
同时引入topic的概念, 方便服务对网页数据做分类处理.
架构这东西, 没有完美的, 只是合适自己的,对于该爬虫服务的架构设计, 以及使用场景的认知, 我个人还是相当的满意.
正文到此结束
热门推荐










相关文章

近期评论
-
你这基本没有更新呀,最近文章显示还是2019年的文章。不符合要求哈
-
关键词:慕云博客 链接:https://www.lilun.me 描述:分享原创文字的个人博客
-
-
-
可以提供一下源码吗
-
不是商业站,鸡娃学习笔记
-
-
-
-
听他们说很厉害的样子
Loading...
![[HBLOG]公众号](http://www.liuhaihua.cn/img/qrcode_gzh.jpg)

